
실습 데이터: 캐글 타이타닉 데이터
데이터 인코딩
사이킷런의 머신러닝 모델은 일반적으로 문자열 값을 인식하지 못합니다.
따라서 모든 문자열 값은 숫자형으로 변환하는 과정이 필요합니다.
문자열 변수는 일반적으로 카테고리형(범주형), 텍스트형으로 나눠지는데요.
① 텍스트형은 feature vectorization 등의 기법으로 벡터화하거나 불필요하다고 판단되면 삭제하는 게 좋습니다.
예를 들어, 일련번호(ex: 1, 2, 3, ...)를 나타내는 컬럼의 경우 인코딩하지 않고 삭제하는 게 더 좋습니다. 일련번호는 단순히 데이터 행을 구분하는 용도로 사용되기 때문에 예측에 필요한 요소가 아닐 뿐더러 오히려 예측 성능을 떨어뜨리기 때문입니다.
② 카테고리형에는 다음과 같은 2가지 인코딩 방법을 적용할 수 있습니다.
- Label encoding
- One-Hot encoding
✅ 라벨인코딩(Label encoding)
라벨인코딩은 문자열로 된 범주형 변수를 코드형 숫자 값으로 변환하는 것입니다.
타이타닉 데이터에서 'Embarked' 변수의 구분이 C, Q, S로 되어 있습니다. (단, 결측치는 이미 앞단계에서 처리한 걸로 간주합니다.)
라벨인코딩은 이 3가지 범주값을 0, 1, 2와 같은 숫자값으로 일대일 매칭시키는 것입니다.
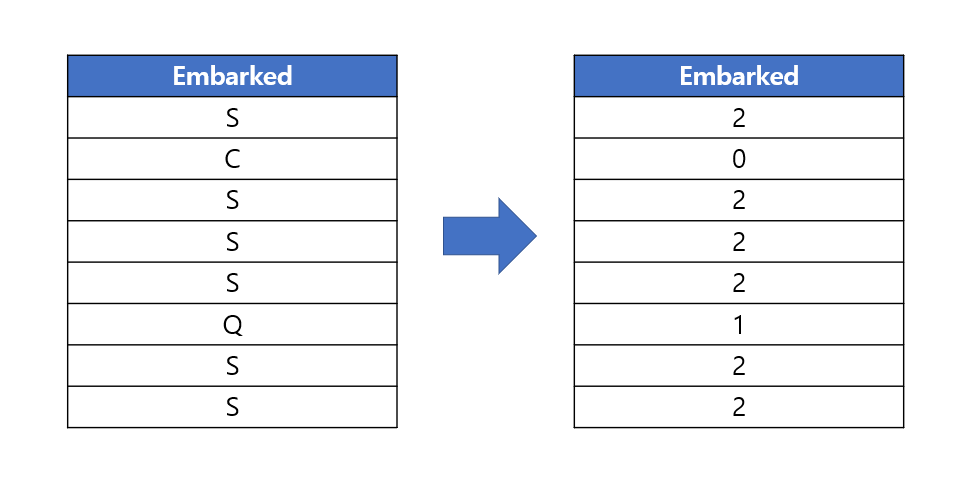
이 방법을 사용하면 범주형 변수의 값들이 모두 모델이 인식할 수 있는 숫자값으로 변환되기 때문에, 원핫 인코딩처럼 변수가 따로 추가 생성되지 않습니다.
💻 실습 1
파이썬에서 라벨인코딩을 통해 세 범주값(C, Q, S)을 모델이 인식할 수 있는 0, 1, 2라는 숫자값으로 변환해보겠습니다.
- 라벨인코딩은 사이킷런의
LabelEncoder클래스를 통해 구현할 수 있습니다.- LabelEncoder로 객체를 생성한 후
fit()과transform()또는fit_transform()을 호출해서 라벨인코딩을 수행하면 됩니다.
코드
# LabelEncoder 클래스를 불러옵니다.
from sklearn.preprocessing import LabelEncoder
# LabelEncoder를 객체로 생성합니다.
le = LabelEncoder()
# fit_transform()으로 라벨인코딩을 수행합니다.
train['Embarked'] = le.fit_transform(train['Embarked'])# 라벨인코딩이 잘 되었는지 확인합니다.
train['Embarked'].head(10)C는 0, Q는 1, S는 2로 변환된 것을 확인할 수 있습니다.
💻 실습 2
만약 데이터에 문자열로 된 범주형 변수가 여러 개 존재하고, 전부 라벨인코딩을 적용하고 싶다면 for문을 사용하면 됩니다.
다음과 같은 타이타닉 데이터의 "Cabin", "Sex", "Embarked" 변수에 대해 라벨인코딩을 적용해보겠습니다. (결측치는 이미 앞단계에서 처리한 걸로 간주합니다.)
| Cabin | Sex | Embarked |
|---|---|---|
| C85 | female | C |
| C123 | female | S |
| ... | ... | ... |
| B42 | female | S |
| C148 | male | C |
코드
# LabelEncoder 클래스를 불러옵니다.
from sklearn.preprocessing import LabelEncoder
# 라벨인코딩을 적용할 변수의 리스트를 생성합니다.
features = ['Cabin', 'Sex', 'Embarked']
# fit()과 transform()으로 라벨인코딩을 수행합니다.
for feature in features:
le = LabelEncoder()
le = le.fit(train[feature])
train[feature] = le.transform(train[feature])
다음과 같이 라벨인코딩이 잘 적용되었음을 확인할 수 있습니다.
| Cabin | Sex | Embarked |
|---|---|---|
| 81 | 0 | 0 |
| 55 | 0 | 2 |
| ... | ... | ... |
| 30 | 0 | 2 |
| 60 | 1 | 0 |
🔎 주의할 점
- 라벨인코딩은 선형회귀와 같은 ML 알고리즘에는 적용하지 않아야 합니다.
- 물론, 트리 계열의 모델은 이러한 숫자의 특성을 반영하지 않으므로 라벨인코딩을 적용해도 별문제 없습니다.
라벨인코딩은 문자열로 된 범주값을 숫자형 카테고리 값으로 간단하게 변환해준다는 장점이 있습니다. 하지만 몇몇 머신러닝 알고리즘에 이를 적용할 경우 예측 성능이 떨어지는 문제가 발생할 수 있습니다.
왜냐하면, 숫자값의 크고 작음에 대한 특성이 작용하기 때문입니다.
Embarked 컬럼에서 Q가 1, S가 2로 변환되면, 1보다는 2가 더 큰 값이므로 머신러닝 모델에서는 가중치가 더 부여되거나 더 중요하게 인식할 가능성이 발생합니다.
이러한 특성 때문에 라벨인코딩은 선형회귀와 같은 ML 알고리즘에는 적용하지 않는 것이 좋습니다.
✅ 원-핫 인코딩(One-Hot encoding)
원-핫인코딩은 고유 값에 해당하는 컬럼은 1, 나머지 컬럼에는 0을 표시하는 방식입니다.
즉, 행 형태로 되어 있는 변수의 고유 값을 열 형태로 차원을 변환한 뒤 고유 값에 해당하는 컬럼에만 1을 표시하고 나머지 컬럼에는 0을 표시합니다.
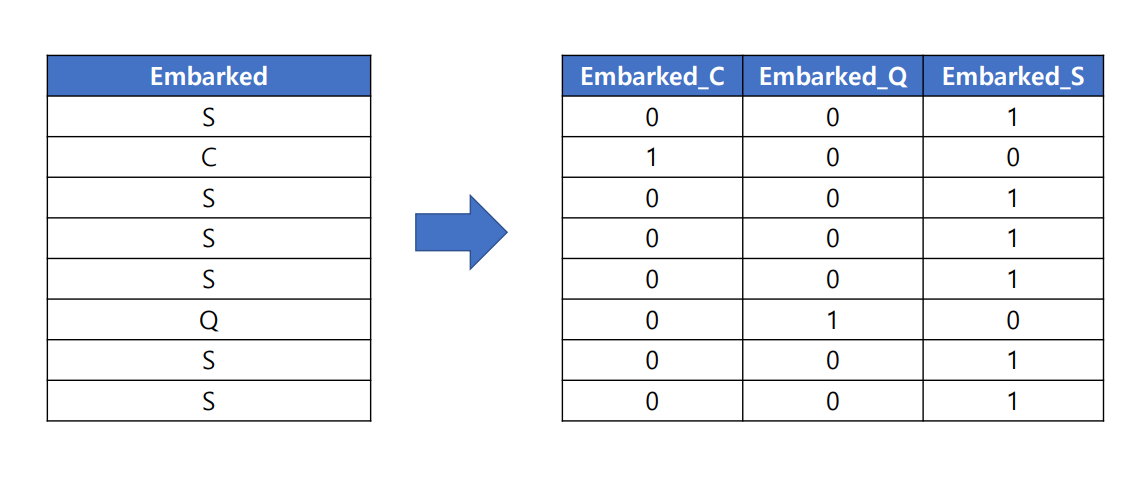
원-핫인코딩을 'Embarked' 변수에 적용하게 되면, 각각의 범주값들이 컬럼으로 생성됩니다.
다시 말해, 해당 범주형 변수의 범주값 개수만큼 새로운 컬럼이 생성됩니다.
또한 해당 행의 Embarked 값이 매칭되는 컬럼에만 1이 입력되고, 나머지 컬럼은 모두 0이 됩니다.
💻 실습
원-핫 인코딩은 다음과 같은 두 가지 방법으로 적용할 수 있습니다.
- 사이킷런의
OneHotEncoder클래스 사용- pandas 패키지의
get_dummies()사용
get_dummies()는 OneHotEncoder와 다르게 문자열 카테고리 값을 숫자형으로 변환할 필요 없이, 바로 변환할 수 있습니다. 따라서 get_dummies()를 이용해 'Embarked' 컬럼에 대해서만 원핫인코딩을 적용해보겠습니다.
코드
# get_dummies()으로 원핫인코딩을 수행합니다.
pd.get_dummies(train, columns = ['Embarked'])| ... | Embarked_C | Embarked_Q | Embarked_S |
|---|---|---|---|
| ... | 0 | 0 | 1 |
| ... | 1 | 0 | 0 |
| ... | 0 | 0 | 1 |
| ... | 0 | 0 | 1 |
| ... | 0 | 0 | 1 |
| ... | ... | ... | ... |
| ... | 0 | 0 | 1 |
| ... | 0 | 0 | 1 |
| ... | 0 | 0 | 1 |
| ... | 1 | 0 | 0 |
| ... | 0 | 1 | 0 |
Embarked_범주값 형태의 변수 3개가 생성되고, 각각 0 또는 1이 입력되었습니다.
이렇게 문자열로 구성된 변수에 라벨인코딩 또는 원핫인코딩을 적용해 값들을 모두 숫자로 바꿔주고 나면, 모델이 잘 인식할 수 있게 됩니다 😀
참고
