Motivation & Proposal
| Motivation | Proposal |
|---|---|
| - pre-trained representations의 장점을 다 살리지 못하는 단방향 pre-training | ⇒ 양방향 Pre-training : ELMo와 같은 단순 concat 방식의 양방향이 아닌 “deep Bidirectional” 학습 제안 - MLM + NSP |
| - 특정 테스크들에 있어서 Transformer 구조의 디코더가 정말 필요한가? | ⇒ 디코더 없이도 오토인코더 방식과 양방향 학습을 통한 문맥 학습을 통해 충분히 성능을 내는 방식을 제안 |
| - Task Specific한데다가 크기도 크고 복잡한 구조의 모델들을 대체할 방법은 없는가? | ⇒ 일반화된 pre-trained 모델을 바탕으로 간단하게 fine-tuning 가능한 방식을 제안 |
Model Architecture
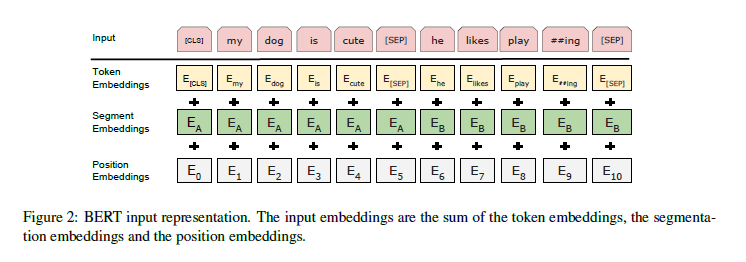
- input embedding은 token embedding + segmentation embedding + position embedding의 합이다.
- 모델 구조는 트랜스포머의 인코더와 동일하되, 인풋의 임베딩이 위 방식으로 커스텀되었으며, 기존 방식과 다르게 position embedding이 학습 가능한 하이퍼파라미터가 되었다.
- Special token으로 두가지가 활용된다:
- [CLS]: sequence의 시작에 오는 토큰으로, 이 토큰에 대응되는 마지막 hidden state는 classification task에서 전체 sequence의 representation으로 해석된다.
- [SEP]: sentence 간의 구분을 위한 토큰으로, 이 토큰을 기준으로 segment embedding을 서로 다르게 적용하여 문장끼리 구분한다.
Pre-training
Pre-training 과정은 비지도 학습으로 이루어지는 두 테스크에 의해 이뤄진다:
-
Masked Language Model (MLM)
: 랜덤하게 인풋의 15%를 [mask]토큰으로 변경한다.
-
Next Sentence Prediction (NSP)
: 여러 다운스트림 테스크들이 두 문장간의 관계에 기반한다. 대표적으로 QA, Natural Language Inference 등이 있다. 하나의 sequence 내 [sep] 으로 구분된 두 문장이 서로 연속적인 문장인지를 파악하는 task이다.
Fine-tuning
Fine-tuning 과정에는 Transformer 기반 아키텍처의 self-attention 메커니즘이 큰 역할을 한다. 한 마디로 말하자면 “인풋과 아웃풋을 적절하게 바꾸는” 방식만으로 fine-tuning이 가능해진다.
텍스트 쌍을 이용한 테스크에서 이전의 fine tuning 방식은 1) 독립적으로 문자 쌍을 인코딩하고 2) 양방향 cross attention을 적용하는 두 단계로 이루어졌다. 그러나 BERT는 self-attention을 활용해 위 두 단계를 통일시킨 접근을 시도한다.
이는 먼저 살펴본 BERT의 인풋 구조가 text pair을 concatenate 해서 하나의 sequence로 받고, 여기에 self-attention이 적용됨으로써 사실상 두 문장 간 양방향 cross attention을 적용하는 것과 마찬가지의 효과를 내기 때문이다.
다운스트림 테스크별로 하나의 쌍으로 묶이는 sentence pair은 다음과 같이 구분된다:
-
Paraphrasing (동일한 의미인지 아닌지 파악)
-
Entailment (가설 - 전제 관계 여부 파악)
-
QA
-
단일 문장 (text - )
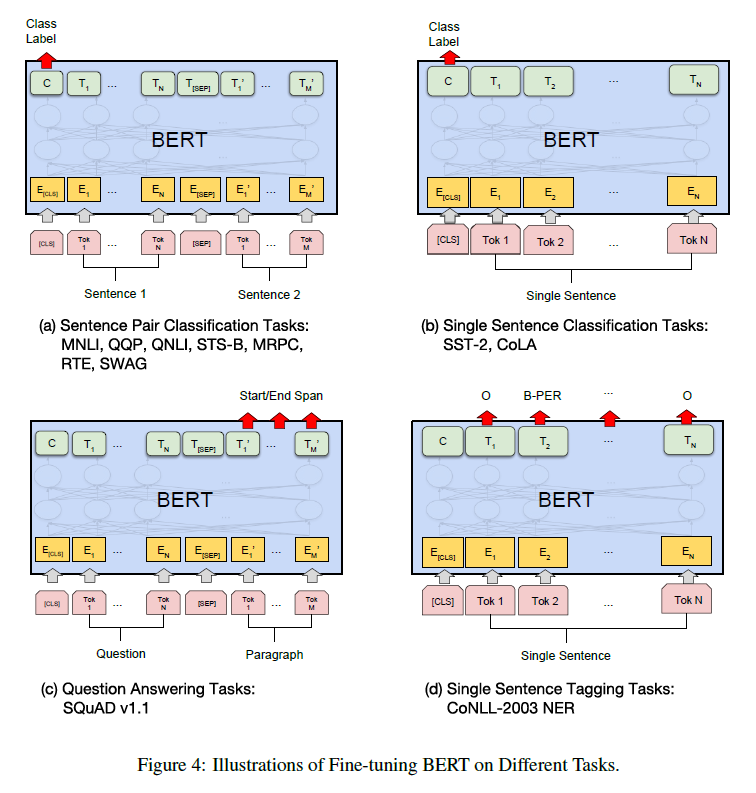
또한 논문에서는 네 종류의 다운스트림 테스크에 어떻게 BERT가 fine-tuning 될 수 있는지를 보여준다:
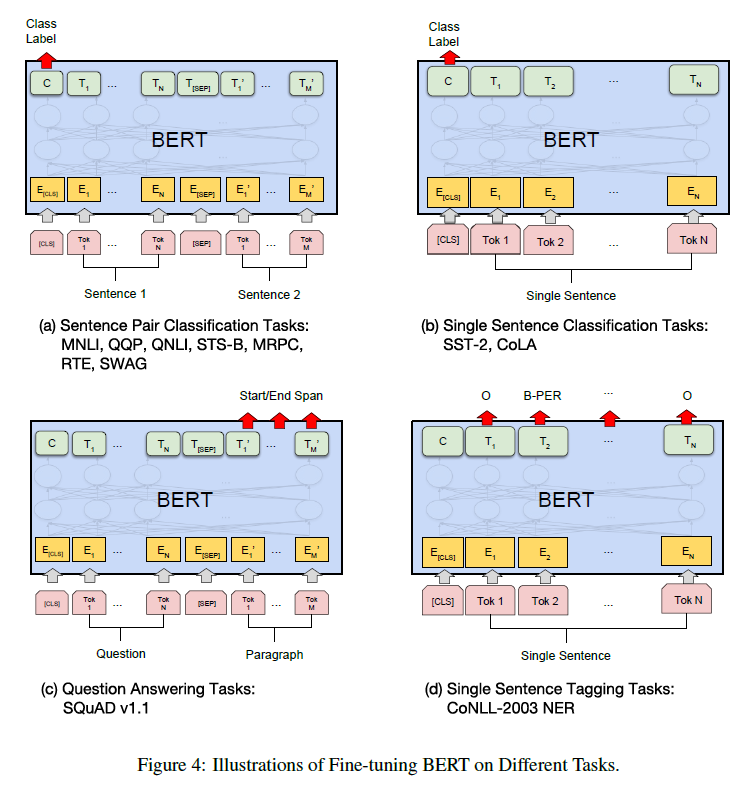
-
Sentence Pair Classification
- Entailment Classification Task (3 classes are entailment, contradiction, neutral)
- Natural Language Inference Task
- Paraphrasing Task
-
Single Sentence Classification
- 언어학적으로 말이 되는 문장인지 아닌지 판별
- 감정분석
-
Q&A
-
Sentence Tagging (문장 내 단어들을 분류, e.g., Person, Location,…)
이 네가지 테스크는 다시 Sequence-level task인지, Token-level task인지 아니면 Q&A인지에 따라 입출력 형태가 조금씩 다른데, (a), (b)는 Sequence-level task로 [cls] 토큰의 마지막 hidden state가 classification layer에 입력으로 들어가게 된다.
Token-level task인 (d)의 경우 각 토큰의 마지막 hidden state의 출력값이 해당 토큰에 대한 예측값이 된다는 점에서 앞의 구조와 달라진다.
Q&A task의 경우, 입력에서 질문과 답변이 [sep]으로 구분된 하나의 sequence로 임베딩되고 출력에서 BERT는 sequence 내에서 답변이 시작하는 위치와 끝나는 위치를 예측하게 된다. 이 때 예측은 각 토큰마다 답변이 시작하거나 끝날 가능성을 점수화하여 이뤄진다.
References
