3일차
- 오늘은 선형회귀의 연장선으로 정규화에 대해 알아보자!
이상치(Outlier)
- 데이터 중 일반적인 값에 비해 편차가 큰 데이터
- boxplot을 그려보면 이상치를 쉽게 알 수 있다.
- 독립변수(feature)에서 발생하는 편차가 큰 값 == 지대점
- 종속변수(target)에서 발생하는 편차가 큰 값 == 이상치
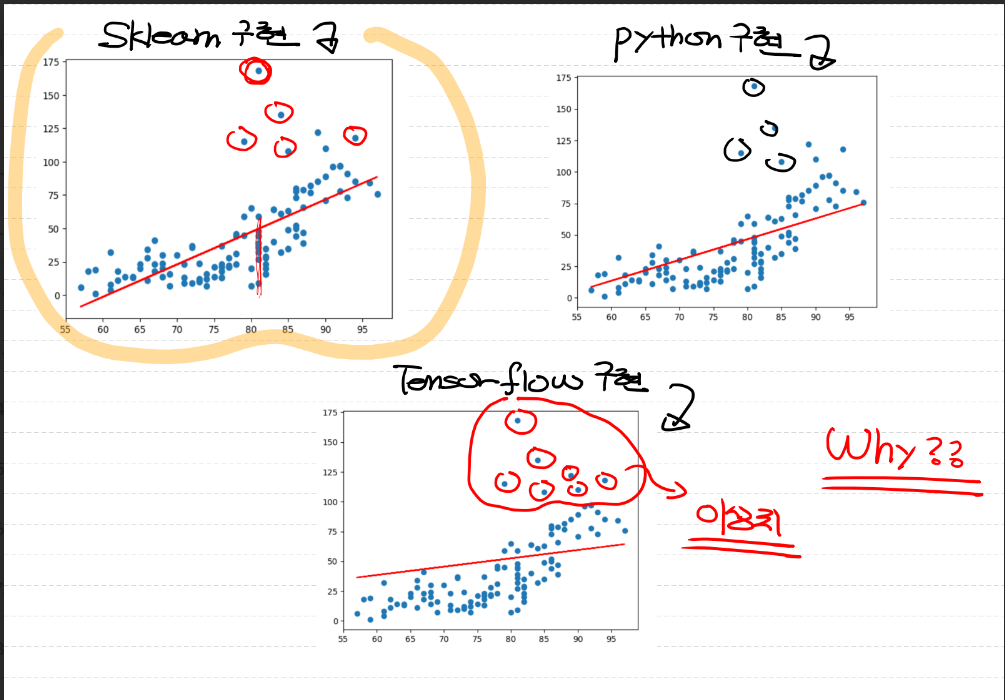
- 위 자료처럼 같은 데이터를 가지고 구현했음에도 불구하고 sklearn과 python 구현은 비슷한 반면, tensorflow 구현은 값이 다른 것을 알 수 있다.
- 위와 같은 현상이 발생하는 이유는 바로 이상치 때문!!
- Regression은 조건부 평균을 구하는 것인데, 이상치가 있으면 결과가 좋좋지 않기 때문이다!
- 해결방법 == 이상치 처리
이상치 처리(Outlier Handling)
- 우리의 모델을 좀 더 발전시키기 위해 데이터를 전처리하는 방법
- 이상치를 제거하는 방법에는 여러가지가 있지만, 우리가 배울 것은 2가지
- Tukey Fence & 정규분포(z-score)
Tukey Fence
- Tukey Fence 방식은 사분위수(IQR)을 사용 한다.

- 위 그림을 보면 이상치와 사분위수에 대해 이해가 쉬울 것이다.
- IQR Value = 3사분위 값 - 1사분위 값
- 이 IQR Value * 1.5가 Tukey Fence 방식에서의 이상치 판단 기준
- 3사분위 + IQR Value 1.5 보다 큰 값,
1사분위 - IQR Value 1.5 보다 작은 값이 바로 이상치!
z-score(정규분포)
- 말 그대로 정규분포를 사용하여 이상치를 구하는 방법이다
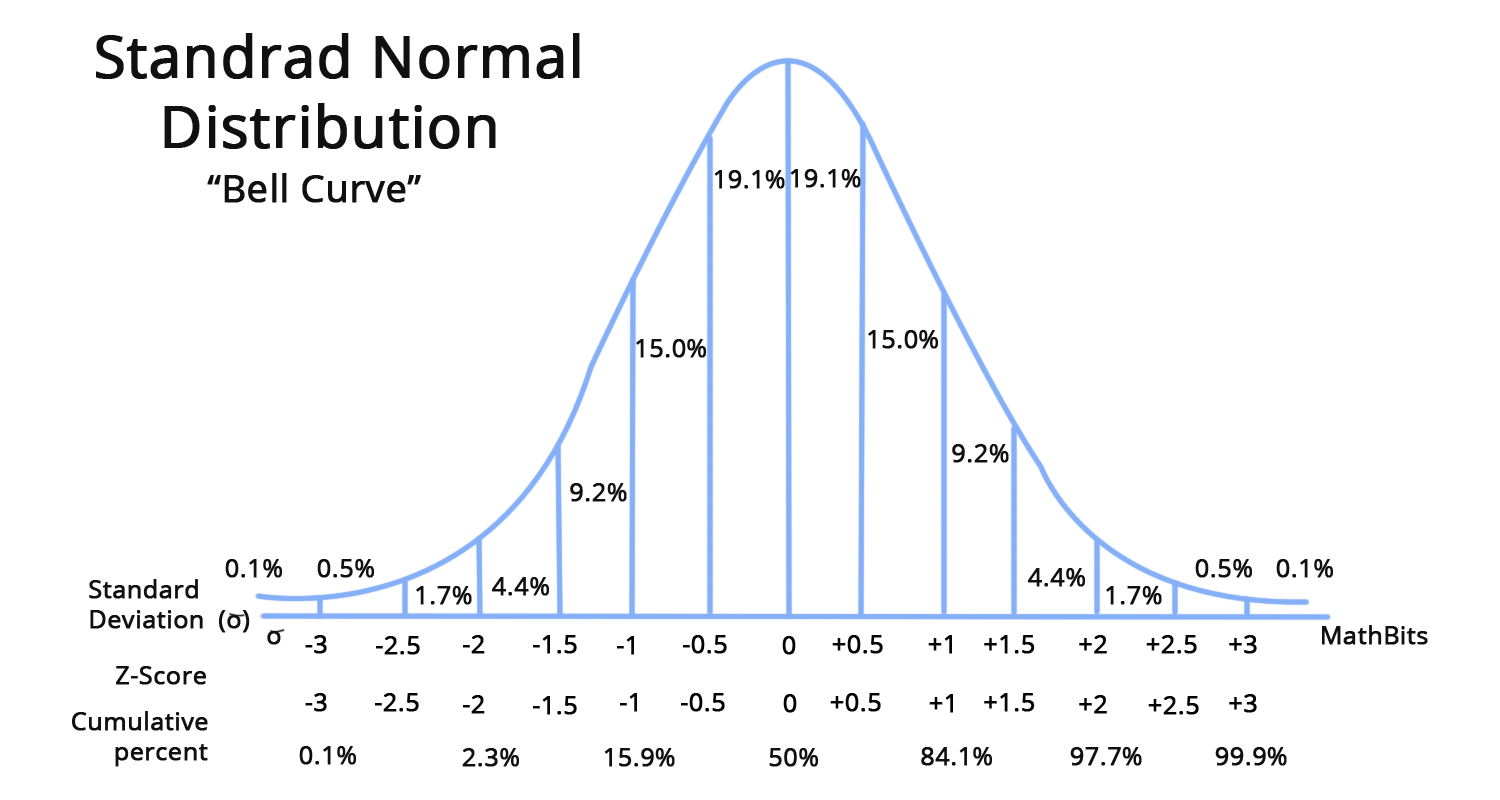
- 주로, z-score = 2를 기준으로 이상치를 잡는다
이렇게 이상치를 처리했음에도 우리의 Model이 이상해요ㅠ
-> 정규화를 하지 않았기 때문!!
정규화(Normalization)
- 데이터의 값을 0~1 사이의 값으로 변환 시켜주는 것!
- why???
- 데이터들의 범위가 각각 다르기 때문에 동일한 범위의 값들로
정규화 시켜주면 모델의 정확도가 향상 - 정규화를 해야하는 이유
- feature scale 조정
- 학습속도의 향상
- 특정 feature에 가중치가 부여되는 overfitting을 피할 수 있어요!
- 수치안정성(계산의 정확도가 높아져요)
- 거리기반 알고리즘의 경우 정규화가 필수!!
정규화의 종류
- Min-Max Normalization(Scaling)
- 정규화를 하는 가장 일반적인 방법
- 모든 feature에 대해 최소 0, 최대 1의 값을 가지도록 변경
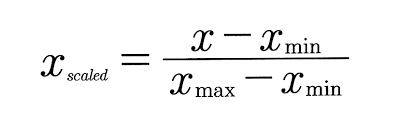
- 이상치에 취약하다는 단점!
- StandardScaler()
- 모든 feature들이 평균이 0, 분산이 1인 정규분포를 갖도록 만듬
코드 구현
- 위에서 설명한 개념들을 코드로 알아보아요!
- 이상치 부분에서 나온 그래프 그림부터 구현하고 나머지 내용들을 구현할 거에요!
ozone.csv를 활용한 Linear Regression 구현
- 우선, feature는 Temp 하나만 사용할 거에요!
코드_1(Python)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
## 수치미분 코드
def numerical_derivative(f,x):
# f : 미분하려고하는 다변수 함수
# x : 모든 변수를 포함하는 ndarray [1.0 2.0]
# 리턴되는 결과는 [8.0 15.0]
delta_x = 1e-4
derivative_x = np.zeros_like(x) # [0.0 0.0]
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
idx = it.multi_index # 현재의 index를 추출 => tuple형태로 리턴.
tmp = x[idx] # 현재 index의 값을 일단 잠시 보존해야해요!
# 밑에서 이 값을 변경해서 중앙차분 값을 계산해야 해요!
# 그런데 우리 편미분해야해요. 다음 변수 편미분할때
# 원래값으로 복원해야 편미분이 정상적으로 진행되기 때문에
# 이값을 잠시 보관했다가 원상태로 복구해야 해요!
x[idx] = tmp + delta_x
fx_plus_delta_x = f(x) # f(x + delta_x)
x[idx] = tmp - delta_x
fx_minus_delta_x = f(x) # f(x - delta_x)
derivative_x[idx] = (fx_plus_delta_x - fx_minus_delta_x) / (2 * delta_x)
x[idx] = tmp
it.iternext()
return derivative_x
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/[AI_SCHOOL_9기]/data/ozone/ozone.csv')
# display(df) # 153 rows × 6 columns
training_data = df[['Temp', 'Ozone']]
# display(training_data)
# 이렇게 데이터를 가져온 후 당연히 데이터 전처리를 해야 해요!
# 1. 결측치 처리!
# 지금은 그냥 냅다 삭제할 꺼예요! (데이터 많은 경우 가장 좋은 방법)
training_data = training_data.dropna(how='any')
# display(training_data) # 116 rows × 2 columns
# Training Data Set 준비
x_data = training_data['Temp'].values.reshape(-1,1)
t_data = training_data['Ozone'].values.reshape(-1,1)
# Model을 만들어야 하는데.. y = Wx + b
W = np.random.rand(1,1)
b = np.random.rand(1)
# loss function(MSE)
def loss_func(input_data):
input_w = input_data[0]
input_b = input_data[1]
y = np.dot(x_data, input_w) + input_b
return np.mean(np.power((t_data-y),2))
# 모델이 완성된 후 예측하는 함수를 하나 만들어요!
def predict(x):
return np.dot(x, W) + b
# learning rate 정의(hyperparameter)
learning_rate = 1e-4
# 학습진행
for step in range(300000):
input_param = np.concatenate((W.ravel(), b.ravel()), axis=0)
derivative_result = learning_rate * numerical_derivative(loss_func, input_param)
W = W - derivative_result[0].reshape(-1,1)
b = b - derivative_result[1]
if step % 30000 == 0:
print(f'W : {W}, b : {b}, loss : {loss_func(input_param)}')
# 학습종료 후 예측
# 온도가 62도일때 Ozone량은 얼마?
print(predict(np.array([[62]]))) # [[16.88607015]]
# 이거 맞는거야???
# 그래프로 확인해 보아요!
# (독립변수 1개니까 2차원 평면에 모델을 그릴수 있어요!)
# 데이터를 2차원 평면에 찍어보아요!
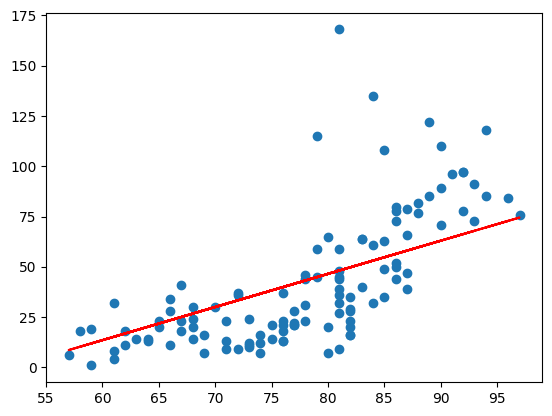
plt.scatter(x_data, t_data)
# 우리 모델을 그려보아요!
plt.plot(x_data, x_data*W.ravel() + b, color='r')
plt.show()- Python 구현 결과
코드_2(Tensorflow 구현)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import SGD
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/[AI_SCHOOL_9기]/data/ozone/ozone.csv')
training_data = df[['Temp', 'Ozone']]
# 이렇게 데이터를 가져온 후 당연히 데이터 전처리를 해야 해요!
# 1. 결측치 처리!
training_data = training_data.dropna(how='any')
# Training Data Set 준비
x_data = training_data['Temp'].values.reshape(-1,1)
t_data = training_data['Ozone'].values.reshape(-1,1)
# Model 생성
model = Sequential()
model.add(Flatten(input_shape=(1,)))
output_layer = Dense(units=1,
activation='linear')
model.add(output_layer)
# model 설정
model.compile(optimizer=SGD(learning_rate=1e-4),
loss='mse')
# model 학습
model.fit(x_data,
t_data,
epochs=2000,
verbose=0)
# 학습이 끝났으니 예측을 해 보아요!
print(model.predict(np.array([[62]]))) # [[39.92358]]
# 그래프로 확인해 보아요!
# W와 b가 필요해요!
weights, bias = output_layer.get_weights()
# 데이터를 2차원 평면에 찍어보아요!
plt.scatter(x_data, t_data)
# 우리 모델을 그려보아요!
plt.plot(x_data, x_data*weights + bias, color='r')
plt.show()- Tensorflow 결과
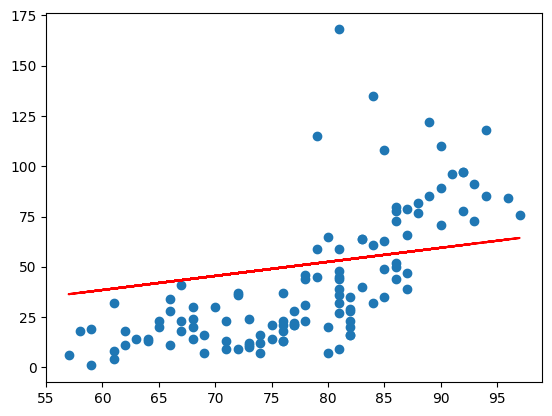
코드_3(sklearn 구현)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import linear_model
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/[AI_SCHOOL_9기]/data/ozone/ozone.csv')
training_data = df[['Temp', 'Ozone']]
# 이렇게 데이터를 가져온 후 당연히 데이터 전처리를 해야 해요!
# 1. 결측치 처리!
training_data = training_data.dropna(how='any')
# Training Data Set 준비
x_data = training_data['Temp'].values.reshape(-1,1)
t_data = training_data['Ozone'].values.reshape(-1,1)
# Model 생성
sklearn_model = linear_model.LinearRegression()
# Model 학습
sklearn_model.fit(x_data, t_data)
# W와 b를 알아야지 나중에 그래프를 그릴 수 있겠죠.
weights = sklearn_model.coef_
bias = sklearn_model.intercept_
# 예측을 해 보아요!
print(sklearn_model.predict(np.array([[62]]))) # [[3.58411393]]
# 데이터를 2차원 평면에 찍어보아요!
plt.scatter(x_data, t_data)
# 우리 모델을 그려보아요!
plt.plot(x_data, x_data*weights + bias, color='r')
plt.show()- sklearn 결과

이상치 처리
Tukey Fence
import numpy as np
import matplotlib.pyplot as plt
data = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,22.1])
fig = plt.figure()
fig_1 = fig.add_subplot(1,2,1) # 1행 2열의 첫번째
fig_2 = fig.add_subplot(1,2,2) # 1행 2열의 두번째
print(np.median(data)) # 8.0
print(np.percentile(data,25)) # 4.5
print(np.percentile(data,75)) # 11.5
# IQR value
iqr_value = np.percentile(data,75) - np.percentile(data,25)
print(iqr_value) # 7.0
upper_fence = np.percentile(data,75) + 1.5 * iqr_value
print(upper_fence) # 22.0
lower_fence = np.percentile(data,25) - 1.5 * iqr_value
print(lower_fence) # -6.0
# 아하!! 이렇게 tukey fence방식을 이용하면 이상치를 구분하는
# 기준선을 알아낼 수 있네요!
# 내가 가지고 있는 데이터에 대해 이상치를 출력해보세요!
# boolean indexing을 이용해요!
print(data[(data > upper_fence) | (data < lower_fence)]) # [22.1]
# 데이터를 정제하는게 목적이예요. 이상치를 제거하는게 목적!
result_data = data[(data <= upper_fence) & (data >= lower_fence)]
print(result_data)
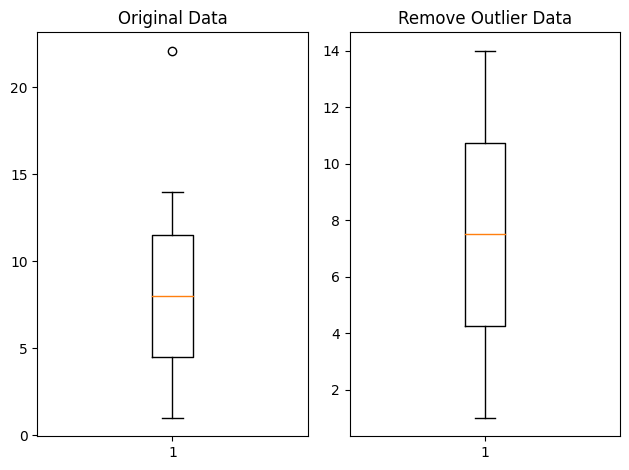
fig_1.set_title('Original Data')
fig_1.boxplot(data)
fig_2.set_title('Remove Outlier Data')
fig_2.boxplot(result_data)
plt.tight_layout()
plt.show()- Tukey Fence 결과
Z-score
# 정규분포(Z-score)를 이용한 이상치 구별방식
# 이 방식을 이용하려면
# 기본적으로 우리 데이터를 정규분포화 시켜서 우리 데이터에 대한
# z-score값을 각각 구해야 되요!
# 그리고 기준치를 설정한 다음 그 기준치를 넘는 데이터를 이상치로 판별
from scipy import stats
data = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,22.1])
zscore_threshold = 2.0 # 일반적으로 2.0을 많이 사용.
# print(np.abs(stats.zscore(data)) > zscore_threshold)
outlier = data[np.abs(stats.zscore(data)) > zscore_threshold] # [22.1]
# 이상치를 제거한 결과
print(data[np.isin(data,outlier, invert=True)])- Z-score 결과
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.]
Ozone.csv 파일에 이상치 처리를 적용!
이상치 처리
from scipy import stats
# 데이터는 공통으로 사용하니 먼저 사용하는 데이터 정제부터 하고
# 각각 구현하는게 좋을 듯 싶어요!
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/[AI_SCHOOL_9기]/data/ozone/ozone.csv')
training_data = df[['Temp', 'Ozone']]
# 이렇게 데이터를 가져온 후 당연히 데이터 전처리를 해야 해요!
# 1. 결측치 처리!
training_data = training_data.dropna(how='any')
# 2. 이상치 처리!
zscore_threshold = 1.8
outlier = training_data['Ozone'][np.abs(stats.zscore(training_data['Ozone'].values)) > zscore_threshold]
# print(outlier)
# 이상치를 제거한 결과를 얻어야 해요!
# 내가 가진 DataFrame에서 이상치를 제거하면 되요!
training_data = training_data.loc[np.isin(training_data['Ozone'],outlier, invert=True)]
# Training Data Set 준비
x_data = training_data['Temp'].values.reshape(-1,1)
t_data = training_data['Ozone'].values.reshape(-1,1)- python, tensorflow, sklearn 구현은 위에서 이미 했으니까 생략할게요!
이상치 처리 후 결과 비교
- 3가지 경우를 시각화 해서 비교해봅시다!
####### 결과를 그래프로 확인해 보아요! #########
fig = plt.figure()
fig_python = fig.add_subplot(1,3,1)
fig_tensorflow = fig.add_subplot(1,3,2)
fig_sklearn = fig.add_subplot(1,3,3)
fig_python.set_title('python')
fig_tensorflow.set_title('tensorflow')
fig_sklearn.set_title('sklearn')
fig_python.scatter(x_data, t_data)
fig_python.plot(x_data, x_data*W.ravel() + b, color='r')
fig_tensorflow.scatter(x_data, t_data)
fig_tensorflow.plot(x_data, x_data*weights + bias, color='b')
fig_sklearn.scatter(x_data, t_data)
fig_sklearn.plot(x_data,
x_data*sklearn_model.coef_ + sklearn_model.intercept_,
color='g')
plt.tight_layout()
plt.show()실행 결과 
- 확실히 이전보다는 나아졌지만 tensorflow는 여전히 이상한 것을 알 수 있어요!
- 정규화를 진행하지 않았기 때문!!
- 정규화 진행은 다음 시간에 이어서 알아보도록 해요!
3일차 회고
- Python 구현 부분은 어제보다는 좀 적응되서 나아진 것 같다
- 데이터 분석 과정에서 왠만한 전처리 방법은 다 배웠다고 생각했지만
나의 오산이였다는 것을 오늘 깨달았다. - 이상치 처리와 정규화 방법에 대한 연구가 좀 더 필요한 것 같다
