reference: "프로그래머가 몰랐던 멀티코어 CPU 이야기" / 김민장, "Computer System A Programmers'Perspective" / 랜달 E.브라이언트
캐시 라인의 수는 주기억장치 블록의 수보다 적기 때문에 캐시 라인 배치를 위한 사상(mapping)해주는 알고리즘이 필요하다.
사상 함수의 선택에 따라 캐시의 조직(배치)가 결정된다. 직접(direct), 연관(associative) 및 세트 연관(set associative)가 있다.
(가정)
- 캐시는 64KB를 저장할 수 있다.
- 주기억장치와 캐시 사이의 데이터 전송은 4바이트(32비트) 블록 단위로 이루어진다. 이것은 캐시가 4바이트 크기의 64K(2^16)/4(2^2) = 16K(2^16)개의 라인으로 조직된다는 것을 의미한다.
- 주기억장치는 16MB(2^24)로 구성되는데, 24 비트 주소에 의해 각 바이트가 직접 주소지정될 수 있다. 따라서 사상이 이루어지도록 하기 위해, 주기억장치가 4바이트 크기의 4M개(16M/4)의 블록들로 구성된 것으로 간주할 수 있다.
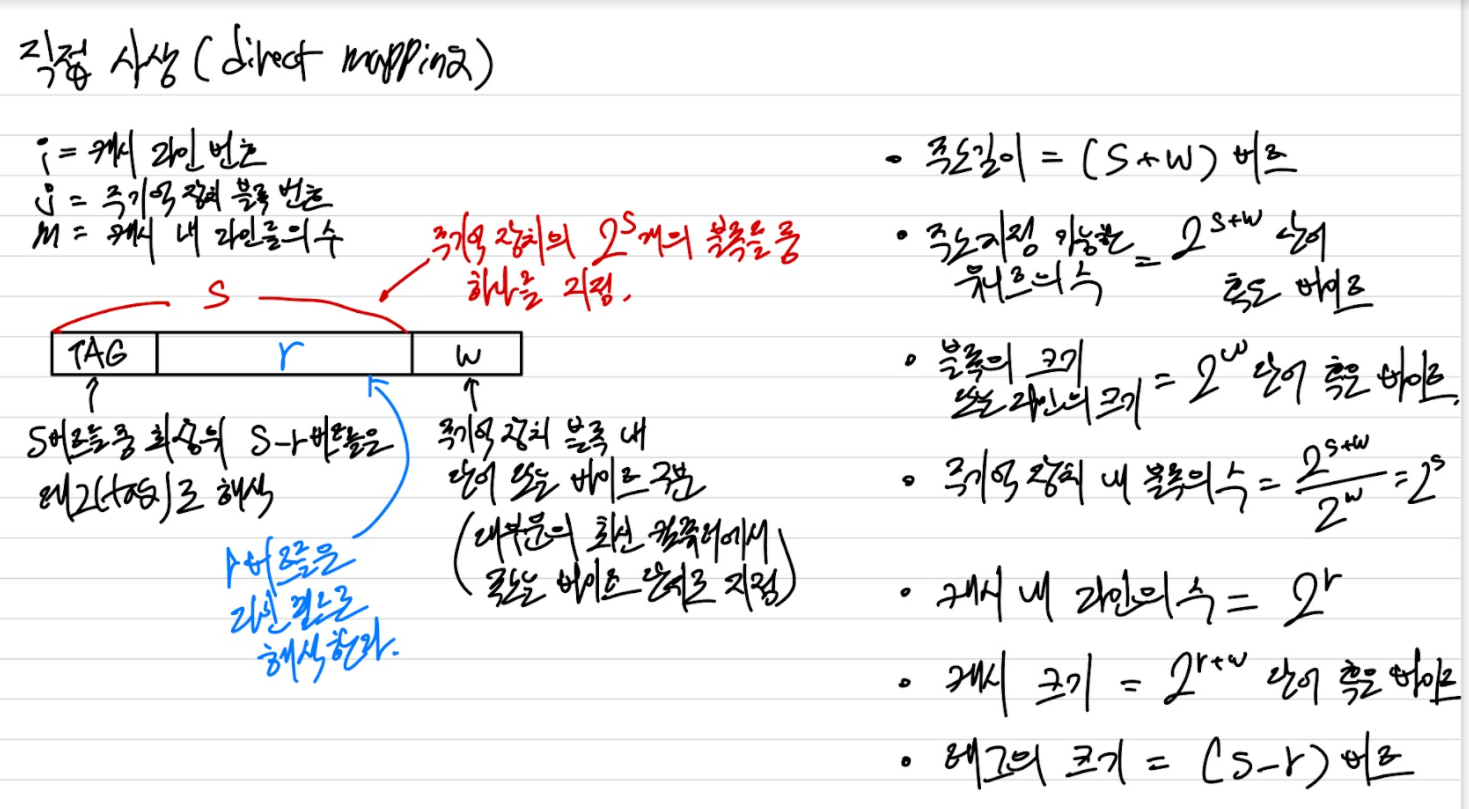
직접 사상(direct mapping)
가장 간단한 기술이다. 주기억장치의 각 블록을 한 개의 캐시 라인으로만 사상한다.
직접 사상 기법은 간단하고 구현 비용이 적게든다. 주요 단점은 어떤 블록이 들어갈 수있는 캐시 위치가 고정되어 있다는 것이다. 따라서, 만약 어느 프로그램이 같은 라인에 사상되는 두 개의 블록들로부터 단어들을 반복해서 읽어와야 한다면, 그 블록들은 캐시에서 반복적으로 교체(swap)될 것이고, 결과적으로 적중률(hit ratio)이 낮아진다. 이런 현상을 스레싱(thrashind)이라고 한다.
=> 직접 사상 방식은 스레싱 현상이 빈번할 수 있다.
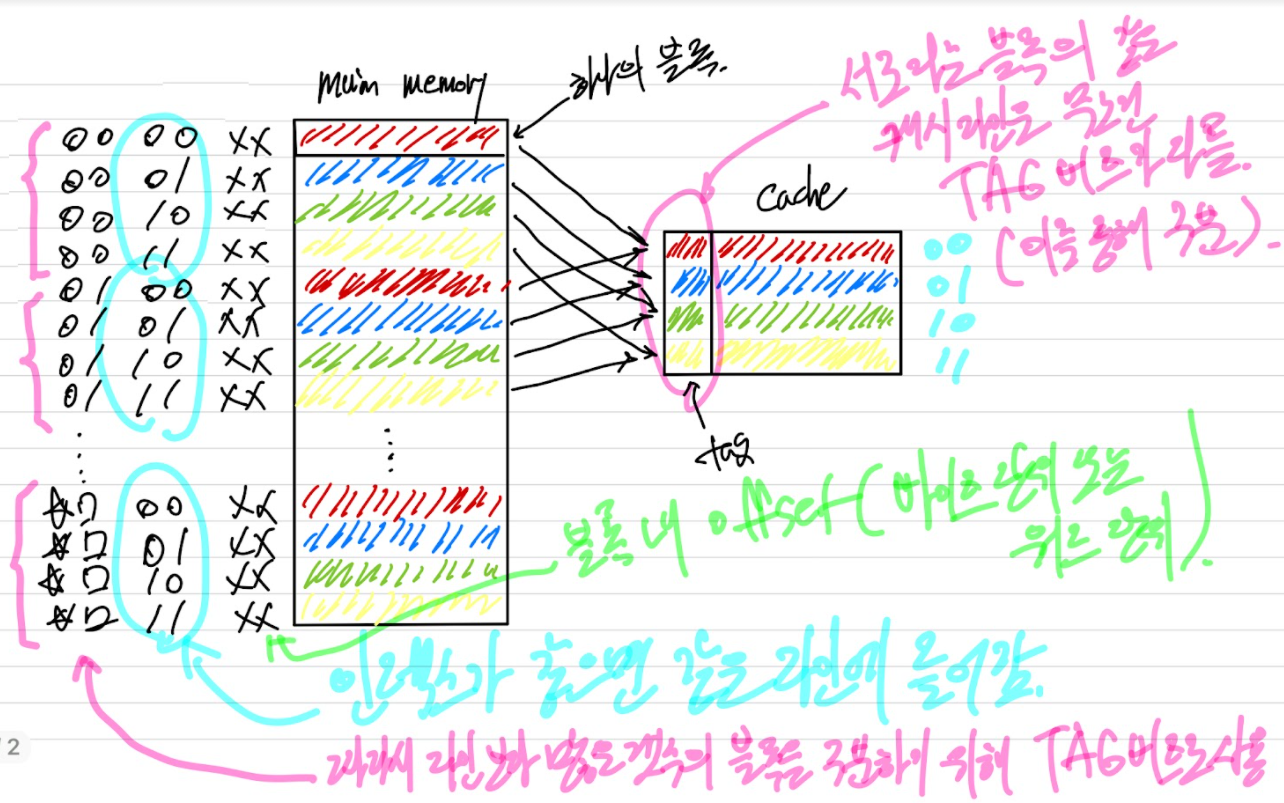
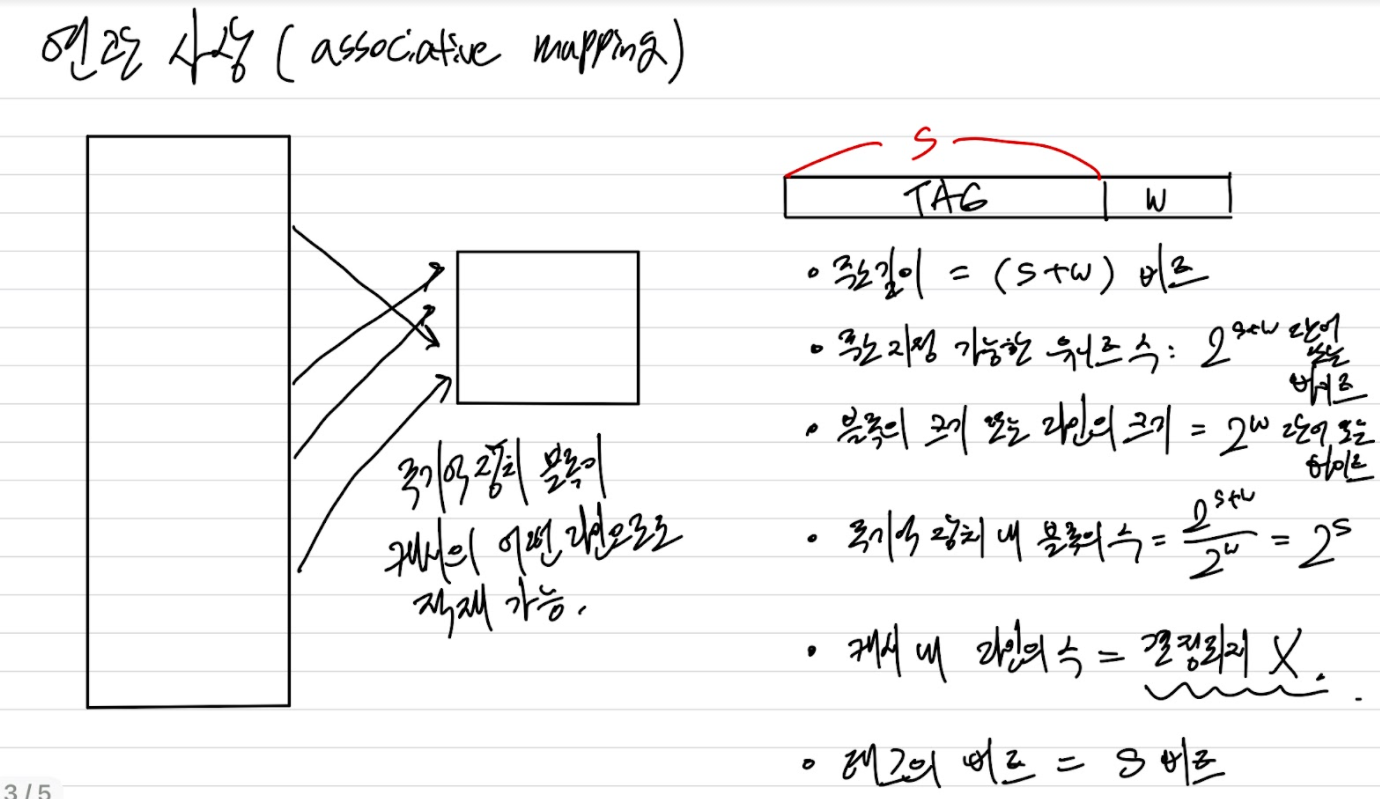
연관 사상(associative mapping)
주기억장치 블록이 캐시의 어떤 라인으로도 적재될 수 있도록 허용함으로써 직접 사상 방식의 단점(스레싱)을 극복하고 있다. 이 경우에는 캐시 제어 논리가 주기억장치 주소를 단순히 태그와 단어 필드로만 해석한다. 태그 필드는 주기억장치의 블록을 구분하는데 사용된다. 그 블록이 캐시에 있는지 확인하기 위해 캐시 제어 논리는 태그가 일치하는 "모든" 라인과 동시에 비교해야 한다. 결국 주소(비트들)에는 라인 번호와 대응되는 필드가 없으며, 따라서 라인 번호가 주소 형식에 의해 결정되지 않는다.
연관 사상에서는 새로운 블록이 캐시로 읽혀질 때 블록을 교체(replace)하는 데 있어 융통성이 있다. 반면 주요 단점은 캐시 라인들의 태그들을 병렬로 검사(모든 라인 검사 필요)하기 위한 복잡한 회로가 필요하다는 것이다.
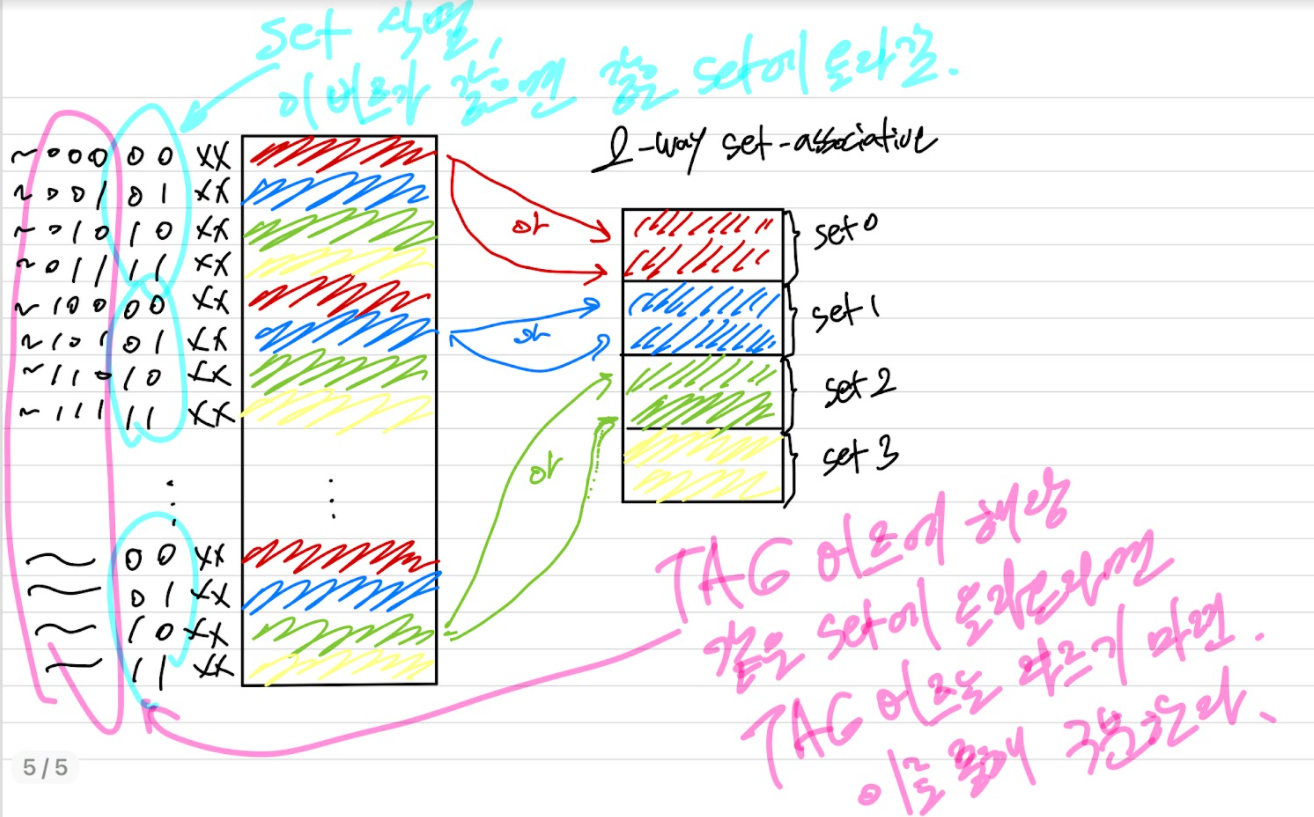
세트-연관 사상(set-associative mapping)
직접 사상과 연관 사상의 장점만을 취하고 단점을 줄이기 위한 절충안.
캐시는 여러 개의 세트들로 나누어지며, 각 세트들은 여러 개의 라인들로 이루어진다.
각 세트에서 라인들의 수가 k이면, k-way 세트 연관 사상이라고 불린다. 세트-연관 사상을 사용하면, 블록 B(j)는 세트 j 내의 어떠한 라인으로도 사상될 수 있다. 연관 사상에서는 특정 블록이 어느 캐시 라인으로도 사상이 가능했지만, 세트-연관 사상은 특정 세트 내의 모든 캐시 라인들로 사상될 수 있다.
세트-연관 사상에서, 캐시 제어 논리는 주기억장치 주소를 세 개의 필드로 해석한다. 태그, 세트, 및 단어 필드. d개의 세트 비트들은 v=2^d개의 세트들 중의 하나를 지정한다. s 비트의 태그 및 세트 필드들은 주기억장치의 2^s 블록들 중 하나를 지정한다. 연관 사상을 이용하면 기억장치 주소 내의 태그는 매우 커지며, 매번 캐시 내의 모든 태그들과 비교되어야 한다. k-way 세트-연관 사상을 이용하면, 기억장치 주소 내의 태그는 매우 작아지며 한 세트 내의 k개의 태그들과만 비교하면 된다.
v=m, k=1인 극단적인 경우에는 세트-연관 사상 기법이 직접 사상으로 바뀌게 도며, v=1, k=m이면 연관 사상으로 줄어든다. 세트당 두 개의 라인을 사용하는 것이 가장 일반적인 세트-연관 조직이다. 이 조직을 사용하면 직접 사상보다 적중률이 훨씬 더 개선된다.(캐시 충돌 미스율 완화) 4-way 세트 연관은 비교적 적은 추가 비용을 들여서 어느 정도의 성능 향상을 얻을 수 있는 방법다. 세트당 라인의 수가 그 이상 증가하여도 효과는 거의 없다.