오늘은 네이버 쇼핑몰 리뷰 크롤링을 진행해봤습니다. "LG 에어로타워"에 대한 리뷰가 필요한데, 네이버 쇼핑몰의 리뷰가 수는 적어도 괜찮은 평가들이 있더라구요!
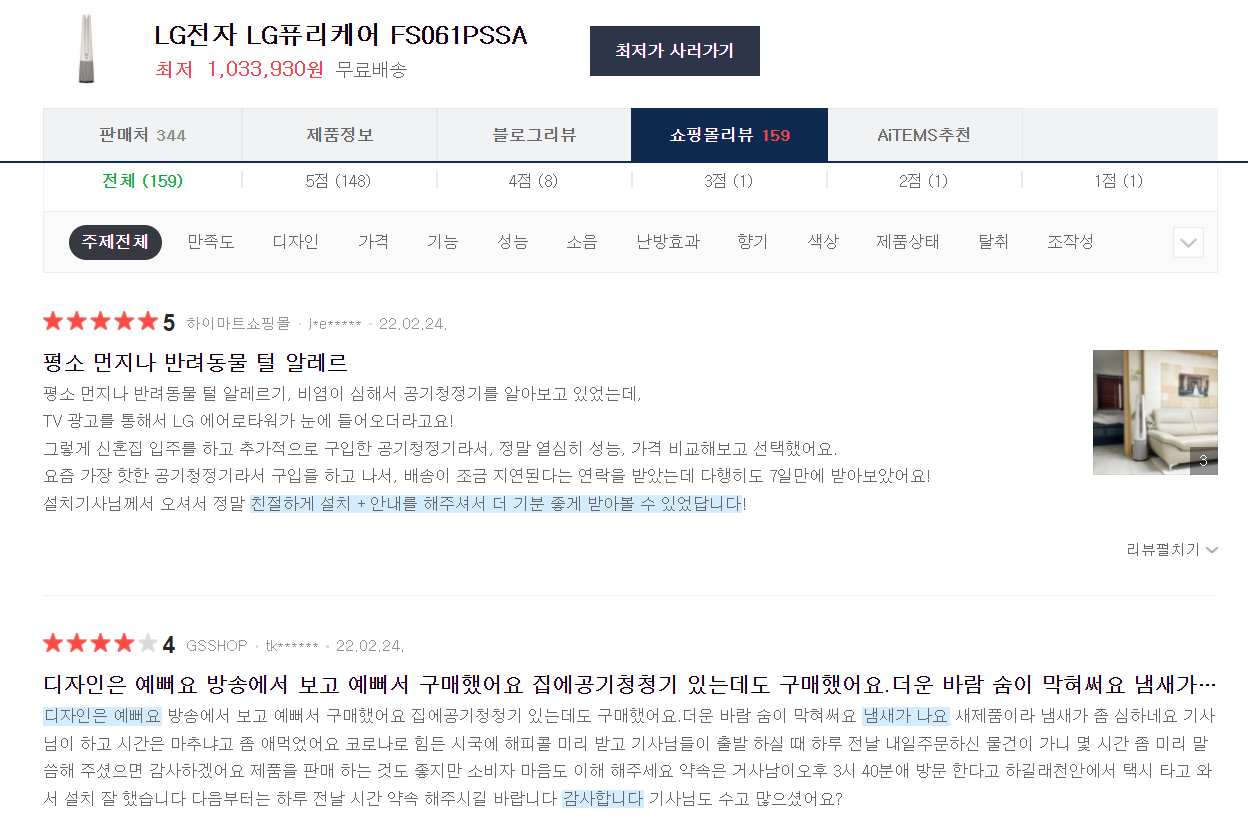 에어로타워 쇼핑몰리뷰를 크롤링해보겠습니다.
에어로타워 쇼핑몰리뷰를 크롤링해보겠습니다.
1. 사용할 라이브러리 불러오기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
from time import sleep
import requests
import re
import pandas as pd
import numpy as np
import os
from selenium.webdriver.common.keys import Keys
import warnings
warnings.filterwarnings('ignore')크롤링을 위해 Selenium과 BeautifulSoup를 불러옵니다!
2. 웹사이트 불러오기
name=['LG 에어로타워']
category=['별점']
#LG 에어로타워 후기
ns_address="https://search.shopping.naver.com/catalog/30128278618?cat_id=50002543&frm=NVSCPRO&query=%EC%97%90%EC%96%B4%EB%A1%9C%ED%83%80%EC%9B%8C&NaPm=ct%3Dl0ksn0vc%7Cci%3D5bbd25c0299ce5dbcb72ff2b1d41488ebd6d52ce%7Ctr%3Dsls%7Csn%3D95694%7Chk%3D87194ce8ced4cb2b52968022b8eb9db67602d12e"
#xpath
shoppingmall_review="/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul"크롤링할 웹사이트 주소를 ns_address에 입력해줍니다. 그리고 전 1점부터 5점까지 모든 리뷰를 크롤링할 것이라 shoppingmall_review에 전체 리뷰 부분을 입력해줬습니다. 따로 크롤링할 부분을 정하고 싶으신 분들은 category를 추가로 입력해주시면 됩니다.
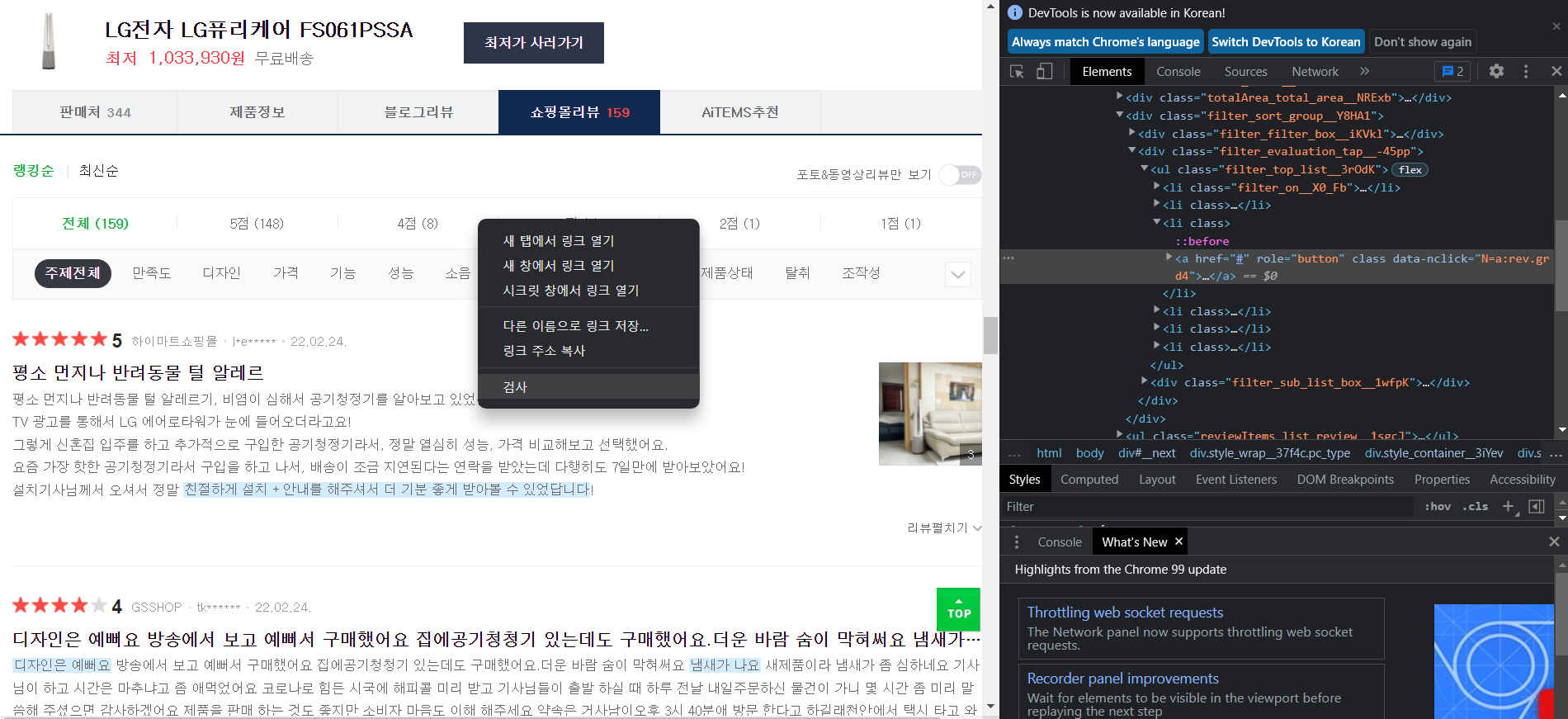 html 주소를 찾고싶은 부분에서 우클릭한 후 "검사"를 눌러주면 쉽게 찾을 수 있습니다. 그리고 필요한 주소에서 "우클릭 -> Copy -> Copy full XPath" 를 눌러주면 됩니다.
html 주소를 찾고싶은 부분에서 우클릭한 후 "검사"를 눌러주면 쉽게 찾을 수 있습니다. 그리고 필요한 주소에서 "우클릭 -> Copy -> Copy full XPath" 를 눌러주면 됩니다.
3. 쇼핑몰 리뷰 불러오기
header = {'User-Agent': ''}
d = webdriver.Chrome('chromedriver.exe') # webdriver = chrome
d.implicitly_wait(3)
d.get(ns_address)
req = requests.get(ns_address,verify=False)
html = req.text
soup = BeautifulSoup(html, "html.parser")
sleep(2)
#쇼핑몰 리뷰 보기
d.find_element_by_xpath(shoppingmall_review).click()
sleep(2)
element=d.find_element_by_xpath(shoppingmall_review)
d.execute_script("arguments[0].click();", element)
sleep(2)webdriver를 통해 Chrome을 임의로 실행합니다.
4. 데이터 프레임 만들기
def add_dataframe(name,category,reviews,stars,cnt): #데이터 프레임에 저장
#데이터 프레임생성
df1=pd.DataFrame(columns=['type','category','review','star'])
n=1
if (cnt>0):
for i in range(0,cnt-1):
df1.loc[n]=[name,category,reviews[i],stars[i]] #해당 행에 저장
i+=1
n+=1
else:
df1.loc[n]=[name,category,'null','null']
n+=1
return df1크롤링한 데이터를 저장할 곳도 필요하겠죠?
5. 리뷰 가져오기
# 리뷰 가져오기
d.find_element_by_xpath(shoppingmall_review).click() #스크롤 건드리면 안됨
name_=name[0]
category_=category[0]
reviews=[]
stars=[]
cnt=1 #리뷰index
page=1임의로 실행한 Chrome에서 리뷰를 가져옵니다. 리뷰와 평점에 대한 변수명도 지정해줍니다.
6. 리뷰 수집하기
while True:
j=1
print ("페이지", page ,"\n")
sleep(2)
while True: #한페이지에 20개의 리뷰, 마지막 리뷰에서 error발생
try:
star=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li[1]/div[1]/span[1]').text
stars.append(star)
review=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li['+str(j)+']/div[2]/div[1]').text
reviews.append(review)
if j%2==0: #화면에 2개씩 보이도록 스크롤
ELEMENT = d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li['+str(j)+']/div[2]/div[1]')
d.execute_script("arguments[0].scrollIntoView(true);", ELEMENT)
j+=1
print(cnt, review ,star, "\n")
cnt+=1
except: break
sleep(2)
if page<11:#page10
try: #리뷰의 마지막 페이지에서 error발생
page +=1
next_page=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a['+str(page)+']').click()
except: break #리뷰의 마지막 페이지에서 process 종료
else :
try: #page11부터
page+=1
if page%10==0: next_page=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a[11]').click()
else : next_page=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a['+str(page%10+2)+']').click()
except: break
df4=add_dataframe(name_,category_,reviews,stars,cnt)
#save()이제 리뷰 데이터를 수집해줘야겠죠? star부분에는 평점이 있는 XPath를 입력해주시고, review부분에는 리뷰가 있는 XPath를 입력해주시면 됩니다.
7. 엑셀 파일로 저장하기
df4.to_excel('result.xlsx')마지막으로 엑셀파일로 저장하면 됩니다.

혼자 공부하는 데이터분석