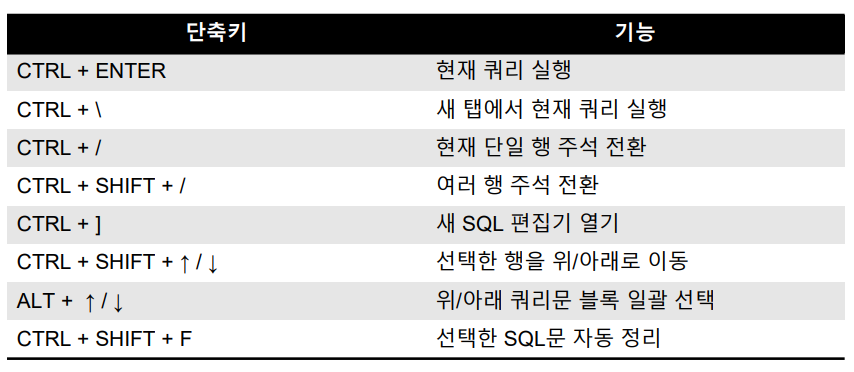
DBeaver 자주 쓰는 단축키
DBeaver로 DB insert
- Database(MySQL) 연결 (pw 입력 후 test connection 진행)
- 'HR'이라는 새로운 Database 생성
- Databases 우클릭 → Create new database
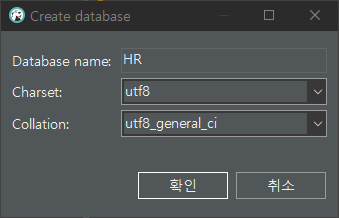
- Databases 우클릭 → Create new database
- HR Schema 우클릭 → 데이터 가져오기 (csv 파일 가져오기)
SELECT
Data 전체 column 조회
SELECT *
FROM hr.hr_employee_attrition hea
;특정 column만 조회
SELECT EmployeeNumber, Attrition, Department, JobRole, JobLevel
FROM hr.hr_employee_attrition hea
;Q. hr_employee_attrition 데이터에서 python pandas DataFrame으로 동일하게 column을 추출하려면?
A.df[['EmployeeNumber', 'Attrition', 'Department', 'JobRole', 'JobLevel']]
Count & DISTINCT
Count : 데이터 row 개수 카운트
DISTINCT : 해당 컬럼의 중복 제거된 unique 값
- python pandas와 비슷한 메서드로는, drop_duplicates, unique / nunique가 있음
-- Row 수 조회 : 1470 row
SELECT count(*) AS count_row
FROM hr.hr_employee_attrition hea
;
-- 직원 수 조회 : 1470명
SELECT COUNT(DISTINCT EmployeeNumber) Headcount
FROM HR.HR_Employee_Attrition hea
;GROUP BY & ORDER BY
GROUP BY : 기준 column으로 데이터의 집계값 산출
ORDER BY : 기준 column으로 데이터의 정렬 순서 설정
SQL 쿼리 실행 순서
1. FROM → 2. WHERE → 3. SELECT → 4. GROUP BY → 5. ORDER BY
-- Department, JobRole, JobLevel별 재직 인원수 조회
SELECT Department, JobRole, JobLevel, count(*) AS hc
FROM hr.hr_employee_attrition hea
WHERE Attrition = 'No'
GROUP BY Department, JobRole, JobLevel
;
-- 다양한 집계함수
-- Department, JobRole, Gender별로 재직인원수, age의 최대값/최소값/평균값 산출 (재직인원 기준)
SELECT Department, JobRole, Gender
, count(*) AS hc
, max(Age) max_age
, min(Age) min_age
, avg(Age) avg_age
FROM hr.hr_employee_attrition hea
WHERE Attrition = 'No'
GROUP BY Department, JobRole, Gender
;
-- Department, JobLevel별
-- 재직인원수, TotalWorkingYears 평균값, YearsAtCompany 평균값, MonthlyIncome 최대값/최소값 (재직인원 기준)
SELECT Department, JobLevel
, count(*) AS hc
, round(avg(TotalWorkingYears), 1) avg_total_years
, round(avg(YearsAtCompany), 1) avg_years_at_company
, max(MonthlyIncome) max_income
, min(MonthlyIncome) min_income
FROM hr.hr_employee_attrition hea
WHERE Attrition = 'No'
GROUP BY 1, 2
ORDER BY avg_years_at_company DESC
-- GROUP BY, ORDER BY절에서 column alias 사용 가능
;비교연산자
-- 데이터에 중복값이 없음을 확인
SELECT
(SELECT count(*)
FROM hr.hr_employee_attrition hea)
=
(SELECT count(DISTINCT EmployeeNumber) AS hc
FROM hr.hr_employee_attrition hea) check_duplicated
;
SELECT count(*)
FROM (
SELECT DISTINCT *
FROM hr.hr_employee_attrition hea
) hea2
-- 특정 팀(sales)의 인원 수 확인
SELECT count(*)
FROM hr.hr_employee_attrition hea
WHERE 1=1
AND Department ='Sales'
AND Attrition = 'No'
;
-- Q. 해당 조건 대상자 인원 수 확인
-- 최소 1년 이상 재직, 나이 30살 이하, joblevel 2 이하, hr팀 제외
SELECT count(*)
FROM hr.hr_employee_attrition hea
WHERE 1=1
AND YearsAtCompany >= 1
AND Attrition = 'No'
AND Age <= 30
AND JobLevel <= 2
AND Department != 'Human Resources'
;논리연산자
-- 최소 5년 이상 재직, 나이 30 이상 ~ 45 이하, joblevl 3,4, sales 또는 R&D 소속
SELECT count(*)
FROM hr.hr_employee_attrition hea
WHERE 1=1
AND Attrition = 'No'
AND YearsAtCompany >= 5
AND Age BETWEEN 30 AND 45 -- Age >= 30 AND Age <= 45
AND JobLevel IN (3,4) -- JobLevel BETEWEEN 3 AND 4
AND Department IN ('Sales', 'Research & Development')
;
-- Department, joblevel, gender별 인원수, 평균 연령 표기 (평균 연령으로 내림차순(round 0))
-- HC, avg_age 컬럼명 명명
SELECT Department, JobLevel, Gender
, count(*) HC
, round(avg(Age), 0) Avg_age
FROM hr.hr_employee_attrition hea
WHERE 1=1
AND Attrition = 'No'
AND YearsAtCompany >= 5
AND Age BETWEEN 30 AND 45
AND JobLevel IN (3,4)
AND Department IN ('Sales', 'Research & Development')
GROUP BY Department, JobLevel, Gender
ORDER BY Avg_age DESC
;