Overview
- 논문
- github
- conditional task generation 를 위한 open-source model Bonito
- unannotated된 text를 instruction tuning을 위한 task-specific training dataset으로 바꿈
- Input: unannotated / Output: instruction & response로 구성된 모델을 학습
- 그 후 Bonito를 통해 새로운 task dataset를 instruction tuning set으로 합성한 후 Fine tuning -> 좋은 성능을 보임
- 데이터 생성 모델을 학습했다. 이게 끝
Introduction
- Instruction tuning dataset으로 FineTuning을 진행하는 것은 unseen instructions에 대답하는 능력을 키워줌
- 그러나 instruction tuning dataset의 quality에 따라 정해진다는 한계점이 존재
- 대부분 공개 dataset에서는 special domain을 위한 instruction set은 없음
- 따라서 이 논문에서는 annotated data 없이 special domain에 적응할 방법을 연구
- 현재 연구는 크게 1) self-supervision 2) FT
- 1) self-supervision
- target corpus에 대해서 next word prediction을 통해서 새로운 도메인을 가르치는 방법
- 하지만 이 방법에서는 많은 양의 데이터 셋이 필요
- 또한 instruction tuning 모델에서는 이 방법이 성능이 하락한다는 것을 보임
- 2) FT(instruction tuning)
- 이 방법은 1)과 달리 성능은 향상, 그러나 데이터를 labeling 할 때 큰 비용과 시간이 소요됨.
- 따라서 이 논문에서는 다음 그림처럼 instruction tuning set을 만들어서 FT를 통한 zero-shot adaption 성능을 높이려고 함
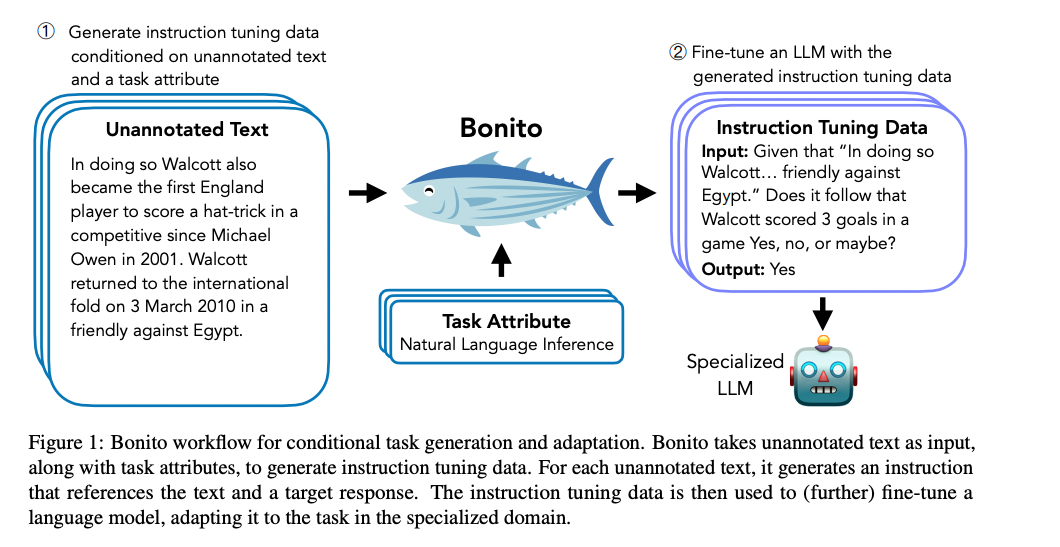
Method(Bonito: Learning to Generate Tasks)
Conditional Task Generation with Attributes

- 위의 그림과 같이 새로운 training dataset을 생성
- P3 dataset(https://huggingface.co/datasets/bigscience/P3) 활용
- 323 prompt templates, 39 dataset 16 task types
- 그 후 생성된 training dataset을 활용해서 모델 학습
- Mistral-7B
Experiment
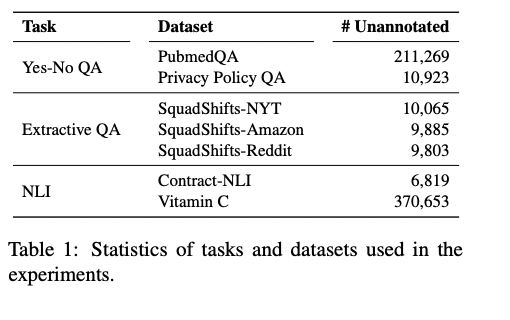
- 실험을 위한 모델 학습에서는 표와 같은 task에 대한 dataset을 학습한 Bonito Model을 활용해서 annotation 그 후 FT
Main Result
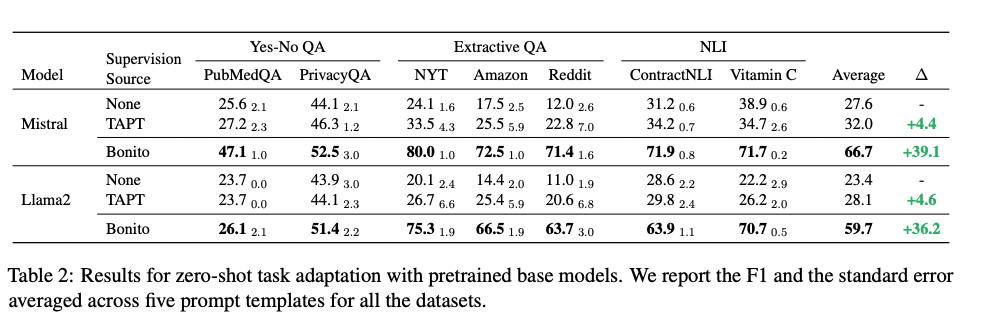
- TART: 다음단어 맞추기 (self-supervised baseline)
- Unseen dataset에 대해서 self-supervised baseline 방식도 성능이 좋지만 Bonito를 활용해서 데이터를 만들고 FT를 한게 성능이 더 좋음
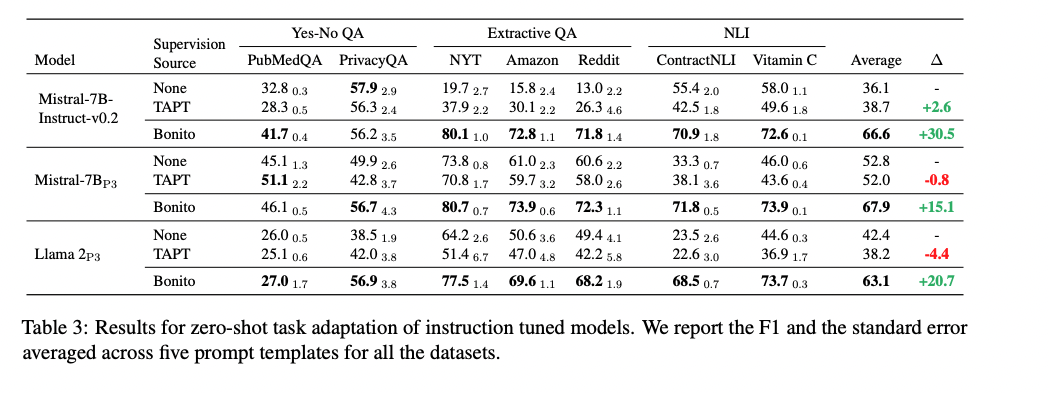
- Mistral-7B_p3, Llama2_p3 : instruction tuning with P3 dataset
- Instruction tuning 후 TART는 오히려 성능 하락
- 이는 TART가 이전 instruction tuning을 간섭/방해로 망각, 성능하락이 일어남
