https://arxiv.org/abs/2310.11511
https://github.com/AkariAsai/self-rag
Overview
- 훈련코드와 데이터 등이 github에 공개되어있음
- 스스로 자기자신을 평가하면서 기존의 RAG방식의 한계를 넘어선 논문
- 기타 다른 RAG방법론에 비해 성능이 좋고, 모델 사이즈가 작음에도 (7B, 13B) ChatGPT와도 유사한 성능을 보임
Introduction
- 검색증강 방법이 사실성을 높이기 위한 방법으로 사용중임
- 보통 이 방법론에서는 검색이 필요한지 여부와 검색된 문단이 관련 있는지 여부와 관계 없이 고정된 TOP-k개의 문서를 활용
- 이는 LLM 응답의 퀄리티에 영향을 미침
- 따라서 이 논문에서는 검색과 자기 반응을 통해 LLM의 퀄리티와 사실성 향상
- 필요에 따라서 검색 (자체적으로 'Reflection'이라는 특수 토큰 추가해서 진행)
- Self-RAG (7B, 13B) 작은 모델로도 성능이 좋다고 밝힘
Method
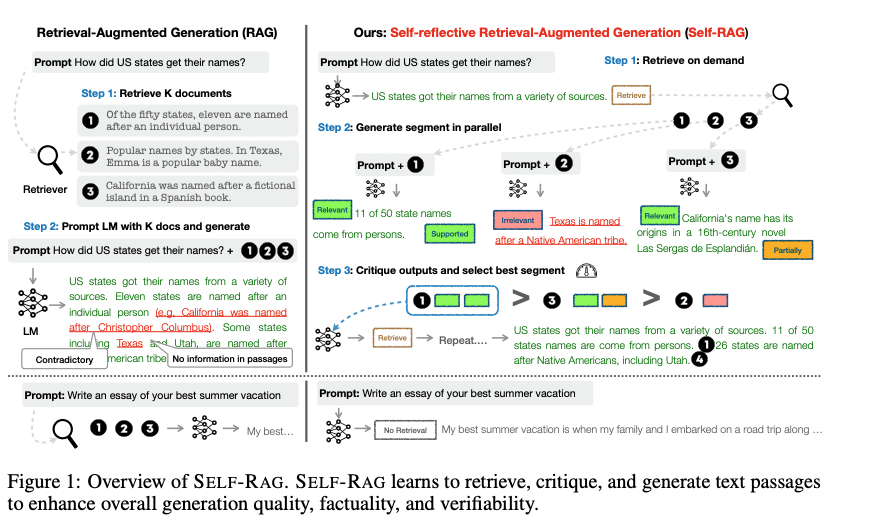
전체적인 과정
- 검색 결과 쓸 건지 결정
- Top-K 결과에 대해서 문맥에 대한 Relevance(관련성) 평가
- 대답을 generation하고 응답 중 가장 좋은 것 선택

Inference
-
genetaion을 이어가면서 모델은 'Retrieve' 토큰을 예측
- 검색 필요 X -> 다음 output segment로 이어서 예측
- 검색 필요 O -> 검색을 하는 단계로 이루어짐-
-
검색이 되면 모델은 'Critique' 토큰 예측
- 검색 passage 관련성 판단
-
그 후 응답에 대해서 Critie판단 진행
Training

- RLHF와 비슷하게 align을 하는 작업을 하는데 reward 모델이 아닌 'reflection' token을 통해서 align -> 훨씬더 cost가 저렴함
- Generation 모델 M을 검색결과와 Critic model C가 예측한 reflection token 가지고 훈련
- 이때 Model M이 inference 시에는 Critic model C에 의존하지 않고 스스로 생성할 수 있도록 훈련
- C를 훈련할때는 ChatGPT를 통해서 데이터 생성 M을 훈련할때는 C 모델을 가지고 데이터 생성
- 검색할지 말지, passage가 관련이 있는지 없는 지 등
Experiment
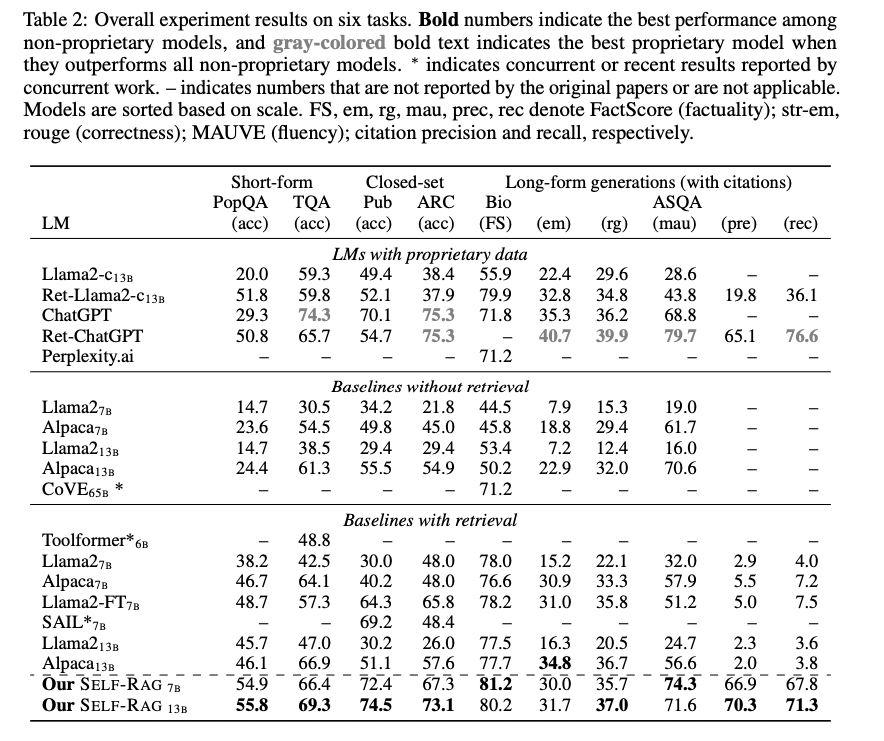
- 바로 RAG사용하는 기본 baseline에 비해 성능이 좋음
- 또한 chatGPT(훨씬 더 큰 파라메터)랑 유사한 성능
