reference: "프로그래머가 몰랐던 멀티코어 CPU 이야기" / 김민장, "Computer System A Programmers'Perspective" / 랜달 E.브라이언트
병렬 컴퓨터의 개념
멀티코어는 전혀 새로운 것이 아니며, 결국 병렬 컴퓨터 구조의 새로운 제조 형태일 뿐이다. 과거에는 독립적으로 있었던 프로세서들이 반도체 기술 덕택에 하나의 칩에 제조될 수 있으니, 이것이 바로 멀티코어 프로세서의 탄생이다. 따라서 병렬 컴퓨터 구조 자체를 먼저 살펴볼 필요가 있다.
병렬 컴퓨터는 (1) 계산 장치(processing element, PE)를 모아놓은 것으로 (2) 계산 장치가 서로 데이터를 주고받고 (3) 협력하여 큰 문제를 더 빠르게 푸는 것으로 정의할 수 있다.
-
어떠한 계산 장치를 모을 것인가?
현재 데스크탑에 쓰이는 듀얼/쿼드 코어는 수는 적지만 매우 강력한 코어를 모은 것이다. 이 반대로 작지만 그 수가 많은 병렬 구조도 있다. 대표적인 예가 바로 GPU인데, GPU는 간단한 구조의 작은 프로세서를 수백 개의 단위로 모아놓은 것이다. 또한 이 중간도 있다. 어느 정도 강력한 코어 몇 개와 작지만 많은 코어를 섞어 놓을 수도 있다. 혹은 전혀 다른 프로세서, 예를 들어 CPU와 GPU를 모아 멀티코어를 만들 수 있다. -
계산 장치 간의 통신 문제
병렬 컴퓨터 내의 프로세서와 계산 장치가 어떻게 서로 데이터를 주고받느냐의 문제. 크게 공유 메모리 구조와 분산 메모리 구조를 들 수 있다. 구조에 따라 데이터를 주고받는 논리적인 형태가 다르다. 물리적인 차원에서는 네트워크 문제와 같다. 레이턴시가 빠르고 대역폭이 높은 인터커넥션 장치를 만드는 방법. 보다 자세히 말하자면 칩 내의 각 코어 사이의 통신, 칩과 칩 사이의 통신, 칩과 메인 메모리와 같은 주변 기기와의 통신 문제로 나눌 수 있다. -
계산 장치 간의 협력 문제
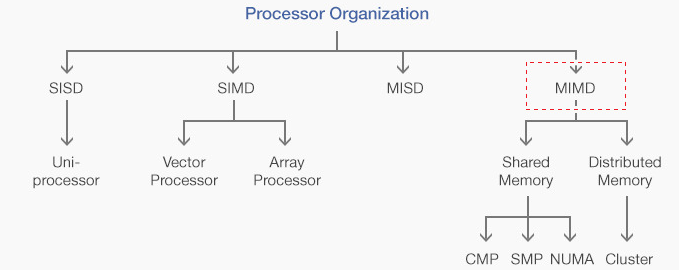
큰 문제를 풀려면 멀티프로세서의 여러 계산 장치가 협력해야한다. 거시적으로는 플린(Flynn)의 SIMD/MIMD/MISD/MIMD 구분법으로 나누는 멀티프로세서 구조 문제가 있다. 어떤 방식으로 데이터를 가공할지 그 방법론을 결정. 미시적으로는 멀티스레드 사이의 동기화 문제를 들 수 있다.SIMD/MIMD/MISD/MIMD
(Single|Multiple) Instruction (Single|Multiple) Data stream
싱글코어가 발전할 수 있었던 것은 ILP가 있었기에 가능하였고, 병렬 컴퓨터는 일단 자명하게 TLP, 쓰레드 수준 병렬성을 활용할 수 있다. 이것을 더 세분화하면 루프 수준 병렬성, 태스크 수준 병렬성, 프로그램 수준 병렬성으로 나눌 수 있다.
루프 수준 병렬성
// 병렬화 가능 루프
for(int i=0; i<N; i++){
A[i] = A[i] + B[i];
}
// 병렬화 불가능 루프
for(int i=0; i<N; i++){
C[i] = C[i-1] + D[i];
}위 코드에서 첫 번째 루프는 어떠한 루프 전이 의존성도 없어 병렬화가 가능하다. 이는 루프 수준 병렬성이 있다는 것이다. 반면 두 번째 루프는 루프 전이 RAW 의존성이 있어 병렬화가 불가능하다. 이런 루프를 집중 공략하여 병렬화 가능성을 찾는 것이 현명하다. 물론 어떤 프로그램은 루프에 루프 전이 의존성이 많아서 쉽게 병렬화하지 못할 수도 있다. 많은 수의 뮤텍스로 동기화를 하다 보면 병렬화로 얻는 이득이 감소될 수도 있다.
태스크 수준 병렬성
임의의 코드 영역이 동시에 수행 가능함을 가리킨다. 위 코드에는 태스크 수준의 병렬이 있다. 첫 번째 루프와 두 번째 루프는 아무런 연관이 없기에 동시에 실행 가능하다. 워드프로세서에서 배경으로 작동하는 문법 검사기 역시 글씨 입력 자체를 다루는 작업과는 동시에 실행될 수 있는 병렬성을 가지고 있다 볼 수 있다.
그러나 이들 태스크 사이에는 서로 간의 조율이 필요한데, 새로운 글씨가 입력되면 문법 검사기 작업 쓰레드를 깨우고, 이 쓰레드가 작업이 끝나면 다시 결과를 알려줘 화면에 보여줄 것이다.
프로그램 수준 병렬성
직관적으로 독립적인 프로그램을 동시에 돌리는 것이다. 대표적인 예로 C/C++에서 컴파일 과정을 볼 수 있는데, 소스 파일은 독립적으로 컴파일 될 수 있고, 이 작업은 여러 코어에 나누어 실행되어 컴파일 속도를 크게 단축시킬 수 있다. 다만, 링킹 과정은 컴파일 결과를 취합해서 하므로 동기화가 필요하다. 이런 프로그램 수준 병렬성은 단순하고 멀티코어 구조에서는 쉽게 혜택을 얻을 수 있다.
병렬 컴퓨터 구조
플린의 구분법으로 나눈 4가지 구조에 대해 설명. 플린은 명령어가 하나이냐 여러 개이냐, 이 명령이 다루는 데이터의 흐름이 하나이냐 여러 개냐에 따라 4가지 컴퓨터 모델을 구분하였다.
-
SISD(Single Instruction Single Data)
본 글을 떠나 이전까지의 모든 글은 SISD 구조이다. 스칼라, 슈퍼스칼라 프로세서가 여기에 해당한다. ALU는 한번에 하나의 명령과 하나의 데이터만 취해 계산한다. -
SIMD(Single Instruction Multiple Data)
하나의 명령이 여러 데이터를 취하는 것으로 벡터 연산이라 자주 부름. x86의 SIMD 확장인 MMX, SSE가 바로 여기에 속함. (SIMD는 story 11 참고) -
MISD(Multiple Instruction Single Data)
자료는 하나인데 명령이 여러개라는 뜻. 특수화된 구조로 여기서는 다루지 않음. -
MIMD(Multiple Instruction Multiple Data)
source: https://brunch.co.kr/@dreaminz/4
여러 명령어가 여러 데이터를 처리하는 것으로 바로 일반적인 멀티프로세서 구조를 가리킨다. 명령어와 데이터는 모두 메모리에 있다. 그래서 메모리를 어떻게 여러 프로세서가 보느냐에 따라 구조가 나뉜다. 크게 공유 메모리 구조와 분산 메모리 구조로 나눌 수 있다.
공유 메모리 구조
공유 메모리 구조 멀티프로세서는 사실 지금 우리가 쓰는 멀티코어 컴퓨터라 생각하면 된다. 프로세서와 코어가 여러 개 있더라도메모리 주소 공간이 모두 공유된다. 프로그래밍 관점에서는 다른 프로세서가 쓰는 데이터가 있는 공간을 내가 바라 볼 수 있다는 것이다. 이미 많은 개발자가 하고 있는 일반적인 멀티쓰레드 프로그래밍 방법론이 여기에 해당된다. 공유 메모리 구조는 다시 구성 방식에 따라 칩 멀티프로세서(CMP), 대칭형 멀티프로세서(SMP) 멀티코어, 분산 공유 메모리(Distributed Shared Memory)로 나눌 수 있다.
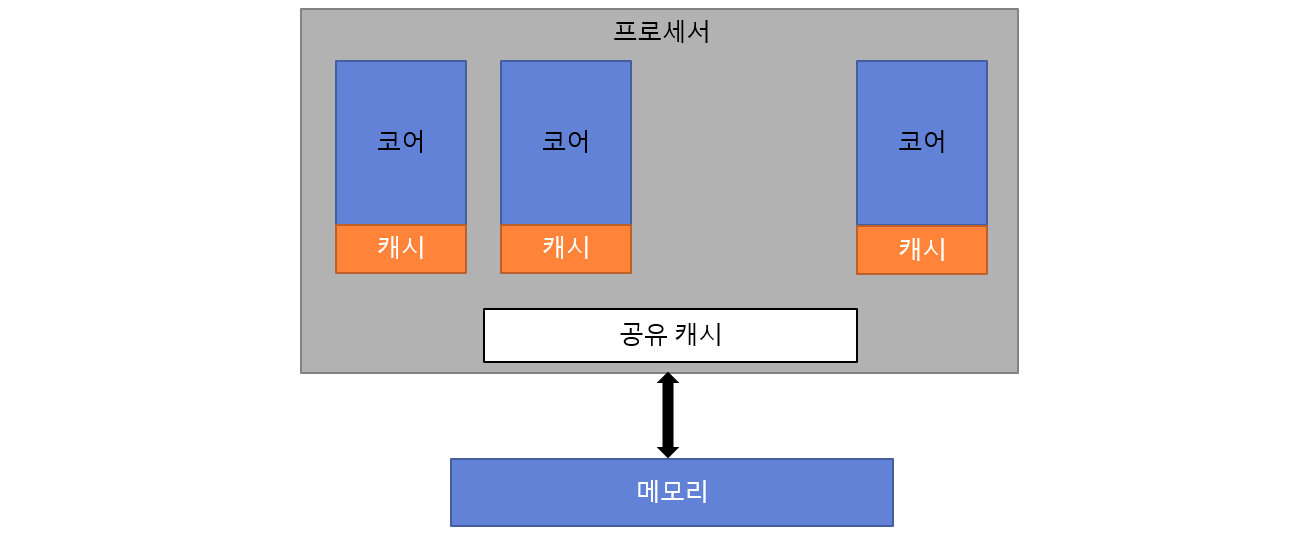
1. 칩 멀티프로세서(CMP)는 멀티코어를 가리킨다. 칩 하나에 여러 코어가 올라오기 때문에 자명하게 메모리를 공유하는 것이 합당하다. CMP는 같은 칩에 있기 때문에 캐시를 공유할 수 있다는 장점이 있다.
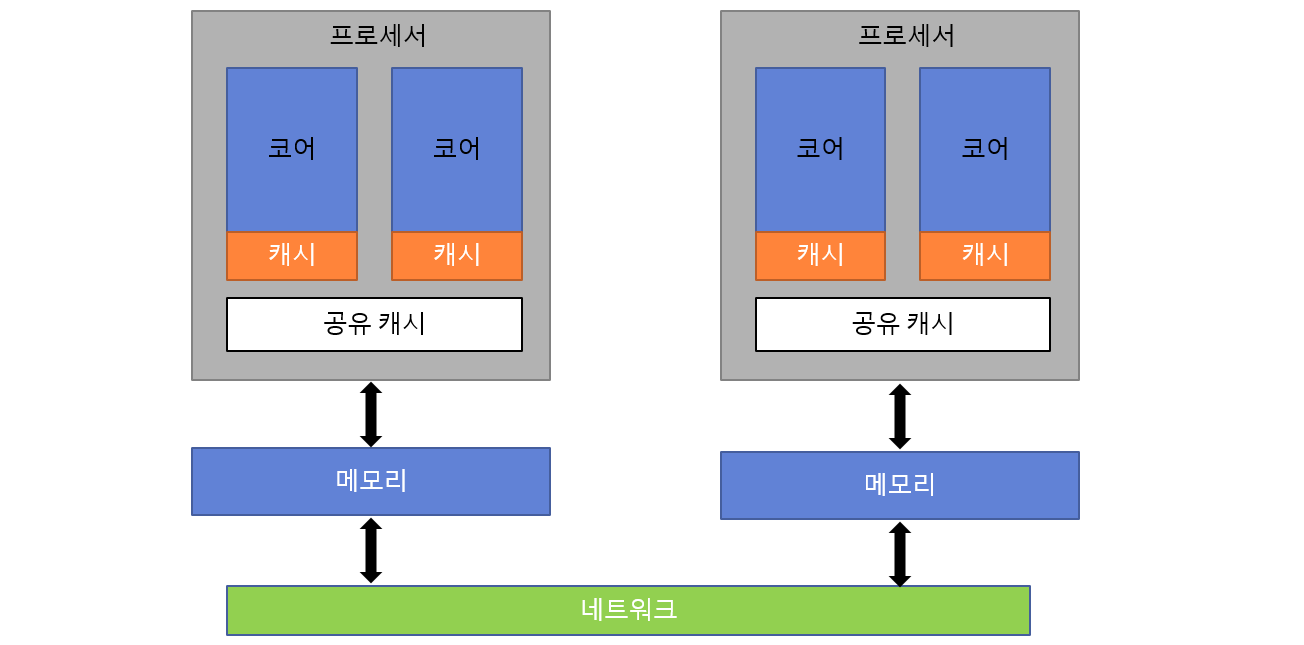
CMP 구조, 한 멀티코어 프로세서(소켓)의 모습
프로세서에는 여러 코어가 있고, 각 코어는 각자 캐시를 가진다. 그리고 프로세서 칩 내에는 모든 코어가 공유하는 캐시가 있을 수 있다. AMD와 인텔 CPU는 모두 이런 공유 캐시를 가진다.
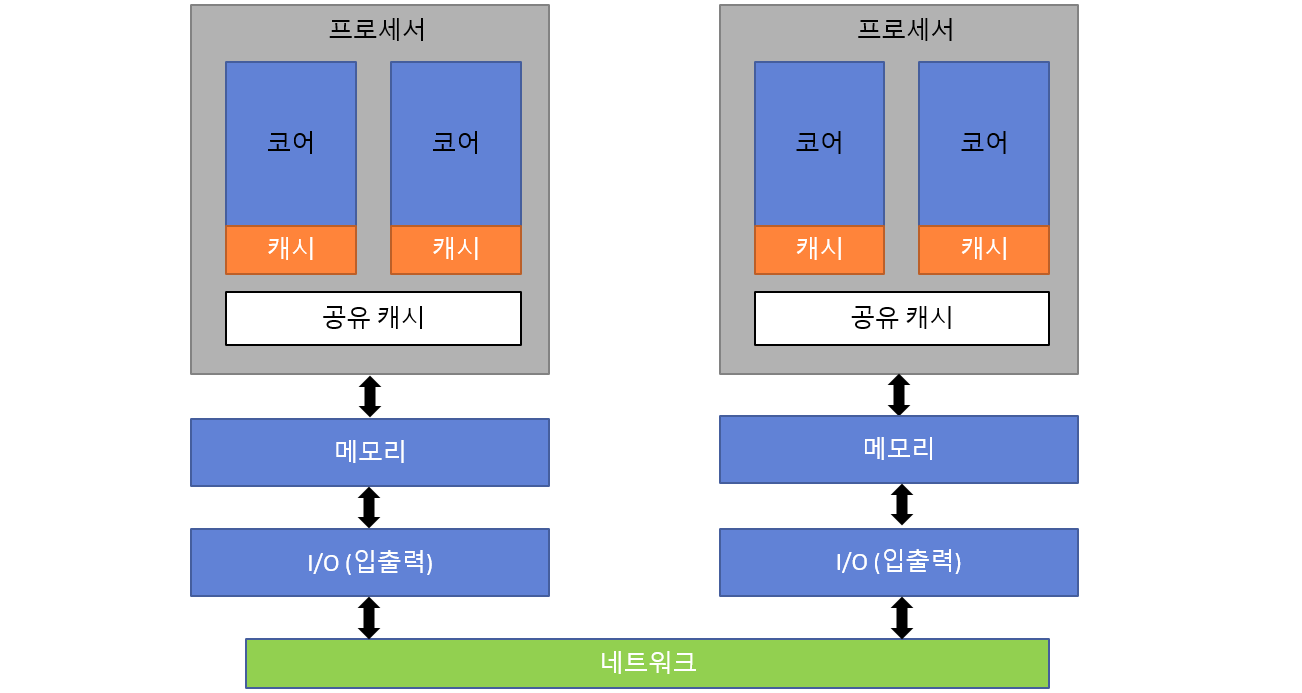
2. 대칭형 멀티프로세서(SMP), 서버용 메인보드를 보면 보통 프로세서를 두 개 혹은 네 개 장찰할 수 있다. 이 때, 일반적으로 같은 종류의 프로세서를 꼽는데 이런 멀티프로세서 환경을 대칭형 멀티프로세서(SMP)라고 한다.
과거에는 하나의 프로세서가 하나의 코어였기 때문에 SMP 구조가 일반적이었다. 개념적으로 SMP는 공유 캐시를 제외하면 CMP와 완전히 같다. 최적화를 고려하지 않는다면 프로그래밍 방법론도 같다.
SMP구조
여러 프로세서가 네트워크라는 장치에 묶여 있고 이것이 메모리와 연결되어 있다. 이 네트워크는 여러 가지가 될 수 있다. 과거 펜티엄 기반의 프로세서는 이것을 프론트 사이드 버스(front side bus)라는 방식이 담당했다. 그러나 AMD와 인텔은 이제 모두 새로운 방식인 HTT(Hyper Transport Technology)와 QPI(Quick Path Interconnect)로 바꾸었다.
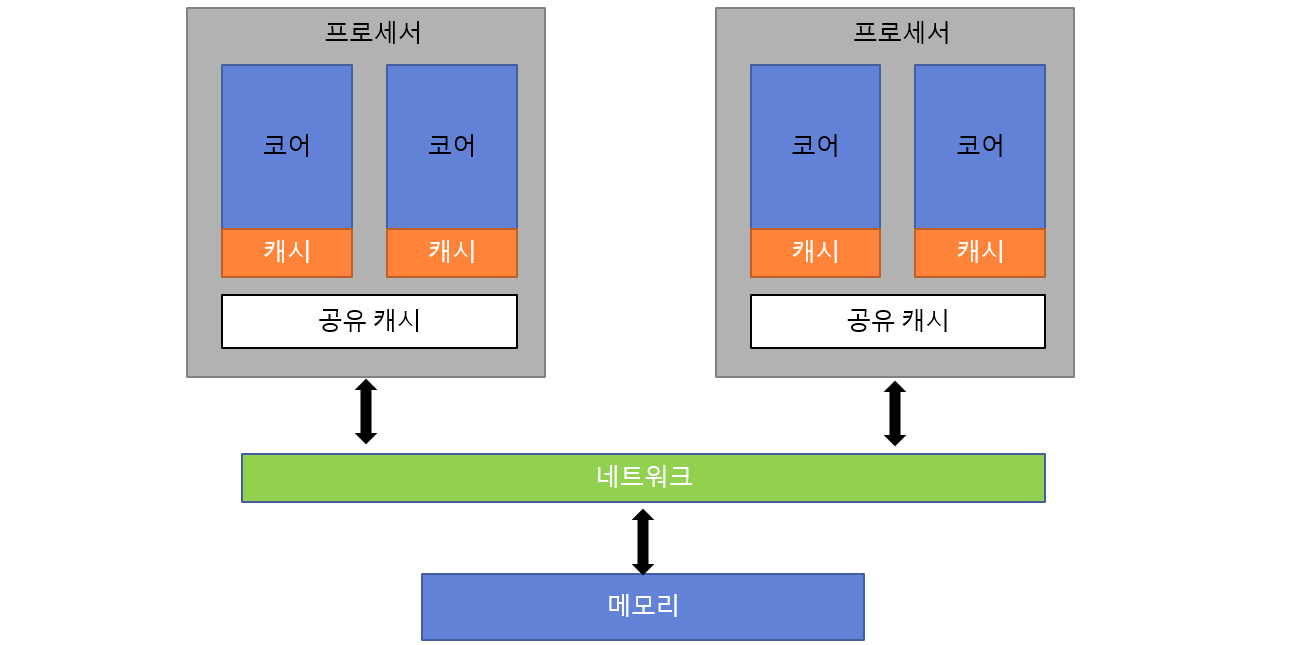
3. 분산 공유 메모리(Distributed Shared Memory), 위 SMP 구조에서 프로세서의 개수가 64개와 같이 아주 많아진다면 분명 메모리에 많은 병목 현상이 벌어질 것이다. 그래서 나온 집중되 공유 메모리를 분산 배치(DSP)한 NUMA(Non-Uniform Memory Access) 구조이다. 이것과 대비되는 구조를 UMA(Uniform Memory Acess)라고도 한다.
In computer science, distributed shared memory (DSM) is a form of memory architecture where physically separated memories can be addressed as one logically shared address space. Here, the term "shared" does not mean that there is a single centralized memory, but that the address space is "shared" (same physical address on two processors refers to the same location in memory).
source: https://en.wikipedia.org/wiki/Distributed_shared_memory
NUMA 구조
NUMA 공유 메모리 구조에서는 시스템 전체적으로는 메모리 주소를 공유하지만, 물리적인 메모리 위치는 떨어져 있을 수 있다. NUMA의 장점은 바로 확장성에 있다. NUMA 구조에서는 한 프로세서와 가까이 있는 메모리로의 접근이 다른 메모리보다 빠르다. 메모리 접근 속도가 물리적인 프로세서와 메모리의 위치에 따라 결정되기에 '비균일' 메모리 접근 속도가 만들어지는 것이다. 따라서 NUMA 환경이라면 이것을 인지해 최적화해야 할 것이다.
여러 가지 최적화 구성 방식이 있었지만, 공유 메모리 환경에서는 모든 프로세서가 같은 주소 공간에 있다는 것은 같다. 기존의 멀티쓰레드 프로그래밍 방법론을 그대로 적용할 수 있다. 물론 캐시, 메모리, 멀티코어 계층 구조에 따라 최적화가 필요하다.(story 18 참고)
분산 메모리 구조
분산 메모리 구조는 다른 말로는 클러스터(cluster) 또는 그리드(grid)라는 표현도 쓴다. 간단히 설명하면 독립적인 컴퓨터를 고속의 네트워크로 연결한 것을 가리킨다. 공유 메모리 구조와 달리 각 컴퓨터는 자신의 메모리 내용만 볼 수 있으므로 다른 컴퓨터(노드)의 내용을 보려면 '명시적인 메시지' 교환이 필요하다. 이 점이 가장 큰 차이고 프로그래밍 방법론에도 큰 차이를 만든다. 수천, 수만 개의 노드를 연결한 슈퍼 컴퓨터가 바로 이러한 구조를 따른다.
분산 메모리 구조
상대방의 데이터에 접근하려면 반드시 명시적인 네트워크로 메시지를 주고받아야 하므로 로컬 메모리 접근보다 훨씬 느릴 것이다.