* Distributed Representations of Words and Phrases and their Compositionality
Background Knowledge
- Word Representations 모델 : 단어를 고차원 벡터 공간에 mapping 하여 수치적으로 표현하는 방법. 단어 간의 유사성과 관계를 표현하는 것을 가능하게 해 주고, 단어의 의미를 정량적으로 다루는 것이 가능하도록 함.
- Syntactic relationship과 Semantic relationship:
- n-gram: 연속된 n개의 단어 혹은 문자 시퀀스
Abstract
Motivation
- 기존의 연속적 Skip-gram 모델의 강점은 syntactic, semantic relationship을 포착하는 높은 수준의 distributed vector representation을 학습하는 효율적인 도구라는 것.
- 예를 들어, “king”-”queen”, “man”-”woman” 등의 단어 쌍은 벡터 공간 내에서 비슷한 관계를 갖도록 학습됨
- 그러나 idiomatic expression 이나 복잡한 phrases를 파악하는 것은 어려움.
- 본 논문의 초록에 제시된 예시처럼, “Canada” 와 “Air”이 결합되어 “Air Canada” 라는 새로운 의미를 가지는 단어를 제대로 반영하짐 못하는 경우가 예시가 될 수 있음.
- 또한 단어의 순서를 파악하는 것이 어려움.
Proposal:
- 자주 등장하는 words의 subsampling
- 학습 속도의 개선 효과
- 더 정규화된 단어 표현을 학습 가능하게 됨
- hierarchical softmax 대신 negative sampling 적용
- 학습 속도 개선
- 자주 등장하는 단어에 대해 더 나은 벡터 표현을 얻을 수 있음
Introduction
Research Background
NLP task에 있어서 distributed word representations는 유사 단어를 grouping하는 방식으로 성능 향상에 있어 중요한 작업으로 연구되어 왔지만, 초록에서 설명했듯 몇가지 해결해야 할 사항들이 존재했기 때문에 저자들은 이를 skip-gram이라는 word representations 모델을 확장하는 접근으로 개선하고자 하였다.
신경망을 이용한 word representations는 언어학적 규칙과 패턴을 명시적으로 인코딩한다. 저자들은 이런 패턴 중 상당수가 linear translation으로 표현 가능하다고 설명하는데, 예를 들어 vec(“Madrid”) - vec(“Spain”) + vec(“France”)는 다른 word 벡터들보다 vec(“Paris”)에 가깝다.
언어학적 규칙과 패턴은 정말 선형 변환으로 '잘' 표현될까?- 이후의 연구에서 이런 식의 선형 변환이 제대로 작동하려면, 수식을 계산한 결과 벡터와 가장 가까운 벡터를 찾을 때 vec(”Madrid”)를 제외해야 원하는 결과가 나올 수도 있다는 점이 지적되었다.
- 왜냐? 위 수식과 같은 단순 선형 변환의 결과는 vec(”Paris”)보다도 vec(”Madrid”)에 더 가까운 경우가 존재한다. 이는 실제 의도한 단어간 관계를 제대로 반영하지 못하는 상황이기 때문이다.
- 이를 비롯한 단어에서의 이런 선형 벡터 변환이 일관적이지 않고, Train data의 편향된 정보에 의존한 데에서 기인한 것일지도 모른다는 문제가 지적되었다.
- 또한 word representations에서 단어는 ‘고차원’ 공간으로 매핑되기 때문에, 고차원 공간에서 이러한 방식의 선형 변환만으로 word 벡터간의 관계를 설명하는 것은 지나친 단순화이며 복잡한 의미 표현과 언어 관계를 포착하지 못한다는 문제 역시 지적되었다.
Approaches: Modification of original Skip-gram model
- Sub-sampling of frequent words
- NEG as a simplified variant of Noise Contrastive Estimation(NCE)
- Word based ⇒ Phrase based model
- Identify large number of phrases with data-driven approach
- One phrase = One token During training
- Evaluate with a test set of analogical reasoning tasks containing both words & phrases
The Skip-gram Model
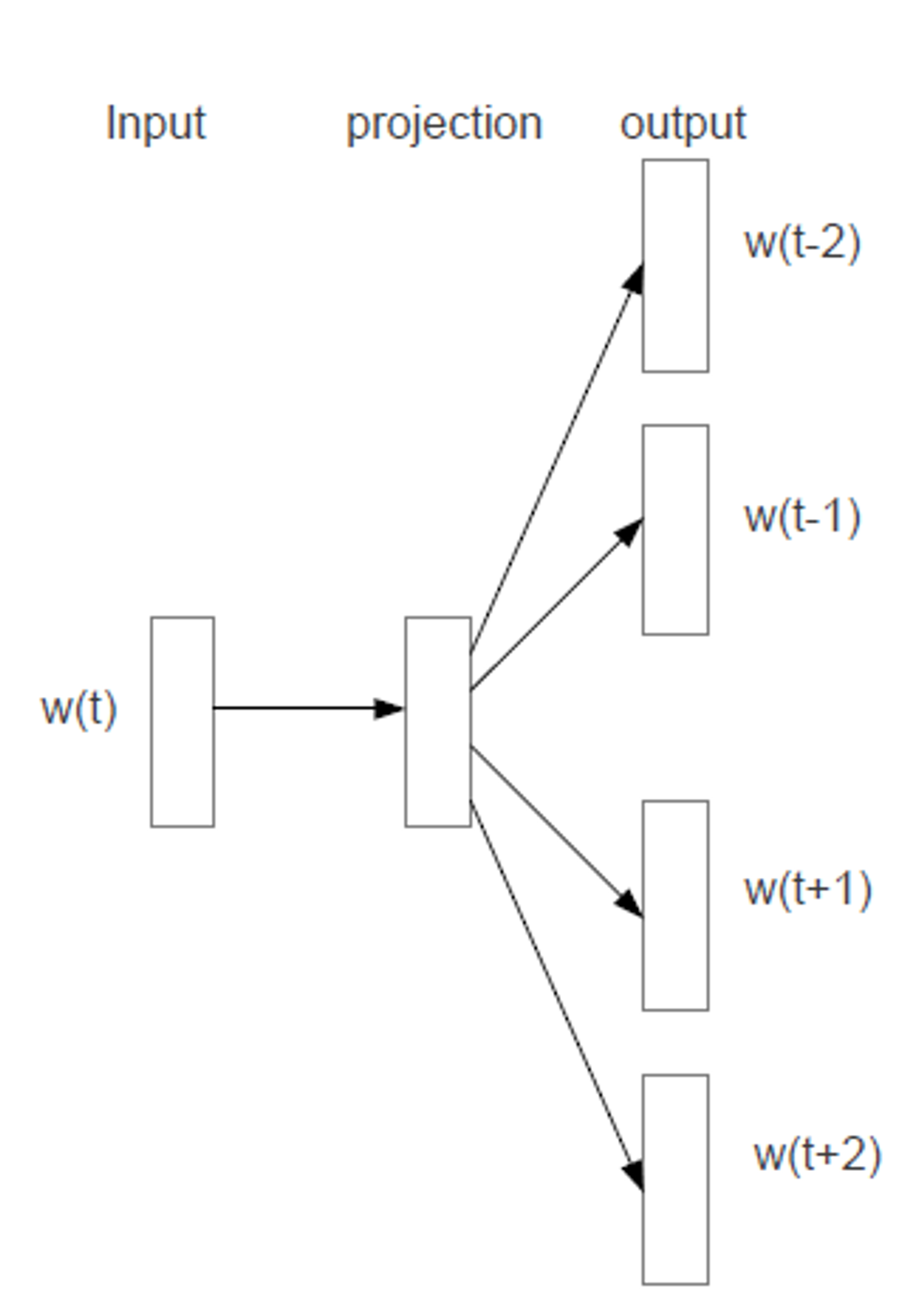
Architecture
1) word: mapped vector 로 이루어진 dictionary를 만든다.
2) input은 center word가, output은 context word가 된다. 이 때 sliding window를 사용하여 window size = 일 때, center word 앞 뒤 개, 총 개의 단어가 context word로 학습, 예측된다.
3) Dataset 구성은
로 구성된다.
4) 각각의 train sample은 classification task가 된다. (한 x에 대해 매우 많은 단어들 중 가까운 단어를 고르는 task가 되기 때문)
예를 들어 보자. “The cat sat on the mat” 이라는 문장에서 “sat”을 center word라 하고 c=2라 하면 다음과 같은 Train Set을 만들 수 있다:
X Y sat The sat cat sat on sat the 이 때 위의 모델 구조에서 = “sat”이고, output에 각 Y의 단어들이 들어가게 된다.
The Objective of the original Skip-gram
기존 Skip-gram 모델의 Opjective는 “to maximize the average log probability” 이다:
이 때의 c는 window size가 된다
이 때 는 softmax function에 의해 다음과 같이 정의된다:
와 는 각각 에 대한 “input” 과 “output” vector representations 이고, 는 단어 vocabulary set 안의 전체 words의 수이다. 이렇게 정의되는 확률값은 매우 큰 에 의해 gradient 계산에 드는 cost가 커진다는 문제가 존재한다. 따라서 저자들은 NCE를 간소화한 Negative Sampling 방식을 이용하여 새롭게 objective function을 정의한다.
The New Objective of the Skip-gram
이 목적 함수는 실제 vocabulary 내의 단어인 positive example과 vocabulary 밖의 연관이 없는 negative example에 대한 두 항으로 분류하여 살펴볼 수 있다.
먼저 positive example에 대한 항으로, 벡터 와 의 내적에 의해 나타난 두 벡터의 유사성에 를 취하여 확률값으로 변환하고, 이에 로그를 취하였다.
이는 maximize 해야 하는 값이 된다.
negative example에 대한 항으로, 벡터 와 의 내적에 의해 나타난 두 벡터의 유사성에 를 취하여 확률값으로 변환하여 로그를 취하고, 이의 기대값을 모든 negative sample에 대해 합산하였다.
- 는 샘플링할 negative sample의 수, 는 noise 분포 로부터 샘플링된 를 의미한다.
이는 minimize해야 하는 값이 된다.
위에서 사용한 예시인 “The cat sat on the mat” 라는 vocabulary를 살펴보자. 첫번째 항에서는 예를 들어 “sat”과 “cat” 단어의 벡터가 서로 근접하게 위치하도록 학습을 진행한다. 반면 두번째 항에서는 “sat”과 무관한 “car”과 같은 단어의 벡터간 거리가 서로 멀어지도록 학습을 진행하게 된다.
이 때 논문의 저자는 noise 분포 를 unigram distribution 로 맞추었을 때 모델 성능이 가장 뛰어났다고 추가하고 있다.
Unigram
: 자연어 처리(NLP)에서 텍스트를 분석할 때 사용하는 기본적인 개념 중 하나로, 단어의 빈도 또는 확률을 개별적으로 계산하는 방법. 문장을 단어들의 시퀀스(sequence)로 보고, 각 단어가 독립적으로 발생한다고 가정
- Unigram 분포
: 말뭉치(코퍼스) 내에서 각 단어가 등장하는 빈도를 기반으로 그 단어의 확률을 계산하는 분포. 예를 들어, 코퍼스 내에서 "cat"이라는 단어가 100번 등장하고, 전체 단어 수가 10,000이라면 "cat"의 unigram 확률은
- Negative sampling, 언어 모델 기본 형태 등에 사용됨
- 왜 그럼 Word2Vec에서 3/4제곱을 곱할까? 자주 등장하는 단어의 샘플링 확률을 낮추는 것.
Subsampling of Frequent Words
- 매우 자주 등장하는 관사, be동사, 혹은 전치사 등과 같은 단어는 정보량은 적은데 자주 등장하므로 모델 학습 속도를 저하시킬 수 있다. 또한 중요한데 등장 빈도가 낮은 단어들의 학습을 방해할 수 있다.
- 이에 Subsampling (일부를 무시함)을 적용하여 문제를 해결하고자 시도하고 있다.
는 임계값으로, 다음 수식에서는 단어 가 등장할 확률 에 따라 그 단어를 subsampling할 확률을 계산한다.
Empirical Results
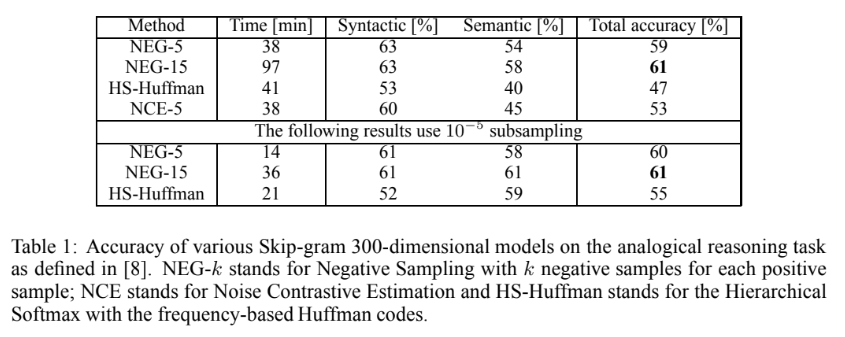
- 평가 기준은 학습 시간과 Syntactic, Semantic, 그리고 전체적인 Total Accuracy로 구성되었다.
- Table 에서 확인할 수 있듯, NEG가 가장 높은 정확도를 보였고 subsampling과 결합하였을 때 가장 좋은 성능을 보였다.
- NEG의 파라미터 는 15일 때 가장 좋은 결과를 보였다.
- high frequency 단어에서 subsampling은 training speed를 2~ 10배까지 개선시켰다.
- 평가방식: 단어 유추(analogical reasoning) 작업을 사용하여 모델 성능을 평가했다.
- e.g., "Germany : Berlin :: France : ?"와 같은 유추 문제를 통해 단어 벡터 간의 관계를 평가
Learning Phrases
이 챕터에서는 단어 벡터를 넘어 phrases의 벡터 표현을 학습하는 방법을 설명한다. Phrases는 단순한 단어의 의미 결합 이상으로 새로운 의미를 가지게 되기 때문에 기존의 단어 임베딩 기법만으로는 이러한 phrases를 잘 표현하기 어렵다는 문제가 존재한다. 따라서 저자들은 다음과 같은 과정으로 Phrases의 vector representation을 학습한다:
-
Data-driven Approach
: 단어의 unigram 과 bigram 빈도를 활용하여 자주 함께 나타나는 단어 쌍을 구로 인식하고 학습에 포함시키도록 한다. 두 단어가 함께 등장하는 빈도를 각 단어가 독립적으로 등장하는 경우(독립성)와 비교하여 score을 결정한다.
-
: 단어 와 가 연속적으로 나타나는 횟수 (=bigram frequency)
-
: 각 단어가 개별적으로 나타나는 빈도의 곱
-
: discounting coefficient. 저빈도로 나타나는 단어 쌍이 구로 형성되는 것을 막는 파라미터
⇒ : 두 단어가 phrase로 형성될지 여부를 결정하는 점수로, 임계값 이상의 score을 얻은 두 단어는 phrase로 인식될 가능성이 커진다.
-
-
Training
: 선택된 phrase 들을 각각 하나의 토큰으로 취급하여 Skip-gram 모델에서 학습시킨다.
이러한 과정을 통해서 phrases에 대한 vector representation을 진행하고 나면 다시 analogical reasoning을 통해 모델 성능을 평가한다.
- e.g., "Montreal" : "Montreal Canadiens" :: "Toronto" : "Toronto Maple Leafs” 와 같은 prediction task를 통해 모델을 평가
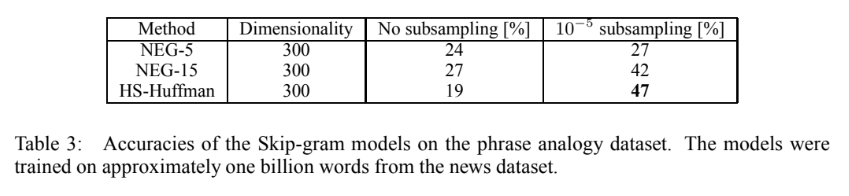
- subsampling이 없을 때는 k=15인 NEG가 가장 높은 성능을 보였으나, subsampling을 적용하였을 때 Hierarchical Softmax의 성능이 크게 향상되었다.
- 이후 dimensionality를 1000으로 높인 33,000,000,000개의 단어로 구성된 데이터셋이서 Hierarchical Softmax를 활용하여 72%까지 accuracy를 높일 수 있었다.
-
NEG: 단어의 출현 확률을 직접 계산한다기 보다 “관계”의 학습에 적합하다. 계산량이 크게 줄어든다는 장점이 있으나 더 간단한 계산에 성능이 좋고 (정밀한 확률 계산을 하지 않기 때문에) 낮은 빈도로 나타나는 단어에 대해서 학습이 잘 이뤄지지 않을 수 있다.
-
Hierarchical Softmax: 이진트리 구조를 활용한 확률 계산이 이뤄진다. 마찬가지로 계산 효율성을 높일 수 있는 방법으로 제시되면서 동시에 확률 계산이 더 정밀하다.
⇒ Phrase의 경우 등장 빈도가 높지 않은 단어들이 존재하고 (예: Air Canada) 계산의 복잡도가 조금 더 높다. 따라서 일반적인 word representation에서는 NEG가 성능이 더 높게 나오더라도 Phrase 학습에 있어서 HS가 더 높은 성능이 나올 수 있었던 것으로 추측된다.
원래 Softmax 함수는 대규모 vocabulary를 다룰때는 계산 효율이 낮다. 따라서 Softmax보다 계산 효율성을 높일 수 있는 방법으로 1) NEG 2) HS를 제시한 것.
NEG 와 Hierarchical Softmax는 둘 다 원래 Softmax를 사용하는 것보다 계산 효율성의 측면을 보완해주는 방법이라는 공통점이 존재한다.
Bigram
: 텍스트에서 두 단어가 연속적으로 나타나는 경우. 일반적으로 두 단어의 조합이 자주 나타나는지, 그리고 의미있는 조합인지 분석을 위해 활용됨
- Unigram과 달리 단어 간의 문맥적 관계를 파악 가능
⇒ 더 정교하게 language modeling이 가능
Additive Compositionality
이 챕터에서는 위에서 언급했던 단어와 phrases의 vector representation이 선형적으로 결합이 가능하다는 성질에 대해 설명한다. 저자들은 간단한 벡터 덧셈이 복잡한 의미를 구성하는 것이 가능하다는 점을 보인다.

- 테이블에서와 같이 Czech + currency를 더했을 때 이 벡터는 같은 행의 네 단어 “koruna”, “Check crown”, “Polish zolty”, “CTK” 와 가장 가장 가까웠다.
이러한 연산이 가능한 이유는, 단어 벡터가 softmax 함수의 입력에 선형적으로 연결되어 있기 때문에 벡터 간 합이 두 단어의 context 의 분포의 곱과 유사한 결과를 나타내기 때문이라고 저자들은 설명한다.
이러한 발견은 복잡한 언어의 의미 관계를 간단한 벡터 연산으로 환원할 수 있다는 점에서 의의가 있는데, 긴 텍스트를 벡터화 할 때 유용할 수 있다.
Analogical Reasoning vs. Additive Compositionality
- Analogical Reasoning은 ‘유추’ 능력이 핵심. 예를 들어 A → B 라면 C → D 이런 관계에서 벡터의 선형 변환을 통해 vec(”B”) - vec(”A”) + vec(”C”) 가 vec(”D”)에 가까운지를 확인하는 방식. ‘더’ 복잡한 의미 구성을 목적으로 하지는 않음
- Additive Compositionality는 벡터 간 연산을 통해 새로운 의미 구성에 초점을 맞춤. 복잡한 의미 구성이 목적임. 예를 들어 앞선 Table 5.에서처럼 “Czech” + “currency”라는 벡터의 덧셈을 통해 “koruna”를 도출하는 것이 목적
Comparison to Published Word Representations
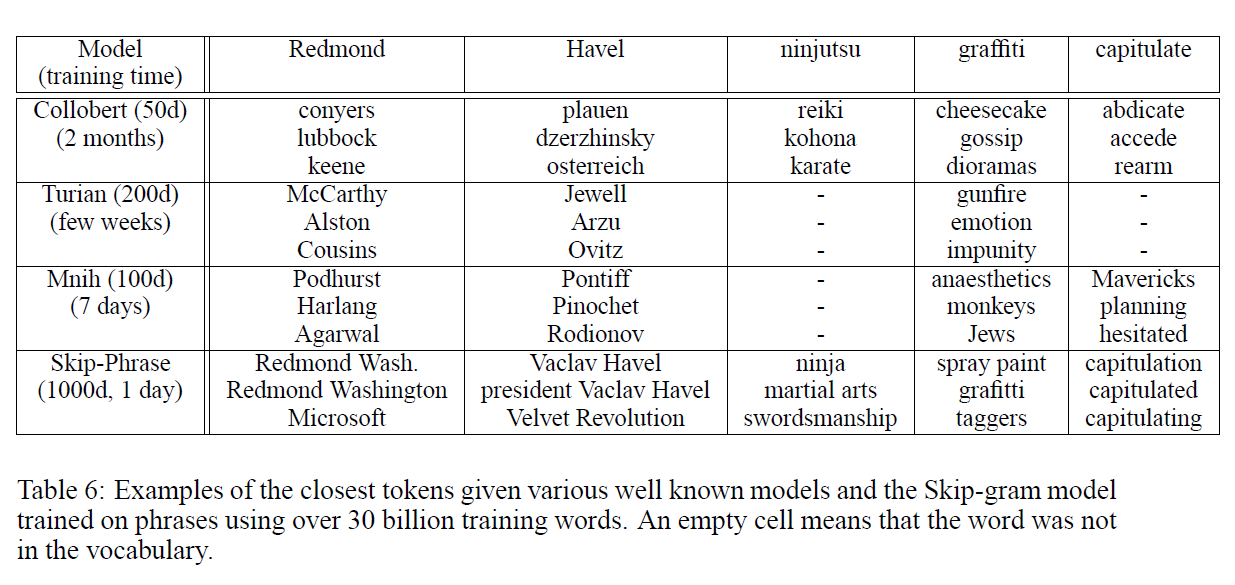
- 기존의 다른 word representations 모델들과 저자들의 보완된 Skip-gram을 비교.
- 평가 기준은 analogical reasoning
- 대규모 모델에서 Skip-gram의 성능이 큰 차이로 가장 우수했음.
- 드문 단어에 대해서도 비교적 정확한 추론이 이루어짐.
- 더 큰 데이터셋으로도 기존 모델들보다 Training에서 효율성이 높았음.
Conclusion
Contributions
- Model Accuracy & Training Speed:
- improved model architecture
- subsampling of the frequent words
- Negative sampling algorithm
- Phrase Representation:
- phrase to a single token
Note
- Training algorithm과 하이퍼파라미터의 선택은 task specific 하다.
- Crucial decisions that affect the performance of the model:
- the choice of the model architecture
- the size of the vectors
- the subsampling rate
- the size of the training window
