Description
Overview
- LLM이 Tools을 쓸 수 있도록 ICL
- paper: https://arxiv.org/pdf/2303.09014v1.pdf
ChatGPT Abstract 작성 버전
ART 프레임워크는 복잡한 추론과 외부 도구 사용을 자동화하여 대규모 언어 모델(LLMs)의 성능을 향상시키는 방법을 제시합니다. 이 연구는 문제를 다단계로 분해하고, 적절한 도구를 동적으로 호출하는 과정을 통해, LLMs가 기존 접근법으로는 해결하기 어려운 과제를 수행할 수 있도록 합니다. 실험 결과, ART는 다양한 벤치마크에서 주목할 만한 성능 향상을 보여주며, 특히 인간의 직접적인 피드백을 통한 개선 가능성을 확인했습니다. 이러한 결과는 LLMs의 추론 능력을 확장하고, 복잡한 작업에 대한 접근 방식을 재고하는 데 기여할 것입니다.
Introduction

-
다음과 같이 Task Libaray에서 fewshot 샘플을 선택하고, LLM이 fewshot 샘플을 보고 자동으로 문제를 풀기위해 Tools를 사용하는 식으로 구성됨
-
LLM은 few-shot, zero-shot으로 복잡한 추론이 가능하며 , CoT 혹은 외부 Tools을 사용하여 모델의 성능을 더 향상 시킬 수 있음
-
그러나 이제 이전 연구는 task 작업 데모와, 모델 생성, tool 사용 등에서 많이 조정해야함
-
따라서 이제 ART 라는 프레임워크를 제안
- 고정된 LLM을 사용해서 자동으로 CoT처럼 문제를 분할& 생성하고, 다단계 추론과 tools를 선택함
- 실제 Inference 시 ART는 필요할때마다 Tools을 사용하고, 그 결과를 통합한 후 inference를 계속 진행함
- 또한 사람이 오류를 수정하거나, tools를 추가할 수 있게 해줌
Related Work
- Scaeld Fine-tuning for Low-resource Adaptation
- 다양한 공개 데이터 셋을 활용한 Tuning
- 예) Instrcut GPT
- Prompting with Intermediate Reasoning Steps
- LLMs이 중간 추론 단계를 생성 유도할 수 있는 CoT 프롬포트 등
- 추론을 단계별로 나눠서 LLM의 문제 해결 능력을 향상
- Tool Use
- LLM의 한계를 극복하기 위해 외부 Tool을 활용
Method

Prompt Building
task library에서 비슷한 task를 검색해옴- 그 후 이 task들을 demonstrations으로 prompt에 추가
- 이런 prompt는 LLM에게 새롭게 주어진 task를 분해하고, tools을 불러서 해결하는 방법을 알려줌
Generation
- LLM은 자체로 Program(일련의 과정)을 생성함
- 이때 이를 파싱하면서 Tools 호출이 발생할때마다 생성을 중지하고, Tools의 output을 활용해서 다시 generation 이어감
Human Feedback
- 사람이 직접 few-shot demonstrations을 추가하거나, Tools을 추가/편집 가능

Task Library
Task library (cluster)
- 5개 그룹 사용
- Arithmetric
- Code
- Search and question decomposition
- Free-from reasoning
- String Operations
- 그 후 각 cluster에서 2~4개의 task를 골라서 몇개의 few-shot을 작성

Program Grammar
- 그 한개의 예제를 여기서는
program이라고 명칭 - 이런 Program에는 다음과 같은 node가 포함
- task input node: task 설명
- serveral sub-step nodes: 중간중간 tool부르는 부분
- answer node: 답
예시
- Input
- task name과 task를 설명할 수 있는 짧은 description
- 예) Answer this high-school Physical question. Input: 질문
- Input 뒤에 바로 이제 sub-task-node의 sequence가 따라옴
- Query-answer pair로 이루어져 있음
- Q는 sub-task를 실행 (tools) / 즉 분해하고 tools을 실행하는 걸 보여주는 부분
- 예) Q1: [search] What is formula ...
- 예) #1: 답
- 그리고 마지막에 끝날떄는 다음과 같이 dummy sub-task로
- Q3: [EOQ]
- Ans: 답
Task Retrieval
- 새로운 작업에 대해 몇개의 label 이 있는지 여부에 따라 두가지 전략을 사용함
- (1) 새로운 작업의 몇개 label(output)에 접근 할 수 있는 경우
- 모든 cluster에서 몇개의 program을 골라서 prompt를 구성
- 그 후 가지고 있는 validation 셋에 대해서 평가 진행 후 가장 성능이 높은 task-cluster를 사용
- (2) 없는 경우
- few-shot template 생성 해서 "Similar"과 "Not Similar" 사이의 log 확률이 큰 task를 선택
- few-shot은 두 task 가 비슷한지 아닌지에 대해서 나와있음

Evaluation
Model
- InstructGPT, Codex 사용
- 3개 task, 2ro programs
baseline
- Fewshot/Direct
- CoT 리즈닝 같은 거 없이 few-shot 샘플을 LLM에게 바로 주는것
- Auto-CoT
- 그 CoT스타일로 예제를 주는 것 (Let's think step-by-step)
- ART-Tool
- without Tool use
- GPT-3best
Main Result
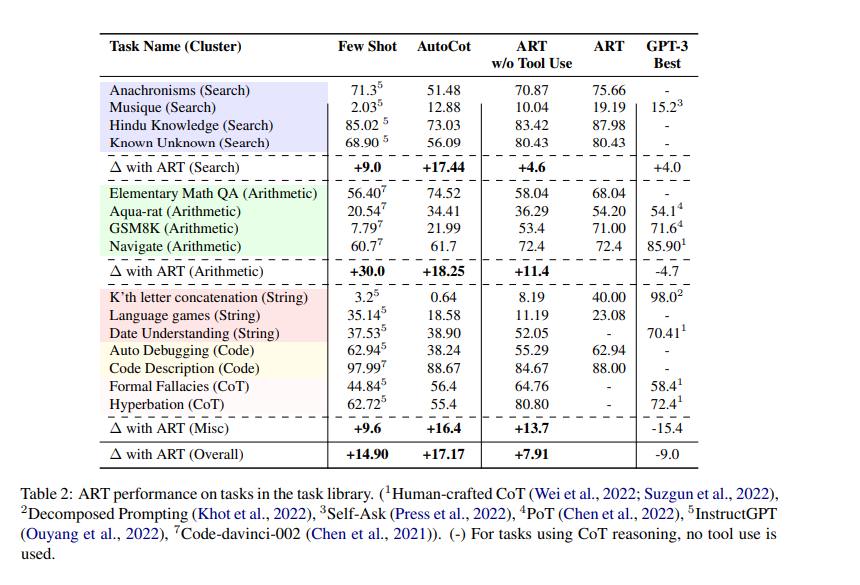
-
Few-shot에 대해선 14.9% 정도 성능 향상
-
Code, String 쪽 보면 Tools를 사용하지 않으면 수행이 잘 안됨.. 그 이휴는 코드 생성 오류가 연쇄적으로 오류가 되기때문에 따라서 w/o Tools use 보다 굉장히 성능이 높아지는 걸 알 수 있음
-
그러나 보면 GPT-3보다는 항상 좋은건 아닌듯...
