논문리뷰-NLP
1.Fine-Tuning LLaMA for Multi-Stage Text Retrieval (RepLLaMA, RankLLaMA) 논문 리뷰
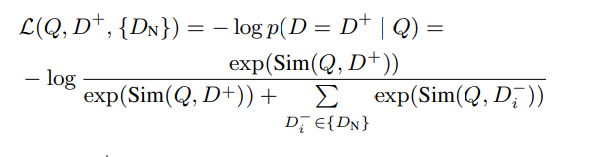
LLaMA 7B로 임베딩 기반 검색 모델 훈련작은 인코딩 모델 (Encoder 기반)에 비해서 큰 모델로, 성능 향상또한 Encoder보다 Max Length가 길어 Long input을 처리 가능 (Decoder = 2048, 4096)코드가 공개되어있음논문링크Ret
2.LONGLORA: EFFICIENT FINE-TUNING OF LONGCONTEXT LARGE LANGUAGE MODELS 논문 리뷰
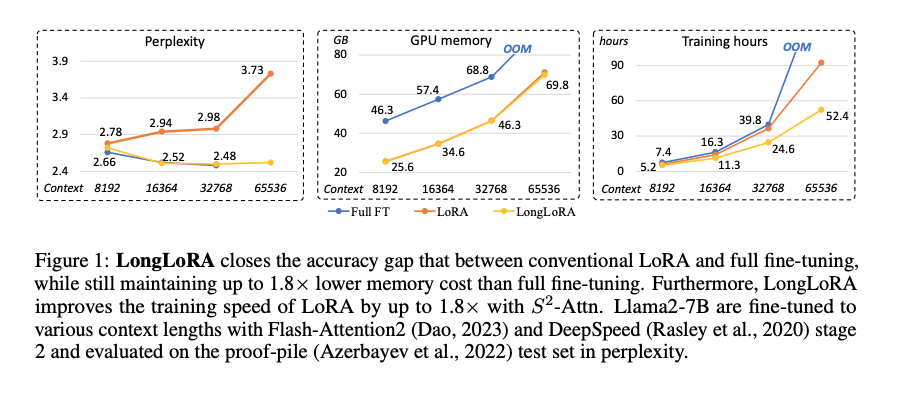
Overview LLM의 context size를 효과적으로 늘리는 방법인 LongLoRA 제안 보통 LLM의 길이를 늘리는 것은 비용이 많이 필요함 예) 2k -> 8k로 늘리는데 16배의 computationa
3.BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self 리뷰

Overivew BAAI라는 중국 AI 연구소에서 만든 embedding model M3는 다음과 같은 3가지 특징임 Multi-Linguality : 100개 이상의 언어 Multi-Functionality: 3가지 retrieval 방식을 같이 제공 Mu
4.Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection 리뷰

Overview * 훈련코드와 데이터 등이 github에 공개되어있음 * 스스로 자기자신을 평가하면서 기존의 RAG방식의 한계를 넘어선 논문 * 기타 다른 RAG방법론에 비해 성능이 좋고, 모델 사이즈가 작음에도 (7B, 13B) ChatGPT와도 유사한 성능을 보임
5.LongAlign: A Recipe for Long Context Alignment of Large Language Models 리뷰
* Long Context Alignment를 위한 recipe인 LongAlign 제안 * Instruction-data: construct a long instruction-following-dataset * training: packing & sorted
6.Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation 리뷰
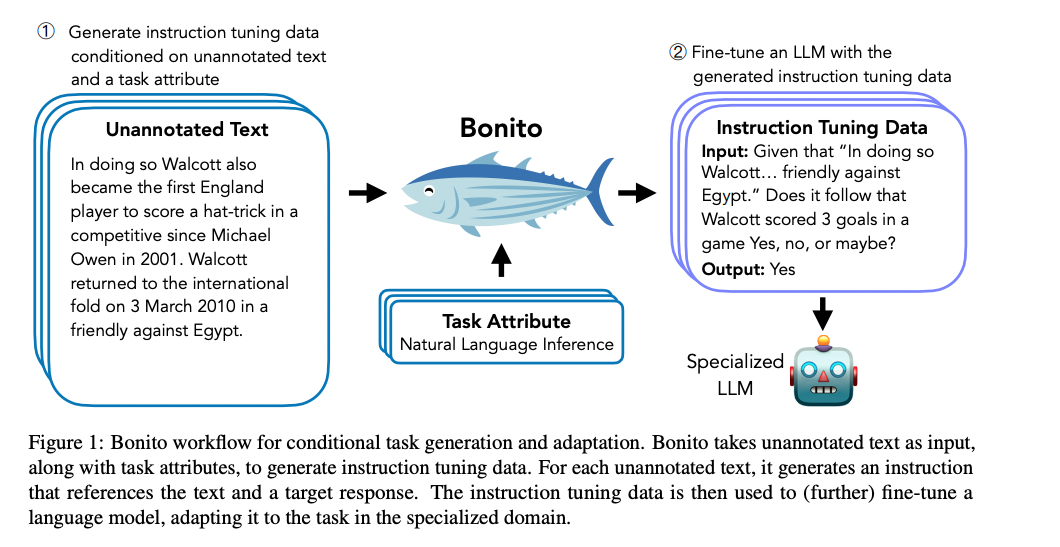
conditional task generation 를 위한 open-source model Bonitounannotated된 text를 instruction tuning을 위한 task-specific training dataset으로 바꿈
7.Toolformer: Language Models Can Teach Themselves to Use Tools 리뷰

논문github (공식레포는 아닌듯)Meta AI, 2023 2LM (GPT-J (6B)) 가 언제/어떤 API를 호출할지, 스스로 결정하는 방법self-supervised 방법으로 데이터를 쉽게 생성함총 5가지의 Tool(API)QA, Wikipedia Search,
8.SELF-REFINE: Iterative Refinement with Self-Feedback 리뷰
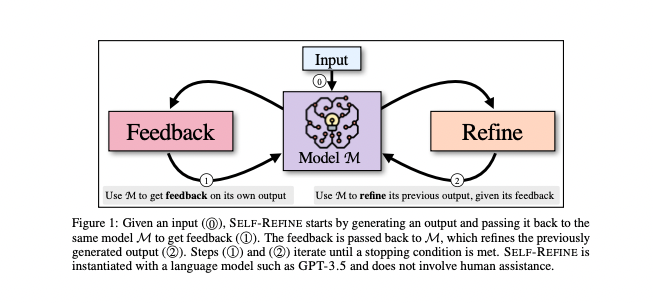
저자에 NVIDIA, Google Research... 등등LLM은 첫번째 시도에 가장 좋은 대답을 생성하는 것은 아님따라서 SELF-REFINE 방법을 제안사람이 writing을 개선하는 곳에서 모티브지속적으로 Feedback과 Refinement를 통해서 초기 결과
9.ART: Automatic multi-step reasoning and tool-use for large language models 논문 리뷰

LLM이 Tools을 쓸 수 있도록 ICL ART 프레임워크는 복잡한 추론과 외부 도구 사용을 자동화하여 대규모 언어 모델(LLMs)의 성능을 향상시키는 방법을 제시합니다. 이 연구
10.LoRAMoE:Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin 논문 리뷰
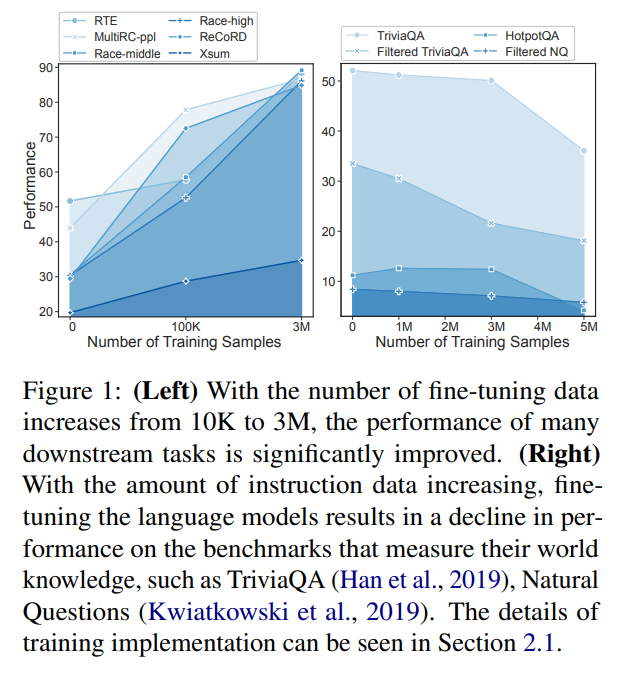
https://github.com/Ablustrund/LoRAMoEMoE 방식을 Lora로 진행SFT을 하게 되면 Downstream task의 성능은 증가 시키는 반면, global knowledge는 떨어지는데 이를 해결함SFT(Supervised Fine
11.SAIL: Search-Augmented Instruction Learning 논문 리뷰

아이디어는 굉장히 간단함 데이터를 생성하고, 이 데이터를 활용해 7B모델 학습https://openlsr.org/sail-7bLLM은 Zero-shot, few-shot ICL setting에서 성능이 좋음 또한 Instruction Tuning을 하면서 al
12.NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models 논문 리뷰
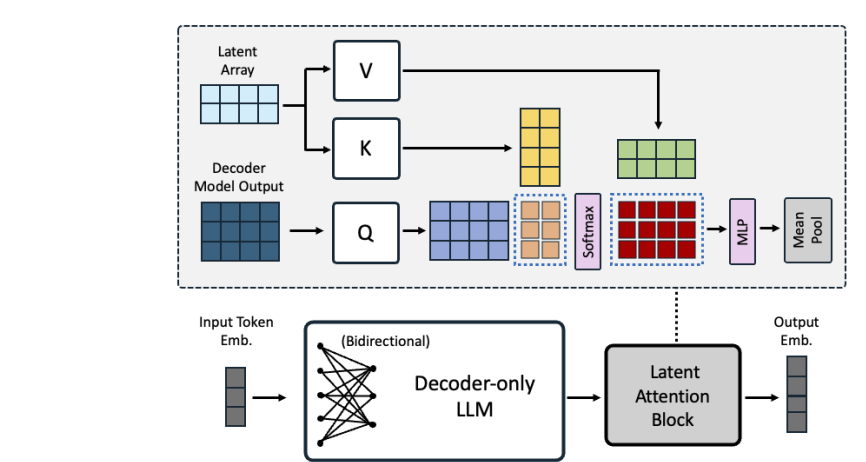
NVIDIA에서 낸 Decoder 기반의 Embedding 모델로 GPT-4 합성 데이터 없이, 공개 데이터로만 학습한 모델 MTEB(embedding 관련 리더보드) 에서 1등 기록중https://huggingface.co/nvidia/NV-Embed-v1