Overview
- 저자에 NVIDIA, Google Research... 등등
- LLM은 첫번째 시도에 가장 좋은 대답을 생성하는 것은 아님
- 따라서 SELF-REFINE 방법을 제안
- 사람이 writing을 개선하는 곳에서 모티브
- 지속적으로 Feedback과 Refinement를 통해서 초기 결과를 개선(향상)
- 주요 아이디어: SAME LLM을 사용해서 지속적으로 피드백 & 개선
- SELF-REFINE은 오직 single LLM 만 필요함
- Supervised dataset, additional training, or reinforment learning 필요 X
- GPT-3.5 & GPT-4에서 실험해봤을 때 성능이 다 좋음
Method(Self-Refine)
Self-Refine
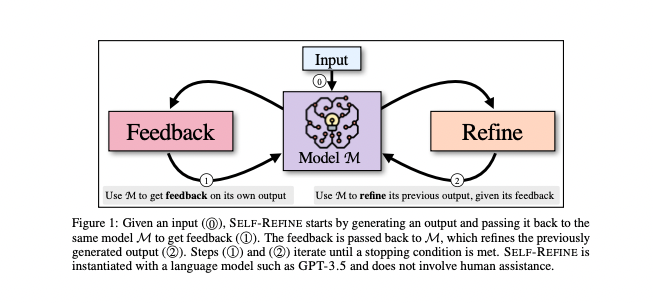
- 다음과 같이 3단계로 나누어져있음
- Initial Generation (0) : Initial Output 생성
- Feedback (1) : Output으로 Feedback 생성
- Refine(2): Feedback을 보고 Output 개선
- 이를 Stopping condition을 만족할때까지 계속 반복
- 장점: 추가 모델 학습 X
0. Initial Generation
- input과 Prompt가 주어지면 초기 Output 생성
- prompt 은 few-shot prompt 활용

1. Feedback
- 동일한 모델 M을 사용해서 task-specific prompt와 output을 보고 feedback을 생성
- Prompt
- Actionable, Specific feedback을 생성할 수 있도록 Prompting을 해야함
- Actionable: 구체적인 Action을 포함
- Specific : output에서 바꿔야할 구체적인 Phrase을 명시

- 또한 피드백은 여러 방면에대한 피드백도 동시에 가능
- 예) 코드 : feedback은 efficiency, readability, overall quality of code
2. Refine
-
Feedback을 보고 Output을 수정 & 개선
-
Prompt

Iterating Self-Refine
- Stop Condition을 만족할때까지 1~2단계 반복
- (1) 일정 step 수 도달
- (2) 혹은 Feedback 단계에서 나오는 Stop condition (task 마다 다르게 설계됨)
- 이전 Iteration에 대한 정보제공을 위해서 Prompt에 이전 단계의 Feedback과 output을 함께

Evaluation
Task

Main Result
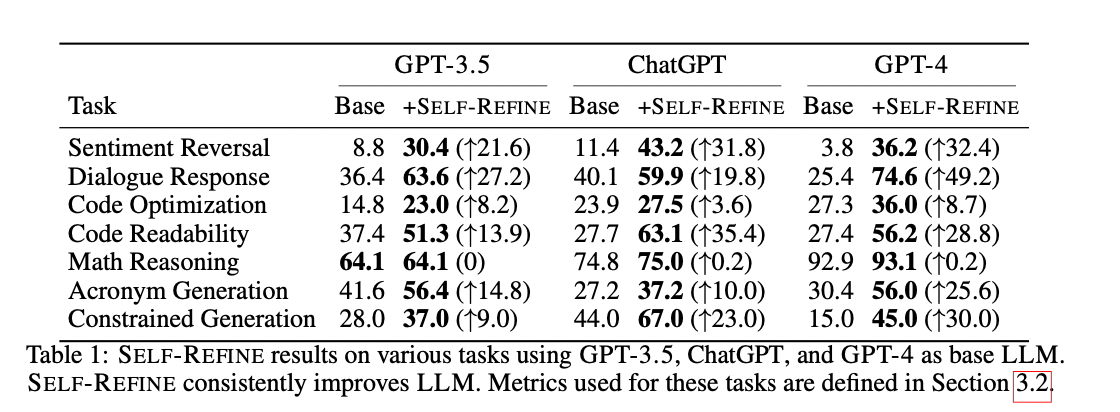
- 전반적으로 Self-Refine을 적용하면 성능이 뛰어남
- Math는 성능이 별로 안올랐는데 이유는 LLM이 Error 발생 원인을 식별 못한다고 함
Analysis-Weak Model
- Vicuna-13B에 대해 동일한 실험 진행
refinement process을 수행하지 못함 - Feedback을 잘 줘도 이상하게 Refinement
환각 / 같은 ouput 계속해서 생성
Conclusion
- Week 모델에선 작동안하고 LLM의 능력에 기대는 느낌
- 추가 Resource가 필요 없다고 하지만 여전히 Prompt는 다 Task마다 작성해줘야하고, 3단계 다 작성해야함
