Object Detection이란 Image가 주어졌을 경우 관심객체의 위치를 찾아내는 기법이다.
1. Template Matching
Object Detection의 대표적인 기법인 Template Matching은 Template이 주어진 상태에서 Template과 동일 한 Object가 원본 이미지 상에 어디에 위치하는지를 알아내는 방식을 이용한다. 즉, 전체 이미지의 구석구석을 주어진 template과 비교하고 유사도를 측정한 후 유사도가 가장 높은 위치를 관심 영역으로 지정한다.

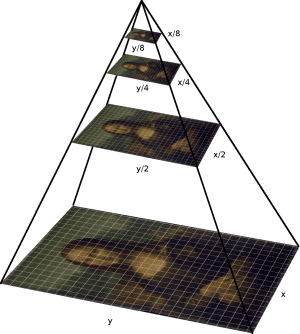
이때 Template matching은 Silding Window 방식을 사용한다. 다만, 한 가지 Issue가 존재하는데, Template에서 주어진 Image와 원본이미지에서 주어진 Object Image의 크기 차이가 존재한다. 따라서 Scale과 Rotation이 일어나는 것을 방지하고자, Image Pyramid기법을 활용한다. Image Pyramid 기법이란 아래에서 보이는 것처럼 여러 Scale로 Pyramid로 만들고, 이렇게 만든 여러 Scale의 Image를 하나씩 Template matching에 활용한다. 이러한 기법은 Sclae에 대한 탐색 뿐만 아니라 회전에 대한 탐색도 수행한다.(다각도로 회전시켜 본 후에 유사도를 측정함.)
Template Matching의 유사도 측정 방식은 다음과 같다.

위의 수식에서 T는 Target Image, I는 원본이미지를 의미한다.
다만 한 가지 Issue가 있다면 사람이 보았을 때 유사한 것과, Computer가 유사하다고 느끼는 방식에는 차이가 존재한다. 이는 생성형 Model에서 문제가 발생할 수도 있다. 예를 들어서 생성 Model에서 성능 측정 시에 평가 지표를 도입하였을 경우 사람과 유사함을 느끼는 방식이 다르기 때문에 서능지표가 옳냐는 Issue가 존재하기도 한다.
2. Bag of Words
Template Matching의 경우 하나의 Image만을 매칭하는 반면, Bag of Words는 여러 개의 Image를 찾을 경우 사용하는 기법이다. Bag of Words는 단어 사전을 만들어 주어진 데이터를 단어들의 Histogram으로 표현하는 방식으로, 기존에는 자연어 처리에서 많이 사용되던 방법이었지만 이미지를 Encoding하기 위해서 적용을 할 수가 있다.
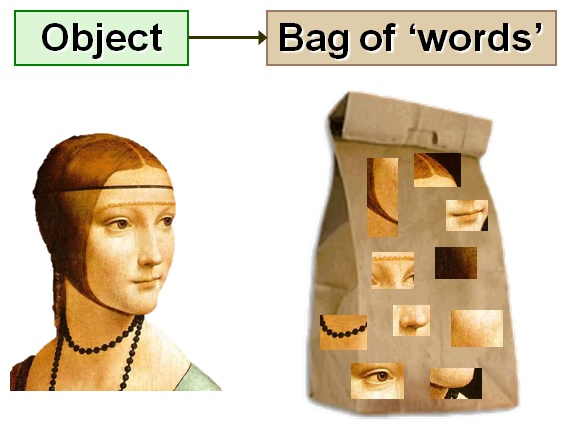
위의 그림으로 간단하게 설명하자면 객체의 특징이 되는 부분들을 모아서 단어장을 만든다.
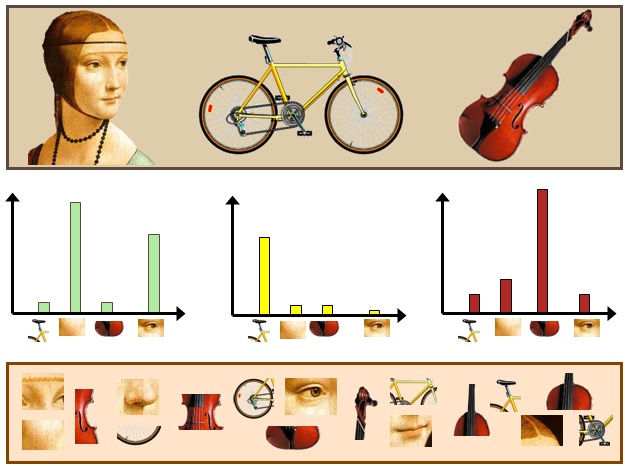
이후에 Image가 입력되면 입력 Image가 단어장에 해당하는 부분이 몇 개인지, 즉, 각각의 특징이 몇 개가 나타나는지 세어서 이를 Histogrma으로 만드는 것이다. Histogram의 모양은 각각의 객체에 따라서 특정한 Pattern들이 나타난다. 최근에는 이러한 Pattern들을 Machine Learning과 Deep Learning을 활용하여 분류하는 작업을 수행한다.
3. HOG(Histogram of Oriented Gradient)
Hog(Histogram of Oriented Gradient)는 방향에 따른 Gradient를 기반으로 Histogram을 만들어 이미지를 표현하는 방식이다.
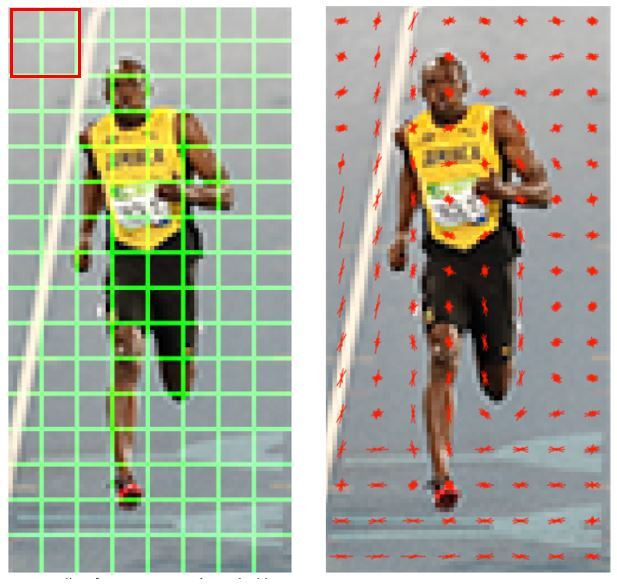
HOG의 계산 방법
보행자 검출을 위한 HOG는 기본적으로 64 x 128 크기의 영상에서 계산한다.
HOG 알고리즘은 먼저 입력 영상으로부터 Gradient를 계산한다.
Gradient는 Magnitude와 Direction 성분으로 계산하며, 방향 성분은 부터 까지 범위로 설정한다. 그 다음 입력 영상을 8 x 8 크기로 분할한다. 입력 영상인 64 x 128 영상에서는 가로 방향으로 8개, 세로 방향으로 16개가 생성된다.
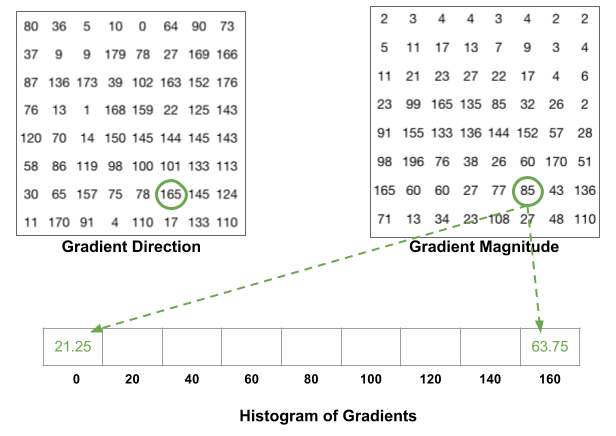
이때 8 x 8 부분 영상을 셀(cell)이라고 하며, 인접한 4개의 셀을 합쳐서 블록(block)이라고 한다. 각각의 셀로부터 그래디언트 방향 성분에 대한 히스토그램을 구하며, 이때 방향 성분을 단위로 구분하면 총 9개의 bin으로 구성된 방향 히스토그램이 만들어진다. 1개의 블록에는 4개의 셀이 존재하고 각 셀에는 9개의 빈으로 구성된 히스토그램 정보가 있다.
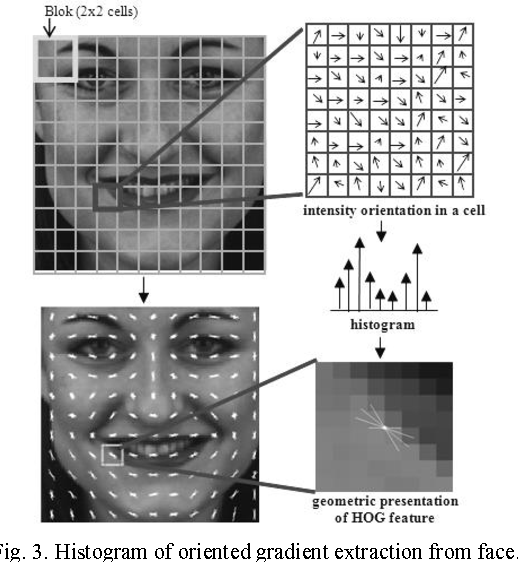
그래서 블록 1개에서는 총 36개의 실수 값으로 이루어진 방향 히스토그램 정보가 추출되고
각 블록은 가로와 세로 방향으로 각각 1개의 셀만큼 이동하면서 정의한다.
입력 영상인 64 x 128 영상에서 블록은 가로 방향으로 7개, 세로 방향으로 15개로 정의할 수 있다.
계산해보면 105개의 블록이 추출될 수 있고, 전체 블록에서 추출되는 방향 히스토그램 실수 값 개수는 이 계산된다. 이 3780개의 실수 값이 64 x 128 영상을 표현하는 HOG 특징 벡터 역할을 한다.
즉, 과정을 간략히 정리하면 다음과 같다.
- 각 Pixel별 gradient를 계산
- 8 x 8 pixel로 묶은 cell로 영상을 구분하고, 각각의 cell에서 gradient 방향에 대한 Histogram을 구함.
- 2 x 2 cell을 하나의 block으로 묶고 해당 block 내에서 L1, L2 정규화를 진행
(1) L1 Normalization
(2) L2 Normalization
하나의 block 내의 Histogram을 Vector로 변환 : 2x2x9 = 36dim vector
해당 vector의 크기가 1이 되도록 정규화 하는 것임.
- 모든 block의 vector를 연결하여 하나의 image representation vector구성
차원 : 전체 block의 수 x 36(block 당 vector 크기)
이번 포스트에서 나오는 HOG의 경우 다음 포스트에 대해서 나올 SIFT알고리즘의 Descripter로도 사용된다.
다음 포스트에서는 Local Feature matching에 대해서 다루어 보고자한다. 수업 상에서는 Camera Parameter와 Stereo Matching 중간에 나왔지만, 개인적으로 생각할 때는 Camera Parameter를 이후 Stereo Matching을 연결시키는 것이 자연스럽다고 생각했다.(물론...나같은 학부과정따리가 교수님의 깊은 뜻을 못 헤아려서 그런 것도 있다...) 여하튼 이번 포스트는 이렇게 마무리하도록 하겠다.
