현업과 유사한 환경에서 실습하기 위해 테이블을 분리하여 생성
문자열 / 숫자로 테이블 분리 (두 테이블의 고유키는EmployeeNumber)
테이블 분리
기존 원천 테이블로부터 2개의 미니 테이블 생성
방법1. 빈 테이블 생성(CREATE TABLE) 후 데이터 넣기(INSERT INTO)
-- string type
CREATE TABLE hr.hr_cate
(
EmployeeNumber int(11)
, Attrition varbinary(50)
, BusinessTravel varbinary(50)
, Department varbinary(50)
, EducationField varbinary(50)
, Gender varbinary(50)
, JobRole varbinary(50)
, MaritalStatus varbinary(50)
, OverTime varbinary(50)
);
INSERT INTO hr.hr_cate
(
SELECT EmployeeNumber
, Attrition
, BusinessTravel
, Department
, EducationField
, Gender
, JobRole
, MaritalStatus
, OverTime
FROM hr.hr_employee_attrition hea
);방법2. CREATE TABLE + SELECT 쿼리문 입력 (From 원천 테이블)
-- numeric type
CREATE TABLE hr.hr_number
(
SELECT EmployeeNumber, Age, DailyRate, DistanceFromHome, Education, EmployeeCount
, EnvironmentSatisfaction, HourlyRate, JobInvolvement, JobLevel, JobSatisfaction
, MonthlyIncome, MonthlyRate, NumCompaniesWorked, PercentSalaryHike, PerformanceRating
, RelationshipSatisfaction, StandardHours, StockOptionLevel, TotalWorkingYears, TrainingTimesLastYear
, WorkLifeBalance, YearsAtCompany, YearsInCurrentRole, YearsSinceLastPromotion, YearsWithCurrManager
FROM hr.hr_employee_attrition hea
);테이블 새로고침하면 생성된 테이블 확인 가능
생성한 테이블 간 관계 설정 필요
- hr_number 테이블 엔티티 관계도 탭에 hr_cate 테이블 드래그하여 추가
- EmployeeNumber를 key값으로 연결되었다
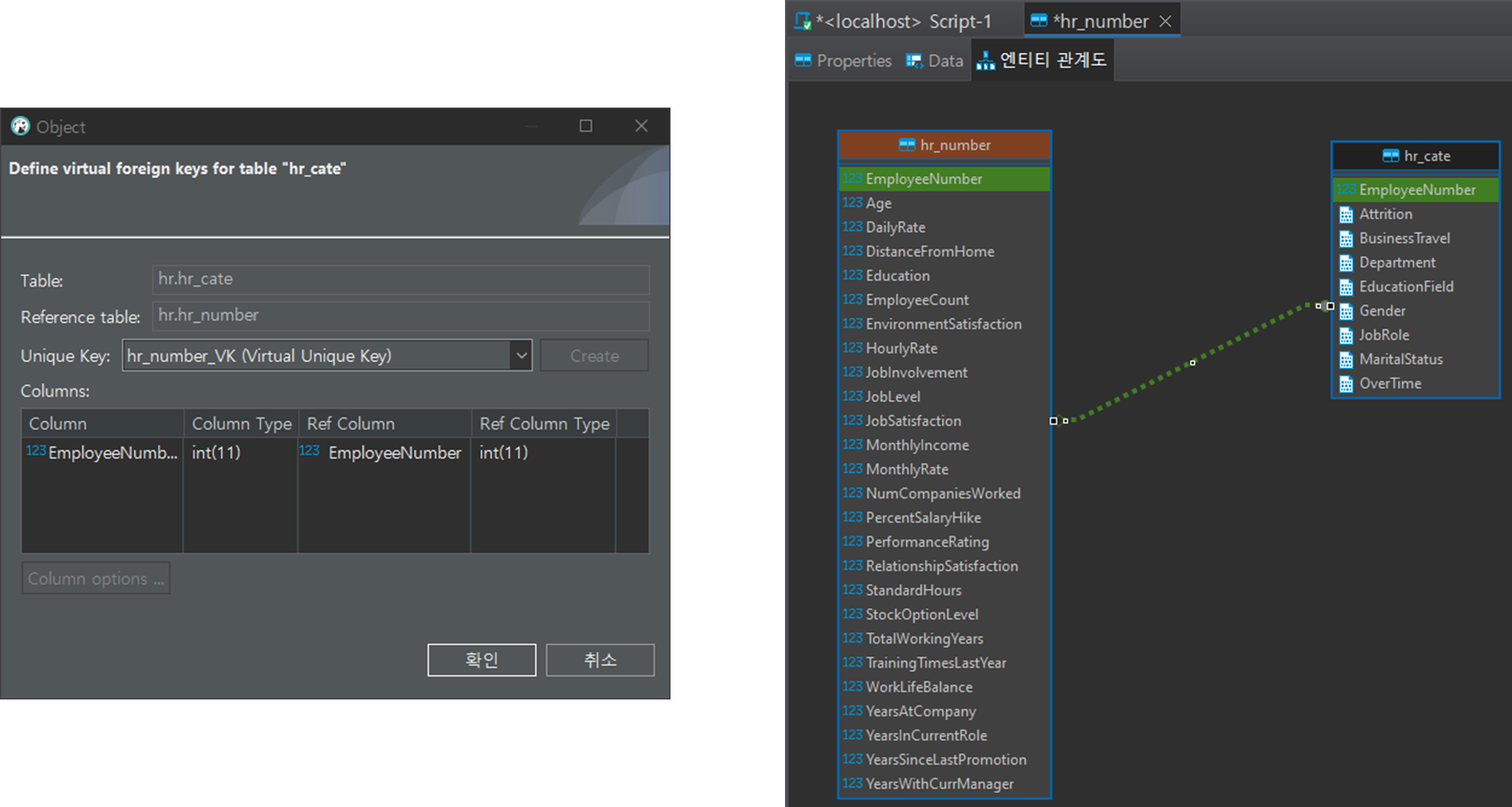
- EmployeeNumber를 key값으로 연결되었다
참고. Data Type
Numeric Data
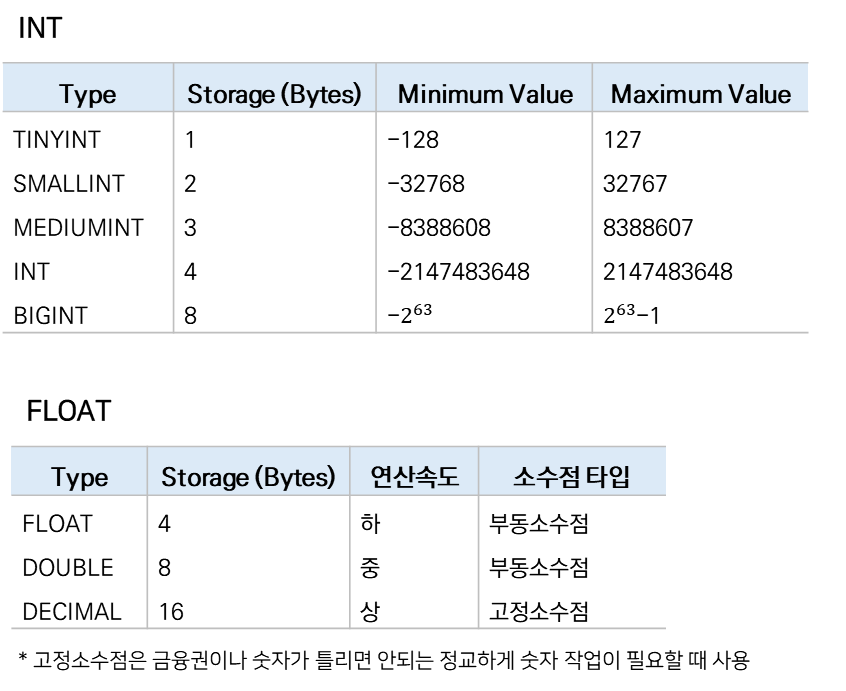
String Data
- CHAR는 입력된 문자와 상관없이 자릿수 4자리
- VARCHAR는 CHAR에 비해 유동성 있음
- varbinary : 대소문자 구분하여 사용 가능 (varchar와 보기엔 동일하지만 컴퓨터에서 인식하는 인코딩이 다름)

Table Join
: 두 개 이상의 테이블을 합친다
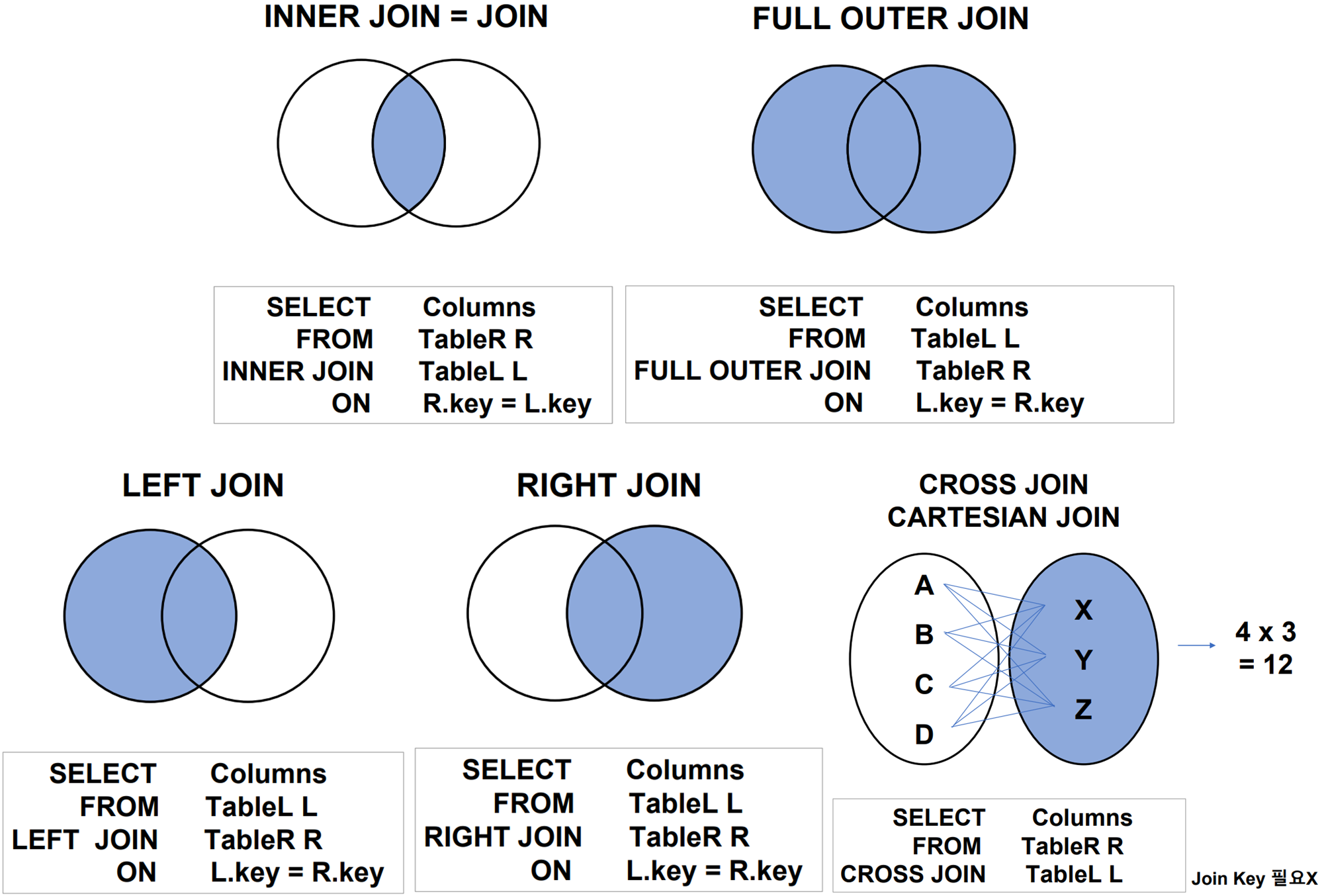
위에서 나눈 두 테이블은 key값인 EmployeeNumber가 1:1로 무조건 매칭되게 됨
→ inner, left, right join 중 어떤 방법을 사용하든 같은 결과가 나올 것
USING을 활용한 join

- key값으로 사용하는 컬럼 이름이 완벽이 일치하는 경우 사용 가능
- 다만, 선호하는 방법은 아님
어떤 테이블에서 어떤 컬럼을 join시킨 것인지 알 수 있도록 명시해주는 것이 좋다
LIMIT & HAVING
- LIMIT : 결과값에 대하여 상위 n번째 row까지 보여주도록 필터링
- HAVING : 집계되어 나온 결과값에 대한 조건을 걸어 필터링
- GROUP BY된 테이블에 조건을 거는 것이기 때문에 ORDER BY절 전에 와야 함
-- LIMIT
-- : 정렬되어 나온 결과값에서 상위 5번째 row까지만 출력
SELECT Department, EducationField, count(DISTINCT hc.EmployeeNumber) hc
FROM hr.hr_cate hc
LEFT JOIN hr.hr_number hn
ON hc.EmployeeNumber = hn.EmployeeNumber
WHERE 1=1
AND Attrition = 'No'
GROUP BY 1,2
ORDER BY hc DESC
LIMIT 5
;
-- HAVING
-- 동일한 Department에 EducationField를 가진 사람들끼리 그룹군을 나눈다고 할때, 한 그룹군에 30명 이하인 그룹군만 본다면
SELECT Department, EducationField, count(DISTINCT hc.EmployeeNumber) hc
FROM hr.hr_cate hc
LEFT JOIN hr.hr_number hn
ON hc.EmployeeNumber = hn.EmployeeNumber
WHERE 1=1
AND Attrition = 'No'
GROUP BY 1,2
HAVING hc <= 30
ORDER BY hc DESC
;Window Function
- 집계된 결과값을 기존 데이터에 추가하여 보여줌
- 합계, 평균, 순위 매기기, 순서 조작 등
- 결과를 출력하되, 결과 건수가 줄어들지 않음, 기존 데이터에 집계된 값을 추가하여 보여줌
- Group By와 공통점 : 집계함수를 활용하여 특정 컬럼을 기준으로 집계된 결과를 산출
- 차이점 : Group By는 집계된 결과만 보여주기 때문에 최종 결과 건수가 줄어듦
- 기본 구조는 아래와 같음

예시)
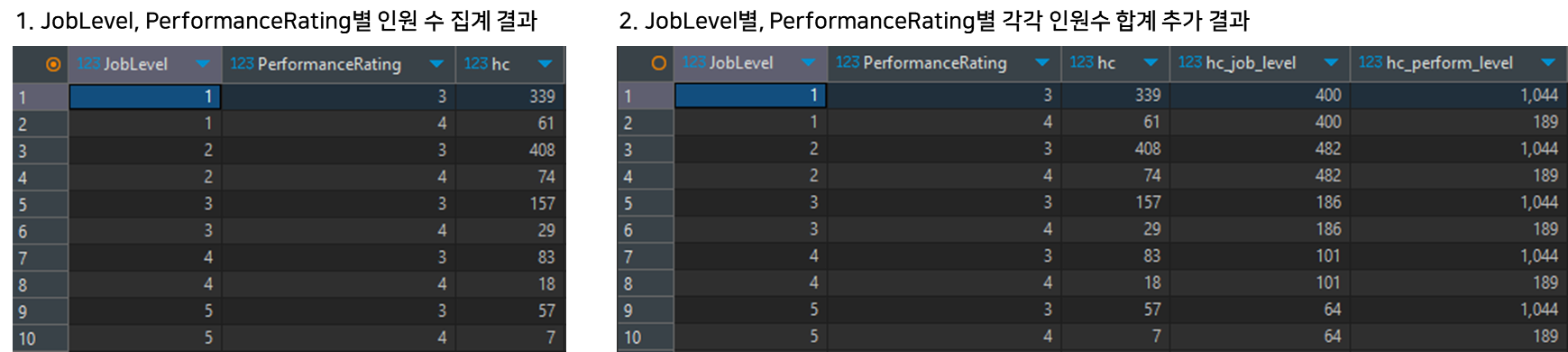
JobLevel, PerformanceRating 별 인원 수 집계에서 추가적으로 같은 JobLevel별 인원수 합계와 PerformanceRating별 인원수 합계 각각도 궁금하다면?
- JobLevel, PerformanceRating 별 인원 수 집계
SELECT JobLevel, PerformanceRating, count(DISTINCT hn.EmployeeNumber) hc
FROM hr.hr_number hn
LEFT JOIN hr.hr_cate hc ON hn.EmployeeNumber = hc.EmployeeNumber
WHERE Attrition = 'No'
GROUP BY 1,2
ORDER BY 1,2
;- JobLevel별 인원수 합계와 PerformanceRating별 인원수 합계 각각 추가
-- PARTITION BY 컬럼명 : 집계 기준 컬럼 설정
SELECT JobLevel, PerformanceRating
, count(DISTINCT hn.EmployeeNumber) AS hc
, sum(count(DISTINCT hn.EmployeeNumber)) OVER (PARTITION BY JobLevel) AS hc_job_level
, sum(count(DISTINCT hn.EmployeeNumber)) OVER (PARTITION BY PerformanceRating) AS hc_perform_level
FROM hr.hr_number hn
LEFT JOIN hr.hr_cate hc ON hn.EmployeeNumber = hc.EmployeeNumber
WHERE Attrition = 'No'
GROUP BY 1,2
ORDER BY 1,2
;
LEAD & LAG
컬럼의 순서를 조작하는 함수 (Window Function의 한 종류)
- LEAD : 다음에 있는 것을 당겨온다
- LAG : 뒤에 있는 것을 데려온다
- 기본 구조

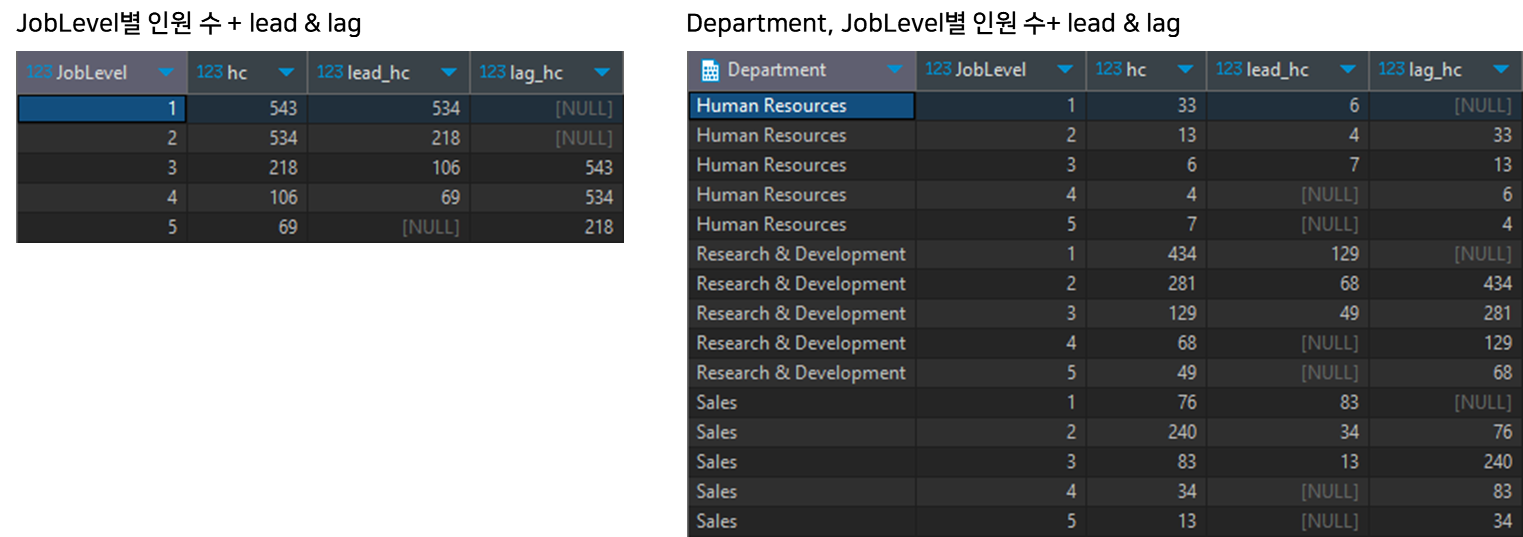
JobLevel별 인원수
SELECT JobLevel
, count(DISTINCT hn.EmployeeNumber) AS hc
, LEAD(count(DISTINCT hn.EmployeeNumber)) OVER (ORDER BY JobLevel) AS lead_hc
, LAG(count(DISTINCT hn.EmployeeNumber), 2) OVER (ORDER BY JobLevel) AS lag_hc
-- 조작할 row 수 지정 가능
FROM hr.hr_cate hc
LEFT JOIN hr.hr_number hn ON hc.EmployeeNumber = hn.EmployeeNumber
GROUP BY 1
ORDER BY 1
;Department, JobLevel별 인원수
SELECT Department, JobLevel
, count(DISTINCT hn.EmployeeNumber) AS hc
, LEAD(count(DISTINCT hn.EmployeeNumber), 2) OVER (PARTITION BY Department ORDER BY JobLevel) AS lead_hc
, LAG(count(DISTINCT hn.EmployeeNumber)) OVER (PARTITION BY Department ORDER BY JobLevel) AS lag_hc
FROM hr.hr_cate hc
LEFT JOIN hr.hr_number hn ON hc.EmployeeNumber = hn.EmployeeNumber
GROUP BY 1,2
ORDER BY 1,2
;