
버블 정렬
정의
이웃한 두 원소의 대소 관계를 비교하여 필요에 따라 교환을 반복하는 알고리즘
설명
무작위로 나열되어 있는 배열이 있고, 해당 배열을 순차적으로 정렬하고자 할 때 쓰이는 알고리즘 기법 중 하나다.
배열에 서로 인접한 두 원소들의 관계를 비교하여 교환만 해주는 알고리즘으로, 아래 그림을 보면 쉽게 이해할 수 있다.
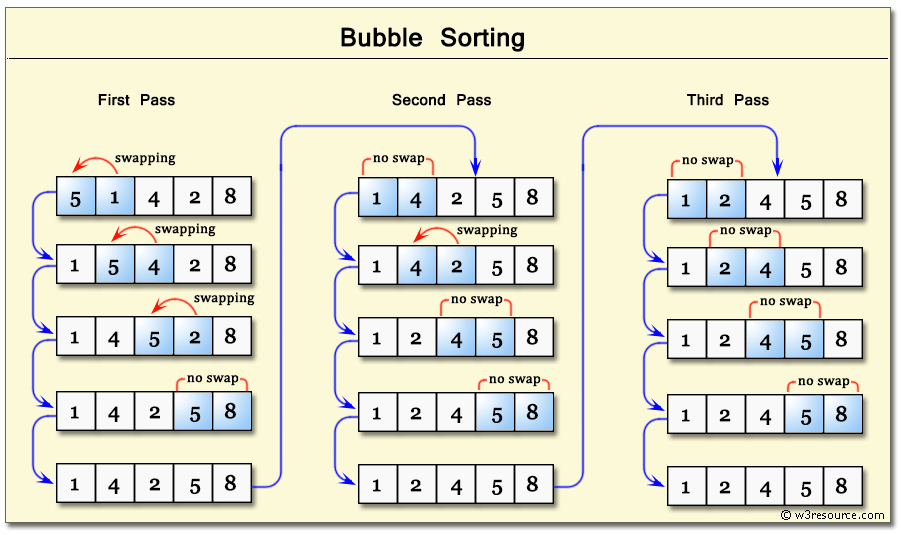
배열 [5, 1, 4, 2, 8]을 오름차순으로 정리하고자 한다면, 서로 붙어있는 두 인자들의 크기를 비교하여 왼쪽 인수가 오른쪽 인수보다 크다면 순서를 바꾸고 반대라면 그대로 놔두면 된다.
예를 들어 위 그림처럼 0번 원소인 5와 1번 원소인 1을 비교할 때, 5가 1보다 크므로 서로 바꿔주면 된다.
그 다음 1번 원소인 5와 2번 원소인 4를 비교하고..
..
..
이런 방식으로 꾸준히 이어나가면 결국 가장 오른쪽에는 제일 큰 숫자가 나열하게 될 것이고, 이제 다시 같은 방식으로 n-1번 반복하면 되는 것이다.
영상으로 보면 아래와 같이 확인할 수 있다.
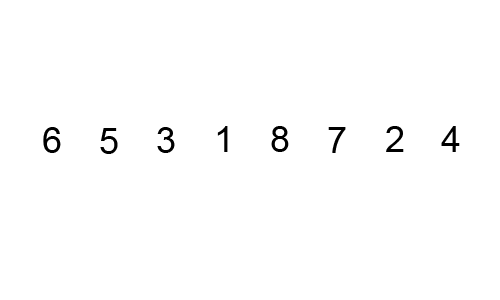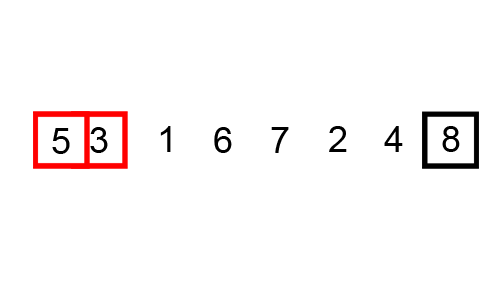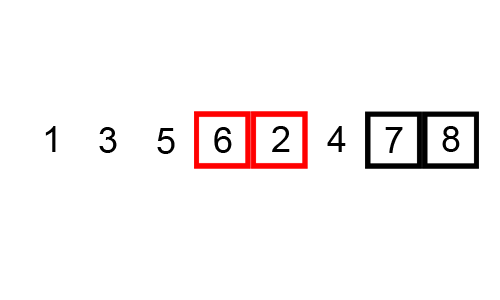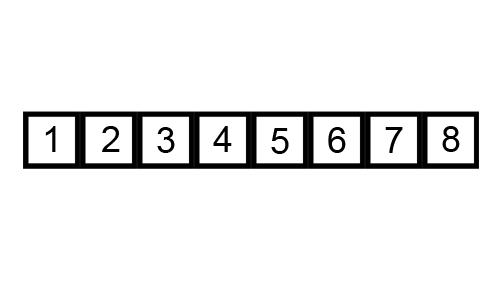
단순 교환 정렬 이라고도 불리는데, 개인적으로 버블 정렬보다 더 직관적인 네이밍이 아닐까 싶다.
코드
기초 구현 코드
위와 같은 방법으로 버블 정렬로 구현하자면 아래와 같을 것이다.

i=0, j=0인 첫번째 조건을 통해 배열 내 제일 큰 숫자가 제일 오른쪽으로 옮겨질 것이고
이후 그 전의 배열까지 다시 반복하는 조건이다.
위 코드를 통해 배열 [6, 2, 9, 1, 5, 3]을 버블정렬 시켜보면..


역순
반대로 배열의 오른쪽에서부터 왼쪽으로 진행하여, 배열 내 제일 작은 숫자가 왼쪽으로 옮겨지게 할 수도 있다.
코드로 구현하자면 아래와 같다.

알고리즘 개선
개선 #1
[2, 3, 4, 5, 1]이라는 배열이 있다고 생각해보자.
역순으로 진행하는 위 알고리즘을 사용해 오름차순 정렬을 하면 처음 pass때 바로 [1, 2, 3, 4, 5]와 같이 정렬될 것이고, 거기서 정렬은 끝난다.
하지만 알고리즘은 이 정렬이 끝난 것인지 모르므로 코드가 끝날 때까지 교환 가능 여부를 판단할 것이므로 비효율적일것이다.
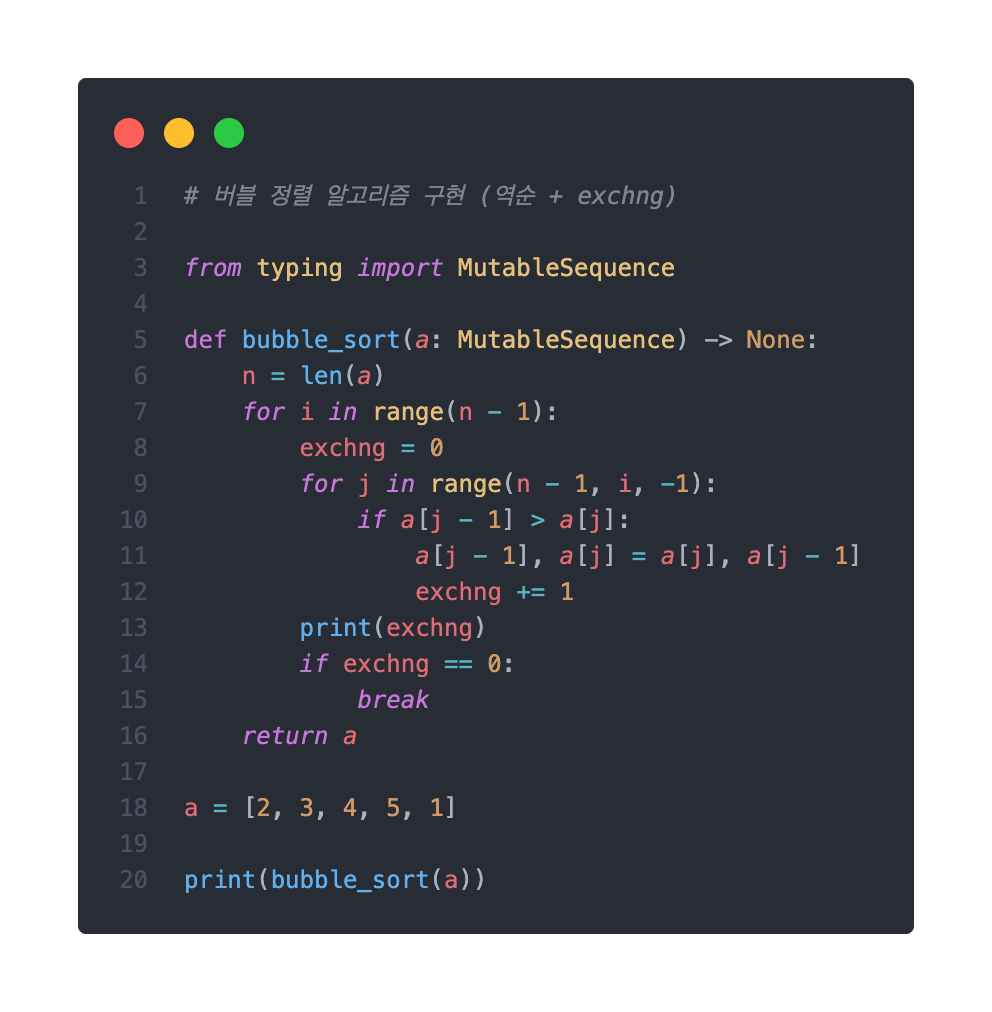
이를 개선하기 위해 한 pass에서 진행된 교환 횟수를 알려줄 변수 하나를 지정하고, 이 변수가 0이 되는 pass에서 바로 함수를 break시키면 될것이다.
이를 코드로 구현하면 아래와 같다.

위 알고리즘에 [2, 3, 4, 5, 1]을 대입해본다면,
첫번째 교환 과정에서 교환이 4번 일어날 것이고(마지막 원소 1이 첫번째로 오는 과정),
두번째 교환 과정에서는 교환이 일어나지 않으므로 함수가 종료될 것이다.
위 알고리즘으로 생각해본다면,
첫번째 pass에서 exchng=4가 될 것이고, 두번째 pass에서는 exchng=0이 되고 함수가 종료될 것이다.
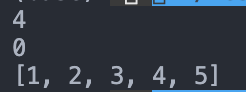
정확하다!
개선 #2
[1, 3, 9, 4, 7]이라는 배열이 있다고 생각해보자.
이를 역순 버블 알고리즘을 사용하여 오름차순으로 나열하고자 할 때,
첫번째 pass에서 [1, 3, 4, 9, 7]이 만들어질 것이다.
근데 여기서 0~2번째 배열인 1, 3, 4는 이미 오름차순이름으로 배열됐으므로 여기를 한번 더 거쳐가는 것은 비효율적일 것이다.
각 pass에서 교환이 이루어졌을 때를 저장해둘 임의의 변수를 만들고, 이를 다음 pass에서 써먹으면 된다.
정리하자면 아래와 같다.

변수 last는 각 패스에서 마지막으로 교환한 두 원소 가운데 오른쪽 원소인 a[j]의 인덱스를 저장한다.
교환할 때마다 오른쪽 원소의 인덱스값을 last에 대입하고, 하나의 패스를 마친 시점에 last의 값을 k에 대입하여 다음에 수행할 패스의 스캔 범위를 a[k]로 제한하는 것이다.
이렇게 된다면 다음 패스에서 마지막으로 비교할 두 원소는 a[k]와 a[k+1]이 되는 것이다.
배열 [1, 3, 9, 4, 7]을 위 코드에 대입해본다면,
첫번째 pass가 이루어지는 방향은 아래와 같다.
for j in range(4, 0, -1):
if a[3] > a[4] (x) # j=4일 경우 if문 실행x
if a[2] > a[3] (o) # j=3일 경우 if문 실행o
# 이때 배열은 [1, 3, 4, 9, 7]로 변경이 되고 last=j=3
if a[1] > a[2] (x) # j=2일 경우 if문 실행x
if a[0] > a[1] (x) # j=1일 경우 if문 실행x
# 첫번째 pass가 끝났을 때 배열은 [1, 3, 4, 9, 7]이고 k=last=3의 값을 가진다.
# while 3<4이므로 for j in range(4,3,-1)이 실행되여 배열의 4번째 원소와 5번째 원소에 알고리즘이 실행된다 (배열의 1~3번째 원소 무시)
Take Away
두번째 개선안은 어렵다..
버블 정렬과 변수 exchng를 사용하는 첫번째 개선안까지는 완벽히 이해했고 제로부터 다시 하라면 할 수 있을 것 같다.
하지만 이미 완성된 배열을 제외하는 두번째 개선안은 이해가 어려워 계속 헤맸던 것 같다. 솔직히 아직도 이해는 잘 안된다. (어떤건지는 알겠지만 와닿지는 않는?)
일단 버블 정렬의 기초개념부터 이해하고 제대로 써먹게되고 났을 때 개선 방안들을 차근차근 적용해보는 방향으로 가야할 듯 싶다..
버블 정렬 5분만에 이해하기
아래 영상을 보면 버블 정렬을 바로 이해할 수 있다!!
