Overview
- LLaMA 7B로 임베딩 기반 검색 모델 훈련
작은 인코딩 모델 (Encoder 기반)에 비해서 큰 모델로, 성능 향상 - 또한 Encoder보다 Max Length가 길어 Long input을 처리 가능 (Decoder = 2048, 4096)
- 코드가 공개되어있음
- 논문링크
Method
- Retriever과 Rerank로 나누어져있음
Retriever(RepLLaMA)
- Query를 주면 관련된 Document를 검색하는 Task
- 일반적인 bi-encoder dense retriever DPR과 유사한 패러다임 활용
- BERT DPR에서는
[CLS]토큰 임베딩 활용 - LLaMA에서는
[CLS]를 활용할 수 없으니 비슷하게[EOS]를 활용
- BERT DPR에서는
- 따라서 Query/Document 뒤에
</s>(EOS)을 추가함
그 후 각 입력토큰 (</s>)까지의 last hidden layer (마지막 레이어 토큰 표현을 반환) - 그 후 dot product을 활용해서 유사도를 계산함
Training Loss
- DPR과 비슷하게 In-batch-negative 활용함
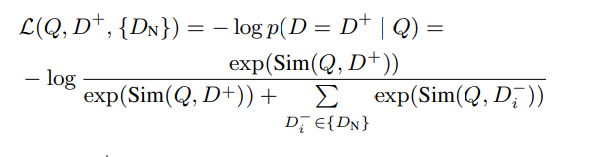
Rerank(RankLLaMA)
- Query와 검색된 Document가 주어지면 다시 Document를 재정렬하는 Task
- Query와 Document가 Input으로 주어지면 두 개 사이의 관련 Score가 나올 수 있도록 훈련
- input:
query:{Q}, document: {D} </s> - output:
sim(Q,D) = Linear(Decoder(input)[-1])
- input:
- Training은 위의 RepLLaMA와 동일하게 진행
Experiment
Dataset
- Retriever, Reranker 모두 MSMARO 데이터 셋으로 훈련
- MSMARCO는 Query와 Positive documents, negative documents로 이루어져 있음
Implementation Details
- LLaMA-2-7B 활용
- Lora, FA2(Flash-attention)으로 메모리 효율적으로 훈련
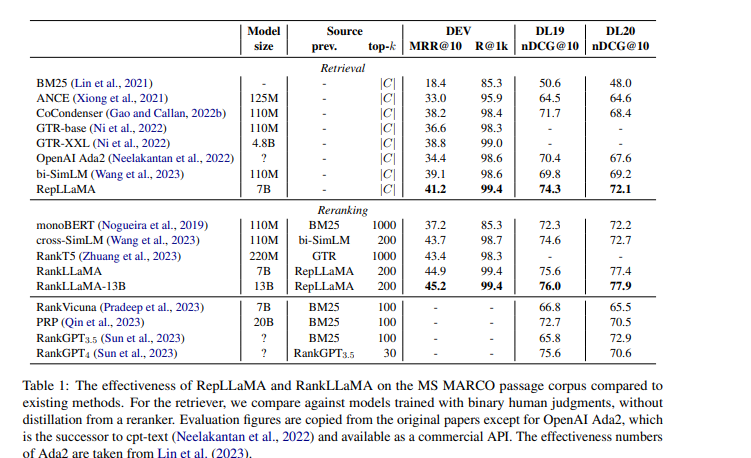
Result
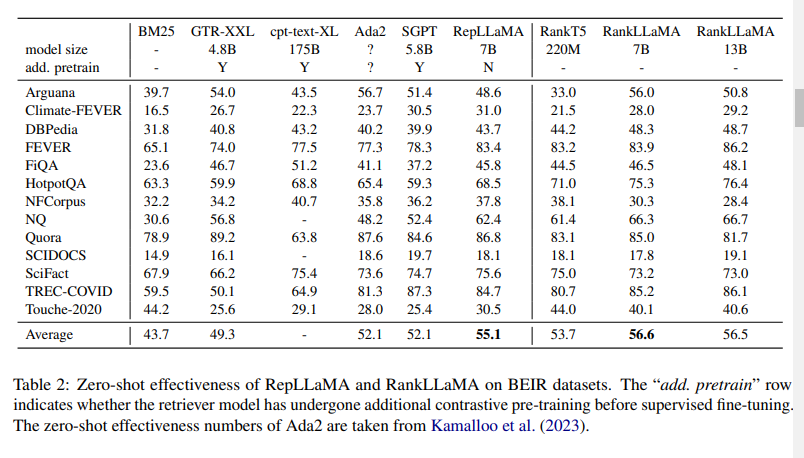
- 제로샷에서의 성능도 좋음