Few-shot Gaussian Splatting[1] is a recent paper introduced at ECCV 2024. Following the publication of 3D Gaussian Splatting[2] at SIGGRAPH 2023—a groundbreaking work in 3D Reconstruction and Novel View Synthesis—numerous efforts have been made to enhance the model. "FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting" is one of those efforts, introducing methods to improve the performance of 3DGS on sparse inputs.
In this post, I will cover some of the background knowledge necessary to understand this paper, along with the motivations and approaches that FSGS introduces.
Background
For a deeper understanding of FSGS, it's essential to grasp two key concepts: Novel View Synthesis (NVS) and 3D Gaussian Splatting (3DGS).
Novel View Synthesis(NVS)
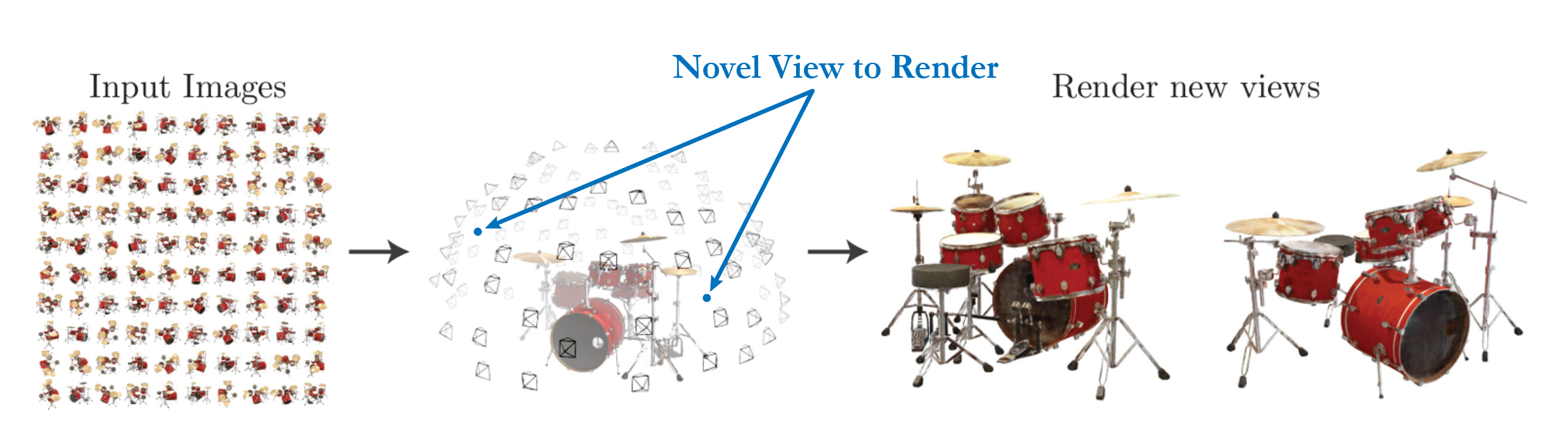
Novel View Synthesis is the task of generating new views or perspectives of a scene using a limited set of input images. It is a core task in the field of 3D vision. Approaches vary, ranging from depth estimation to scene generation, but the goal remains the same: to extrapolate or interpolate between the given viewpoints and predict what the scene would look like from previously unseen angles.
NeRF and 3D Gaussian Splatting
In most cases where NVS is the main task, NeRF[3] and 3DGS become the primary comparison models.
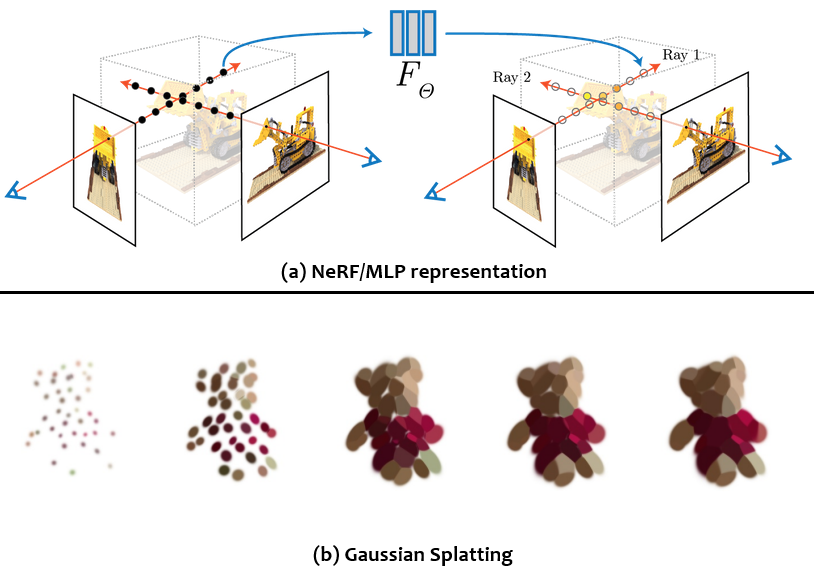
NeRF represents a 3D scene implicitly using a neural network, which relies on density and radiance as key parameters in volumetric rendering. Density controls transparency, while radiance captures color and lighting influenced by the scene’s environment. This allows NeRF to infer the structure and spatial arrangement of objects.
In contrast, 3DGS represents the 3D scene explicitly through elliptic 3D points called 3D Gaussians. Each Gaussian has attributes such as position, size, color, opacity, and directionality. 3DGS takes point clouds as input, which are generated by 2D images beforehand. Those points are simply samples of the surface, with each point containing its own position and color information. Using each point as a center, 3D Gaussians are generated, and their attributes are trained to match the ground truth input images. What makes 3DGS so popular is its ability to perform 3D reconstruction and NVS almost in real-time.
Here, an important question arises: 3D Gaussian Splatting requires sufficient points to represent 3D scene adequately, so what happens if there aren’t enough points to fully capture the scene? Can 3DGS still generate a reasonable representation of the scene under such sparse conditions?
Few-shot 3DGS
Problem Setting
3DGS alone struggles to accurately represent a 3D scene with only a few points to generate the initial Gaussians. Let’s consider the challenges that arise from sparse input. First, with limited inputs, the model has fewer reference views, resulting in a lack of perspective on parts of the scene that aren’t directly visible. This makes depth prediction difficult. Second, the lack of diverse viewpoints means there aren’t enough Gaussians to adequately “paint” the scene.
The authors of FSGS identify two key problems that emerge when applying 3DGS with sparse input:
1. Smooth Texture
With sparse input, 3DGS fails to generate a sufficient number of Gaussians. This results in larger or overly stretched Gaussians (which, under normal conditions, are managed by the "Adaptive Density Control" technique in 3DGS). Consequently, the model fails to capture fine details of the scene, leading to overly smooth textures.
2. Overfitting Propensity
Sparse input also increases the model's tendency to overfit to the training viewpoints. This causes an inaccurate representation of the scene, with Gaussians stretched in the direction of the training views.
Approaches
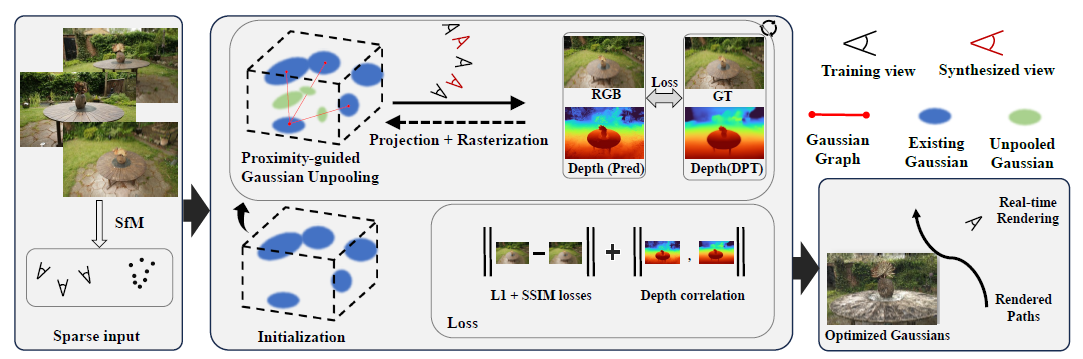
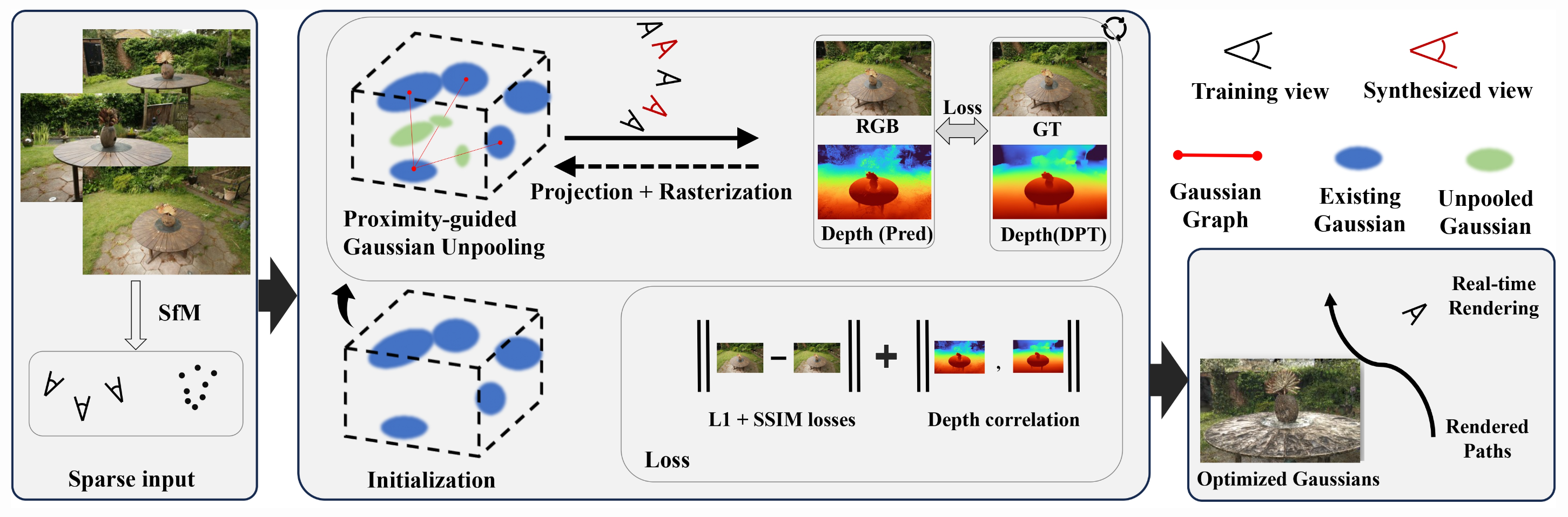
To address the challenges mentioned above, FSGS adopts two main approaches, essentially aiming to generate "more" of the sparse elements: more Gaussians and more images (and consequently, more depth information).
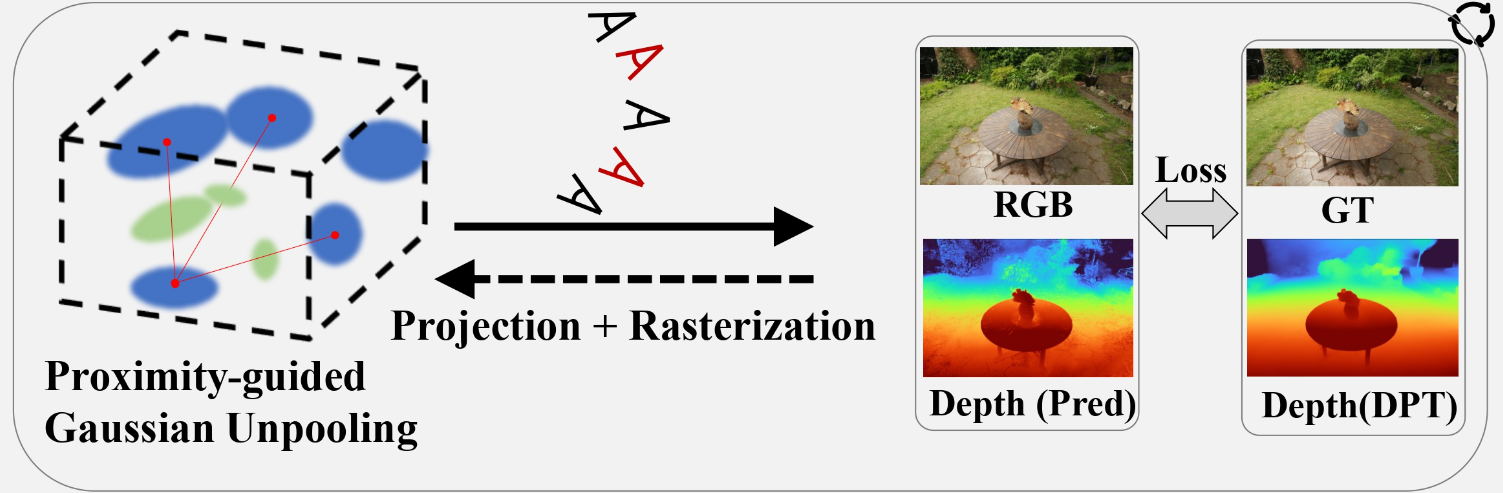
1. Proximity-guided Gaussian Unpooling
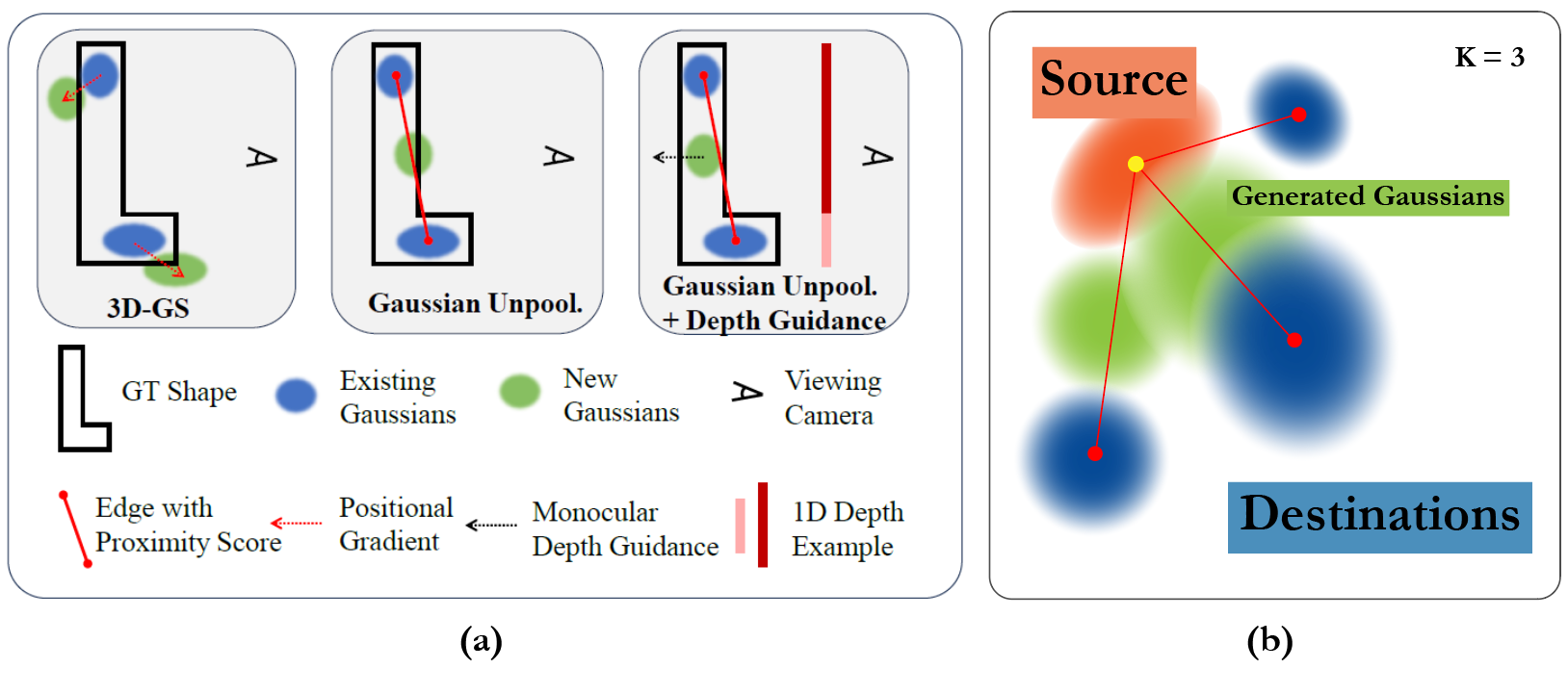
Proximity-guided Gaussian Unpooling is a technique to create additional Gaussians in optimal locations by using a proximity graph. In this method, one of the existing Gaussians is designated as the "Source" Gaussian, and its nearest Gaussians are designated as "Destination" Gaussians. Specifically, the Source Gaussian is the one with the smallest Euclidean distance to the other three Gaussians. By computing the Euclidean distance between the Source Gaussian and each Destination Gaussian, if the distance exceeds a certain threshold, a new Gaussian is generated between the two along the connecting line. The new Gaussian inherits the initial scale and opacity of the Destination Gaussian, while other attributes are initialized to zero.
2. Geometry Guidance for Gaussian Optimization
In this approach, a new view, or "pseudo view," is generated to mitigate the sparseness of the input. This pseudo view is positioned between existing ground truth (GT) viewpoints, and a camera view is generated from this location. The image rendered from this position is used during training. However, since the pseudo view is itself a "predicted" image, FSGS relies on depth information to utilize it effectively.
Depth Map Utilization
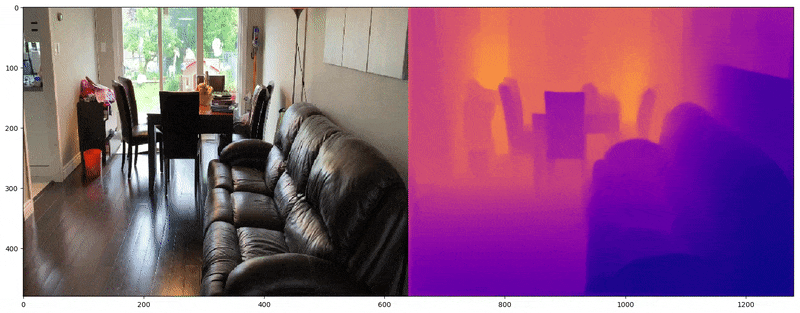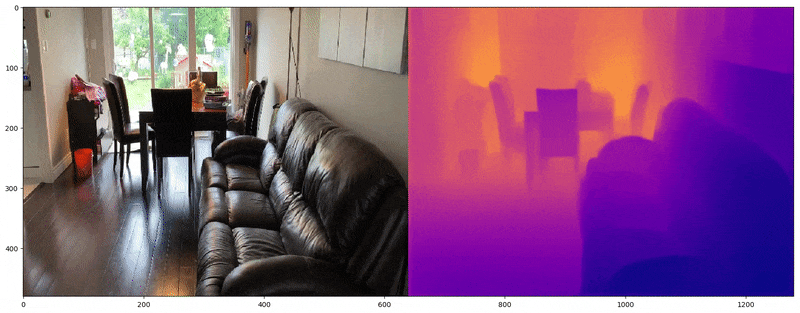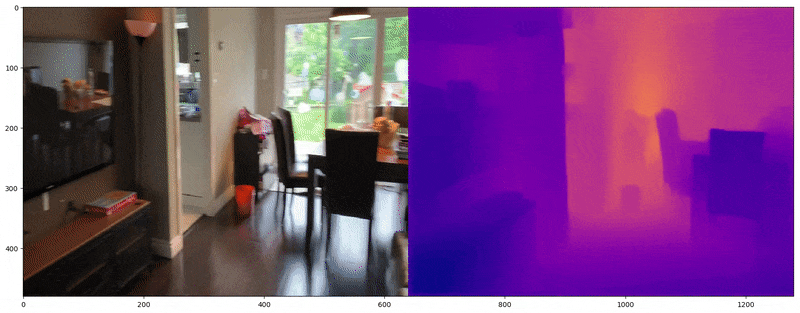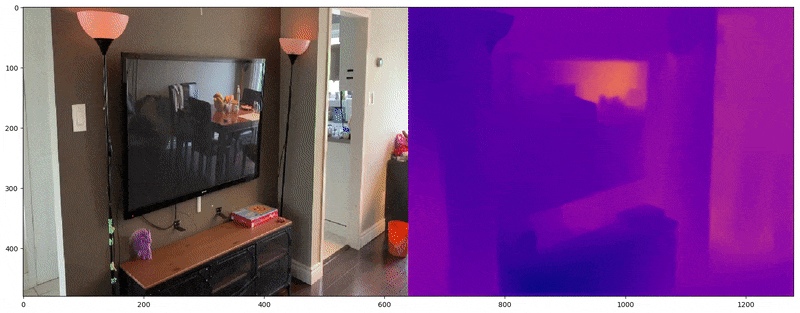
Depth maps provide alpha or RGB representations of spatial depth and are commonly used in computer vision to reconstruct 3D space from 2D images. FSGS leverages depth maps by calculating the correlation between two types of depth data: (1) the depth of rasterized images and (2) the depth derived from 3D Gaussians. These two depths are compared to train the 3D Gaussians in terms of spatial accuracy.
(1) Depth of Input Images
First, for both pseudo view and GT view, Dense Prediction Transformer(DPT)[5] pre-trained with image-depth pair is used to predicts the depth of the images.
(2) Depth Extracted from 3D Gaussians
This depth map, on the other hand, is derived (or rasterized) from the rendered view, which is the output during training. It is generated based on the depth of the scene rendered from the actual 3D Gaussians being trained.
Conclusion
In this post, I covered the development leading to FSGS and its key approaches. The few-shot NVS task remains crucial, as it addresses real-world scenarios where users may not have access to a sufficient number of input images for NVS. The methods proposed by FSGS offer a promising solution to this task while retaining the advantages of 3DGS, including real-time rendering capabilities combined with high model performance.
However, two questions arise with FSGS's approach:
Could there be a better way to initialize generated Gaussians, rather than zeroing out certain attribute values?
Is it stable to train the model using correlations between predicted depth maps? The first is "predicted" by DPT, while the second is generated from the "predicted" Gaussians.
I haven’t shown the experimental results of FSGS, but those who are interested can find more details and results on the FSGS project page[6].
References
[1] Zehao Zhu, Zhiwen Fan, Yifan Jiang, and Zhangyang Wang. 2023. FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting. arXiv [cs.CV]. Retrieved from http://arxiv.org/abs/2312.00451
[2] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 2023. 3D Gaussian splatting for real-time radiance Field rendering. arXiv [cs.GR]. Retrieved from http://arxiv.org/abs/2308.04079
[3] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing scenes as neural radiance fields for view synthesis. arXiv [cs.CV]. Retrieved from http://arxiv.org/abs/2003.08934
[4] Priya Dwivedi. 2019. Depth Estimation on Camera Images using DenseNets. Towards Data Science. Retrieved November 1, 2024 from https://towardsdatascience.com/depth-estimation-on-camera-images-using-densenets-ac454caa893
[5] Ranftl René, Bochkovskiy Alexey, and Koltun Vladlen. 2021. Vision Transformers for Dense Prediction. arXiv [cs.CV]. Retrieved from http://arxiv.org/abs/2103.13413
[6] Zhangyang Wang. FSGS. Github.io. Retrieved November 1, 2024 from https://zehaozhu.github.io/FSGS/
[7] Researchgate.net. Retrieved November 1, 2024 from https://www.researchgate.net/figure/Novel-3D-data-representations-3-6_fig3_381142897
