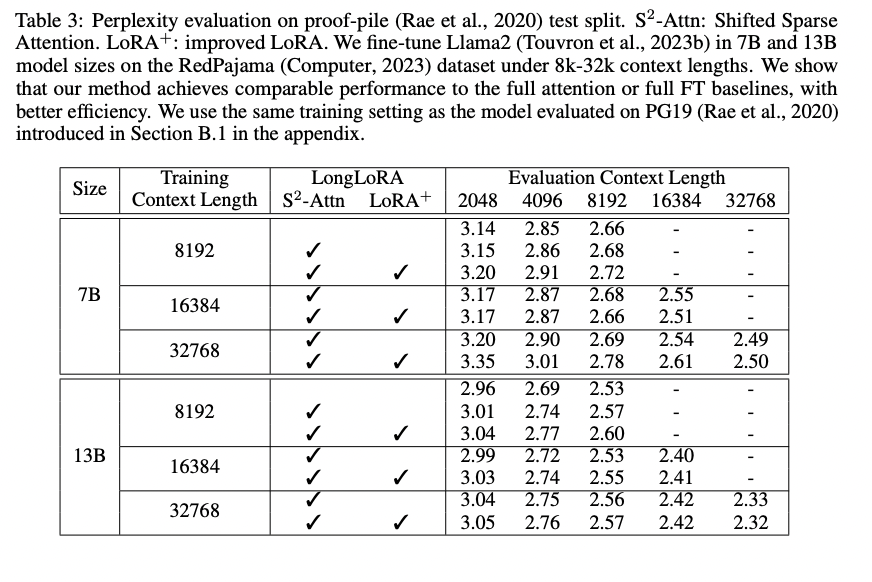
Overview
- github, paper
- LLM의 context size를 효과적으로 늘리는 방법인 LongLoRA 제안
- 보통 LLM의 길이를 늘리는 것은 비용이 많이 필요함
- 예) 2k -> 8k로 늘리는데 16배의 computational cost가 필요
- 따라서 이 논문에서는 Attention과 Lora 방식을 활용해 효과적으로 context size를 늘림
- 1) Shifted sparse attention S2-Attn 기법 제안
- 2) Lora를 trainable embedding & normalization을 넣어서 사용
- Llama2 7B/13B를 100K 까지, Llama2 70B는 32K까지 늘림 (1대의 A100활용)
Introduction
- LLM은 대부분 한정적인 context size를 가지고 있음
- Llama - 2k // Llama2 - 4k
- 하지만 이런 size는 long QA와 long summarization등과 같은 어플리케이션을 하지 못하는 한계
- 또한 현재 제안된 방법들은 computing cost가 많이 필요하거나 FT등에 적합하지 않음
- 따라서 효율적으로 늘리기위해 1) S^2 Attn 과 2) Lora를 같이 사용
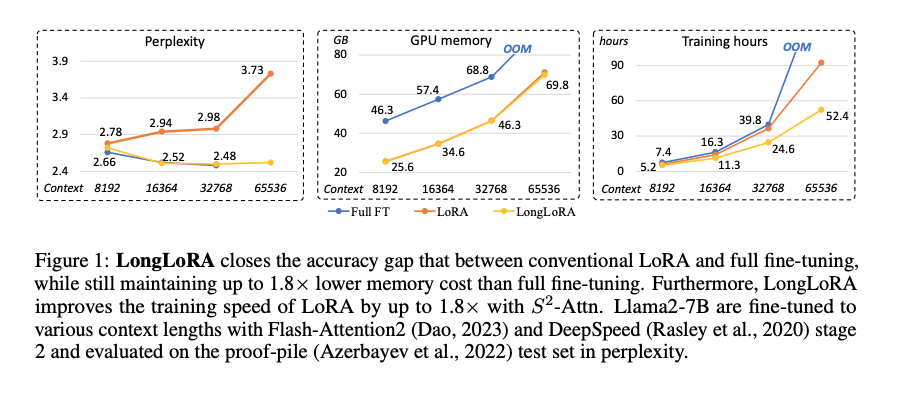
- 위의 그림과 같이 Lora만 사용한 경우에는 Context가 늘어날수록 Perpleixty와 Tranining 시간이 늘어나는데
- Shifted Sparse Attention 기법까지 같이 쓴 LongLora의 경우에는 안정적인것을 볼 수 있음
LongLora Method
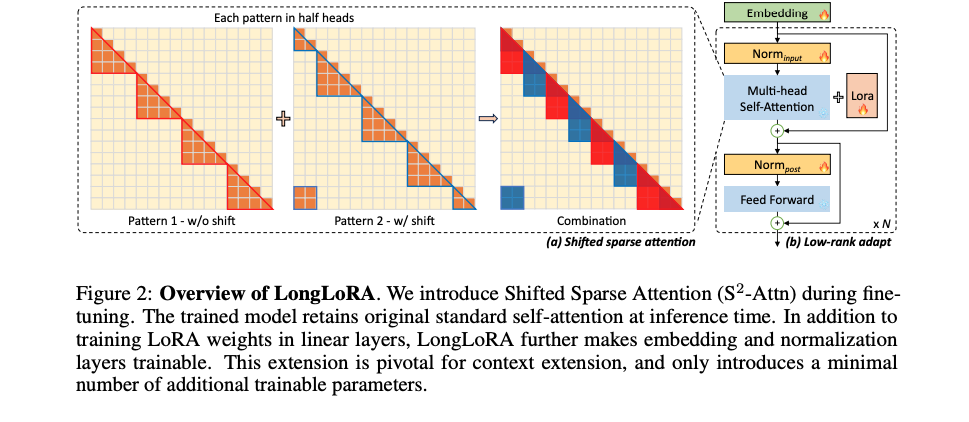
Pilot Study
- 보통 셀프 어텐션이 계산 소요량이 제일 큼
- 따라서 어떤 어텐션 방법이 perplexity를 해치지 않는 지 실험을 진행
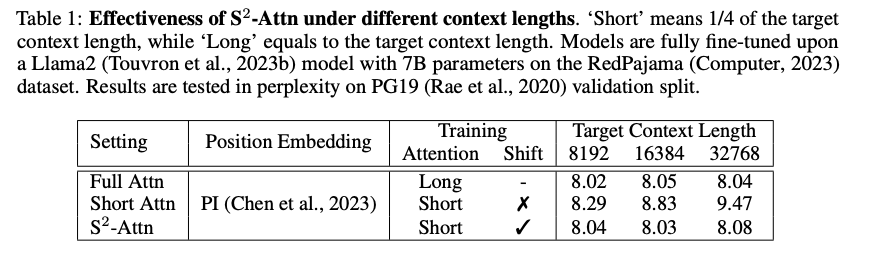
- (1) 가장 먼저 사용한 방법은 다른 논문에서 많이 사용 되는 방법으로 그림에서는 패턴 1번 참고
- input이 너무 길기 때문에 모두 다 보지 않고 self-attention 시에 여러개 그룹으로 나누는 것
- 예) input = 8192 , 그러면 그룹을 2048씩 나누어서 self-attention을 수행
- 하지만 (1)번 방법은 context가 길수록 perplexity가 높아짐 (낮을수록 좋은 매트릭)
- 그룹간에 서로 보지 못하는 토큰들이 영향을 미침
- 따라서 이를 해결하기 위해 (2) shifted를 같이 하는 방식 채택
- 이는 각 그룹마다 겹치는 곳이 있도록 함
- 반은 non-shift 반은 shift를 써서 연산
- 예시
- (1) 패턴 그룹: 1~2048
- (2)패턴 그룹: 1025~3072
- (1) (2) 패턴을 합쳐서 사용
Implementation
- 다음과 같이 간단하게 적용가능
- Head를 반으로 가른다음 Shift해주고 그룹 단위 attention 실행
qkv = cat((qkv.chunk(2, 3)[0], qkv.chunk(2, 3)[1].roll(-G/2, 1)), 3).view(B*N/G,G,3,H,D)
out = self_attn(qkv)
out = cat((out.chunk(2, 2)[0], out.chunk(2, 2)[1].roll(G/2, 1)), 2)
Result