reference: "프로그래머가 몰랐던 멀티코어 CPU 이야기" / 김민장, "Computer System A Programmers'Perspective" / 랜달 E.브라이언트
프로세서의 클록 속도는 크게 증가하지 못하고 있다. 과거에는 클록 속도도 계속 늘고 싱글쓰레드의 성능도 크게 발전했는데 에너지 효율이라는 장벽에 막혀 요즘은 그렇지 못하다. 대신 코어 개수가 늘어나는 방향으로 진화 중이다. 이러한 방향으로 프로세서가 발전하게 됨에 따라 프로그래밍 방식이 근본적인 변화를 겪고 있다. 바로 병렬 프로그래밍으로 멀티코어 프로세서를 효율적으로 활용할 수 있어야 한다. 또한 멀티코어로 발전해 나가는 것이 옳은지 아닌지도 반문해볼 필요도 있다.
멀티코어 시대
컴퓨터의 속도는 눈부시게 발전했으며 이를 직접적으로 가능하게 한 것은 무어의 법칙이 말하는 반도체 제조 기술의 발전과 파이프라인이나 비순차 실행 같은 컴퓨터 마이크로아키텍처의 개선이었다.
2008년 인텔은 Nehalem 구조 기반의 Core i7 프로세서를 내놓았다. 이 프로세서는 731,000,000개의 트랜지스터를 가지며 작동 속도는 2.9GHz이다. 소프트웨어의 처리 속도는 이런 하드웨어의 발전으로 역시 엄청나게 빨라졌다. 2006년에 나온 Core 2 Duo는 11년전 1995년에 나온 인텔 펜티엄 프로세서보다 약 375배 빨라졌다.
참고로 프로그래밍 방법론도 과거 어셈블리 언어에서 C#, JAVA처럼 추상화가 많이 되었다. 이러한 소프트웨어의 무거워짐은 더 빠른 컴퓨터를 요구하게 되었다.
소프트웨어 발전과 하드웨어 발전은 순환 구조로 발전해왔다.
프로세서 성능향상 => 풍부환 소프트웨어 기능 => 더 커진 개발 조직 => 하이레벨 언어와 추상화 => 느려진 소프트웨어
=> 다시 프로세서 성능향상 요구
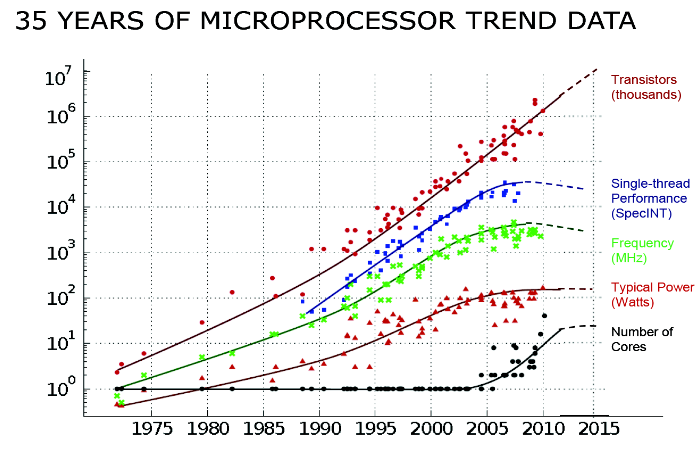
그런데 위와 같은 컴퓨터 산업의 발전은 모두 싱글코어 프로세서 시절의 이야기다. 이미 맞이한 멀티코어 시대에는 이러한 단순한 모델이 통하지 않는다. 과거 프로그램은 대부분 싱글쓰레드, 직렬 알고리즘으로 만들어졌다. 예전에는 2년마다, 프로세서 속도, 정확히 말하면 싱글쓰레드 성능이 크게 발전하여 기존의 프로그램을 크게 손보지 않아도 빨라진 컴퓨터의 혜택을 누릴 수 있었다. 그러나 2004년 이후부터는 이러한 추세가 느려지고 있다. 프로세서가 싱글쓰레드 성능보다는 듀얼코어, 쿼드코어 같은 멀티코어로 발전해서 기존의 프로그램을 병렬화하는 아주 큰 변화를 주지 않으면 최신 컴퓨터를 효과적으로 활용할 수 없게 된다.
무어의 법칙, 18개월 혹은 24개월마다 저렴한 비용에 집적될 수 있는 트랜지스터의 개수가 두 배씩 증가한다는 법칙은 아직까지도 유효하다. 과거에는 추가된 트랜지스터를 싱글쓰레드 성능 개선에 전적으로 투입했다. 명령어 파이프라인을 개선하고 캐시 양을 늘리는 것으로 무어의 예언대로 늘어난 트랜지스터를 사용했다. 그러나 2004년 정도를 기준으로 더이상 싱글쓰레드 성능 향상에 트랜지스터를 투입하기가 어려워졌다. 에너지 효율이라는 장볍에 가로막힌 것이다. 그래서 프로세서 설계자들은 멀티코어로 눈을 돌렸고, 프로세서의 물리 코어 자체를 복제해서 하나의 칩으로 만들기 시작했다. 바로 칩 멀티프로세서(Chip Multiprocessor, CMP)의 등장이다.
싱글코어의 한계: 에너지 장벽
싱글쓰레드의 성능이 과거처럼 기하급수적으로 늘기 어려운 이류로는 크게 클록 속도와 ILP(명령어 수준 병렬성 제약을 꼽을 수 있다.
클록을 높이는 방법은 크게 두 가지 방법이 있다.
-
반도체 제조 공정 기술 자체가 발달해 클록을 높이는 방법.
-
마이크로 아키텍처 수준에서 높이기, 사실 이 방법에서 할 수 있는 일은 많지 않음. 파이프라인 단계를 더 잘게 나눔으로써 한 파이프라인 단계에서 해야할 일을 줄여 클록 속도를 높이는 것.
인텔 프로세서에서 P5(586에 해당)까지는 순차 방식의 파이프라인으로 단계 수가 같다. 따라서 같은 반도체 제조 공정 기술로 제작된다면 클록 속도는 같아진다. 이 시기의 클록 상승은 공정이 미세화됨에 따라 회로를 거치는 데 필요한 시간이 줄기 때문에 클록 속도를 높일 수 있었다.
P6는 펜티엄 프로의 마이크로 아키텍처로 x86에서 최초로 비순차 프로세서를 구현했다. P6는 기존의 파이프라인을 두 배 가까이 늘려 약 1.5배 정도 클록 속도를 향상시킬 수 있었다. 펜티엄 4(P4P) 프로세서, P4P는 P6를 다시 두 배로 늘린 슈퍼 파이프라인을 채택했다. 그래서 클록 속도를 과거 세대와 비하면 같은 제조 공정 기술에도 확연하게 높일 수 있었다.
참고로 펜티엄 프로, P6 구조는 펜티엄과 완전히 다른 프로세서로 Core 2 Duo, Nehalem의 기본 토대로 닦은 상당히 역사적인 마이크로아키텍처.
펜티엄 4의 마이크로아키텍처인 첫 Netburst 구조는 20단계부터 시작하여 코드명 프레스캇 구조에서는 31단계로 대폭 증가되었다.
펜티엄 4가 이런 깊은 파이프라인을 채택할 수 있었던 것은 결국 이 방법이 클록 속도도 높이고 동시에 시스템 성능도 개선할 수 있어서였다. NetBurst 구조를 예로 들자면 먼저 파이프라인 깊이가 깊어질수록 클록 속도는 계속 증가하고(비록 아주 깊은 파이프라인에서는 클록 속도가 감소하지만) IPC(Instruction per Cycle)는 줄어든다. 명령어 하나를 완료하는데 필요한 작업 자체는 줄지 않는다. 따라서 빠른 클록의 프로세서에서는 한 명령어를 마치는 데 더 많은 클록이 필요하다. IPC가 감소하는 이유가 여기에 있다.(???)
그러나 여기에는 심각하게 생각하지 않은 것이 있는데, 바로 전력 소비와 발열에 관한 에너지 효율이라는 설계 요소이다. 펜티엄 4 프레스캇 프로세서는 100와트에 가까운 전력을 사용한다. 뜨거운 열이 손톱만한 물리 코어에서 뿜어져 나오니 상당한 크기의 히트 싱크(head sink)와 쿨러가 필요한 것이다. 게다가 파이프라인 단계를 더 깊게하고 클록 속도를 4GHz에 가깝게 늘리니 발열이 도저히 잡을 수 없는 수준에 이르렀다. 에너지 장벽(energy wall)에 부딪힌 것이다.
결국 인텔은 다음 마이크로아키텍처를 Netburst 기본이 아닌 펜티엄 프로부터 이어져 온 P6 구조로 다시 회귀하게 된다. 2009년 출시된 인텔 Core i7의 클록 속도는 (3GHz 정도) 펜티엄 4보다 같거나 낮다. 그럼에도 전력은 훨씬 적게 들며, 싱글쓰레드 성능은 더 높다.
싱글코어의 한계: ILP(명령어 수준 병렬성) 한계
비순차 슈퍼스칼라 방식의 프로세서 근본 원리는 바로 ILP이다. 싱글쓰레드에도 있는 명령어 사이의 병렬성을 찾아 성능을 높인 것. 그런데 실제로 ILP를 찾는 것에는 여러 제약이 있었다. 이전에 명령어 윈도우라는 개념을 언급하였는데, 프로그램의 모든 명령어 속에서 ILP를 찾는 것은 거의 불가능하므로 일정한 영역 속에서 제한적으로만 찾을 수 있다는 뜻이다. 컴파일러는 수천 개의 명령을 보면서 ILP를 찾지만, 현대 비순차 프로세서는 백여 개밖에 되지 않는다.
아주 이상적인 하드웨어 자원이 있어 명령어 윈도우가 무한하고 캐시도 완벽하며 분기 예측도 항상 옳다하면 ILP를 엄청나게 높일 수 있지만 조금이라도 현실적인 하드웨어 제약을 추가하면 ILP 값은 크게 떨어진다.
정리
source: https://tech.ssut.me/goroutine-vs-threads/
싱글코어 성능이 한계에 부딪힌 이유를 크게 에너지 장벽과 ILP 한계 관점에서 살펴보았다. 비순차 실행은 고클록을 얻기가 쉽지 않은 구조다. 파이프라인을 깊게 해서 클록을 높이는 방법도 회로를 두 배로 복잡하게 하고, 에너지 효율이라는 측면에서 좋지 않은 선택이었다. 무엇보다 싱글쓰레드에 있는 ILP가 이론적으로는 상당히 잠재력이 있지만, 지금의 기술로 찾아낼 수 있는 값이 그리 높지 않다.
한 칩에 올라갈 수 있는 트랜지스터의 양은 계속 늘어난다. 무작정 캐시를 늘리는 데 쓸 수도 없다. 계속 늘어나는 트랜지스터를 싱글 코어 성능 향상에 쓰고 싶어도 당장에 그 방법을 찾기가 어렵다. 그래서 멀티코어로 방향을 바꾼 것이다.
또 예전에는 포로세서 밖에 있던 여러 칩, 예를 들어 GPU를 같이 집적하기도 한다.
