reference: 시스템 프로그래밍 수업 / 최종무 교수님
code motion, 함수 호출 최소화, 불필요한 메모리 참조 방지 최적화 기법이 적용된 combine4
void combine4(vec_ptr v, data_t *dest){
int i;
int length = vec_length(v);
data_t *data = get_vec_start(v);
data_t x = IDENT; // *dest = IDENT;
// 지역변수는 함수 내에서만 의미가 있다. 따라서 변수 x 공간을 메모리에 할당하지 않고 레지스터에 할당한다.
// 이에 메모리 접근이 감소할 것이다.
// 예를들어 eax 레지스터를 반복해서 사용할 것이다.
for(i=0; i<length; i++){
x = x OPER data[i];
}
// 마지막에 한번 결과를 반영해주면 된다.
*dest = x;
}여기에 컴퓨터 자원 특성에 대한 고려를 보다 반영한 최적화 기법 추가
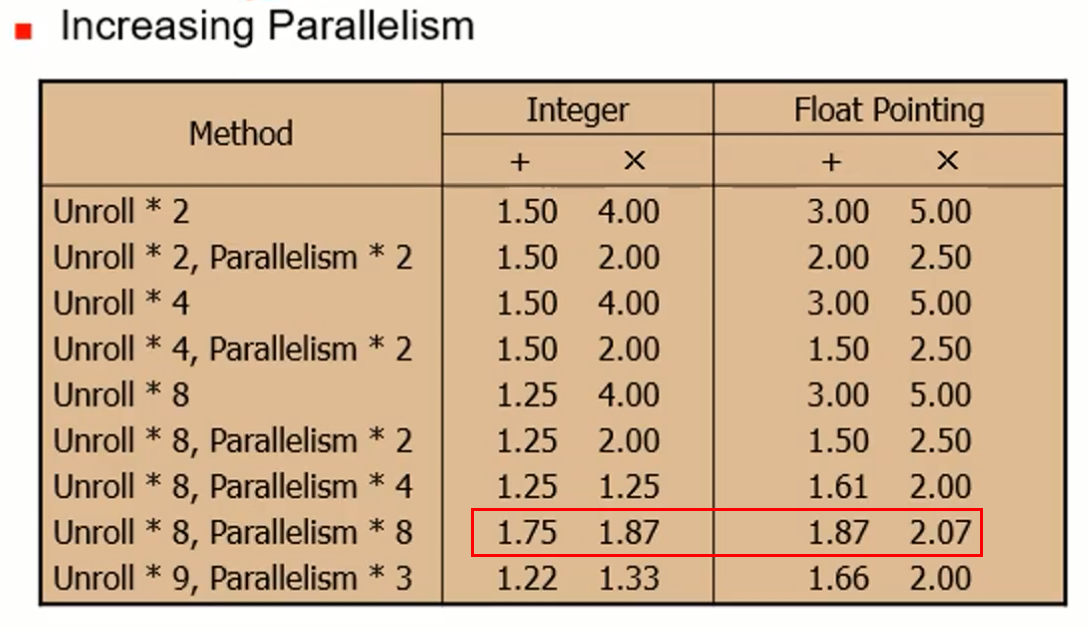
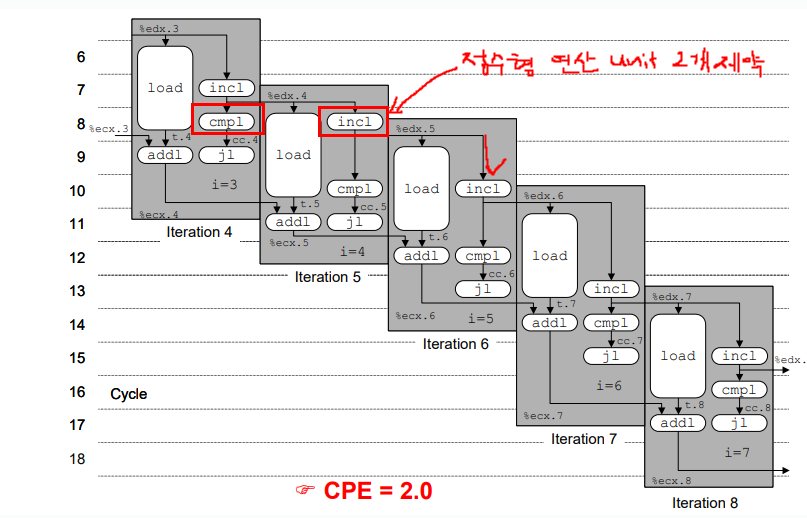
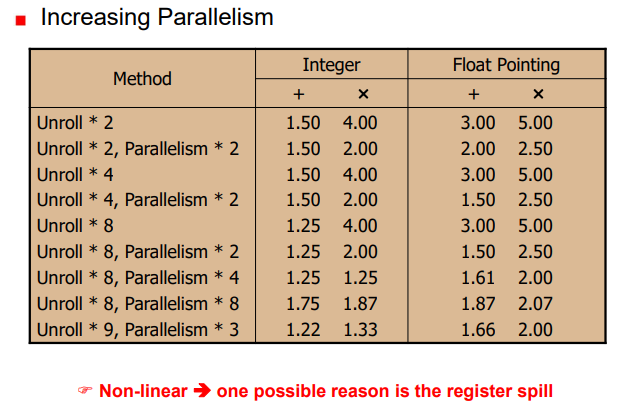
이전 페이지에서 combine4의 덧셈 연산은 CPE가 1이 될 수 있음에도 불구하고 2가 나옴을 알 수 있었다. 그 이유로 정수형 덧셈 연산 유닛의 제약이 있기 때문이었다는 것을 알 수 있었다. 이를 해결할 수 있는 최적화 기법을 Loop Unrolling이 있다.
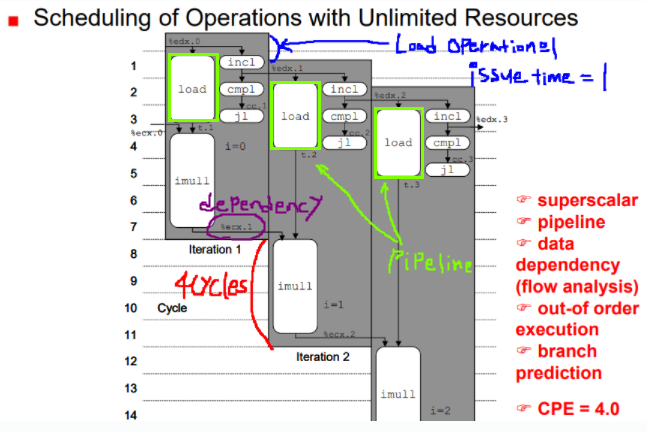
두 번째로 곱셉 연산에서는 파이프라인화가 가능하였지만 data dependency로 인해 불가능하게 되었다. 이러한 것을 해결할 수 있는 최적화 기법도 존재하다. Loop Splittiong이다.
Loop unrolling
void combine5(vec_ptr v, data_t *dest){
int i;
int length = vec_length(v);
data_t *data = get_vec_start(v);
data_t x = IDENT;
int limit = length-2;
// 이전 코드
/*
for(i=0; i<length; i++){
x = x OPER data[i];
}
*/
// loop unrolling
for(i=0; i<limit; i += 3){
x = x OPER data[i] OPER data[i+1] OPER data[i+1];
}
for(;i<length; i++){
// 나머지 처리
x = x OPER data[i];
}
*dest = x;
}
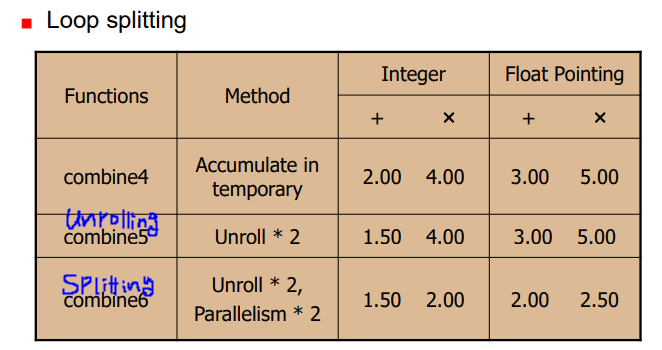
- 매번의 add 연산마다 cmpl, jump 하는 것이 아닌 3번의 덧셈연산을 진행하고 수행한다.

- 정수형 덧셈 유닛 2개 사용을 맞추면서 시간 축 기준 최대한 빽빽히(?) 사용.
- 세 개의 요소가 추가될 때마다 3사이클 증가 -> CPE는 1
- add 연산, Loop unrolling 적용 전 CPE는 2, 적용 후 1(이론상)로 감소.
- CPE = 1.33, may be 'register spilling(레지스터 갯수 제약으로 인한)' or 'resource contention'
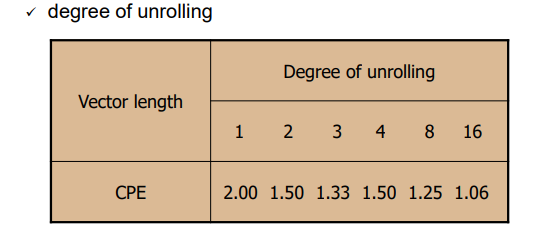
Loop unrolling 특징
(degree: 루프 한번의 연산되는 요소 갯수)
- 단조 감소하지 않는다.
- 스케줄링, 기타 제약, 레지스터 갯수 등에 의존적
- 코드 사이즈를 늘리므로 코드 가독성을 헤칠 수 있다.
Loop splitting
unrolling by 2 and 2-way parallelism
void combine6(vec_ptr v, data_t *dest){
int i;
int length = vec_length(v);
int limit = length - 1;
data_t *data = get_vec_start(v);
data_t x0 = IDENT;
data_t x1 = IDENT;
// 두 개의 서로 다른 변수에 각각 연산을 진행하여 의존성을 줄인다.
for(int i=0; i<limit; i += 2){
x0 = x0 OPER data[i];
x1 = x1 OPER data[i+1];
}
for(; i<length; i++){
x0 = x0 OPER data[i];
}
// 마지막에만 합하며 정확한 결과 보장
*dest = x0 OPER x1;
}
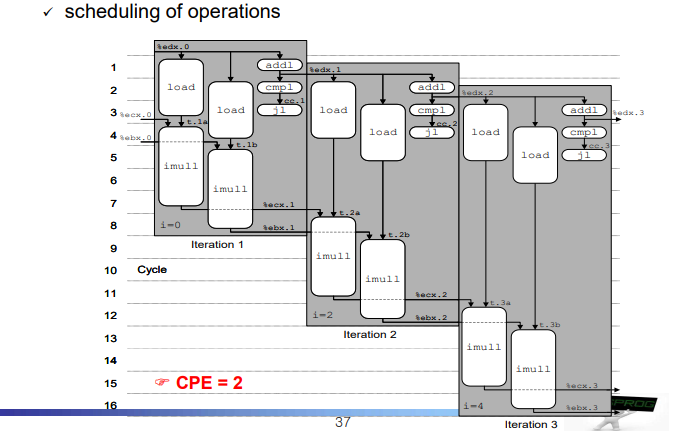
- data dependency로 인한 딜레이를 줄일 수 있다.
Loop splitting 또한 CPE의 선형적 감소를 보이지 않는다.
Loop unrolling과 splitting 적용 후 CPE
Enhanced Optomization
=> not linear! 자원의 제약, 레지스터 spill과 같은 이유들로 인해..
직접 분석을 해보며 최적화를 해야한다.