
Local Feature Matching이란 Image 내의 객체의 특징이 되는 점을 matching하는 기법이다.

1. why do we need Keypoint?
Key point란 주어진 이미지에서 특징이 되는 점을 말한다. 즉 다른 지점과는 구분되는 특징이 되는 점들이다. Image 내에서 특징점이라고 한다면 Coner, Edge 등과 같은 부분이 될 수 있을 것이다. 그렇다면 왜 이러한 특징점이 중요할까?
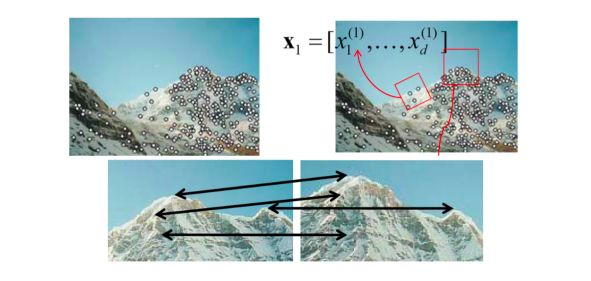
다른 시점에서 동일한 물체를 촬영하여도, 만약 특징점을 알고 있다면 두 이미지에서 같은 물체, 지점을 찾아낼 수 있다. Keypoint의 활용방법에 대해서 잠시 살펴보자.
먼저 Image Matching을 통해서 특정 물체를 주어진 이미지 상에서 찾을 수 있다.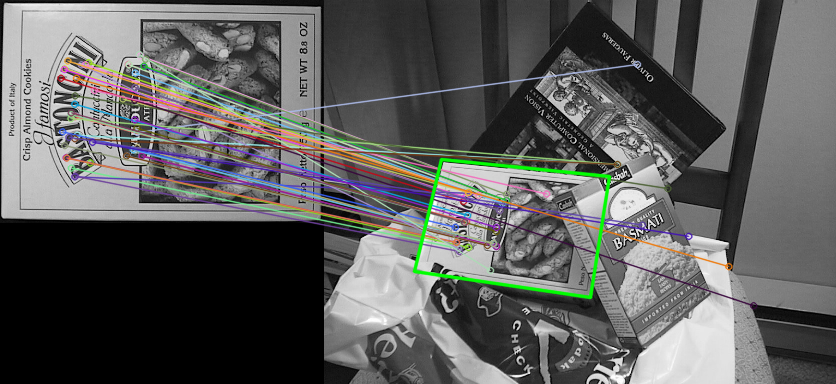
또한 Key point를 활용하여 미리 수집된 영상데이터를 보고 현재 위치가 어디인지 찾아내는 Visual localization이 가능하다.

이러한 Key Point를 통해서 파노라마 영상 쵤영이 가능하다.(사진과 사진의 Overlab되는 구간을 해결해줌.) 간단하게 설명하자면, Keypoint matching을 통해 두 사진에서 같은 지점을 탐색하고,찾아낸 같은 지점끼리 겹치도록 이어붙이는 방식이다.
이러한 Keypoint matching(local feature matching)을 위해서 2가지 요소를 필요로 한다.
- Feature Extractor(Keypoint detector): 영상 내에서 특징점이 될 만한 지점을 찾아냄.
- Feature Descriptor: 검출된 Keypoint마다 해당 위치를 기술할 수 있는 서로 구분되는 값을 할당하여 각 Keypoint가 matching 될 수 있도록 함.(간단하게 설명하자면 ID를 부여한다고 생각하면 된다.)
2. Harris Corner Detector
Visualizing Quadratics
Corner Detection 이전에 먼저 알아야할 것이 바로 Visualizaing Quadratics, 2차식을 시각화하는 작업이다.
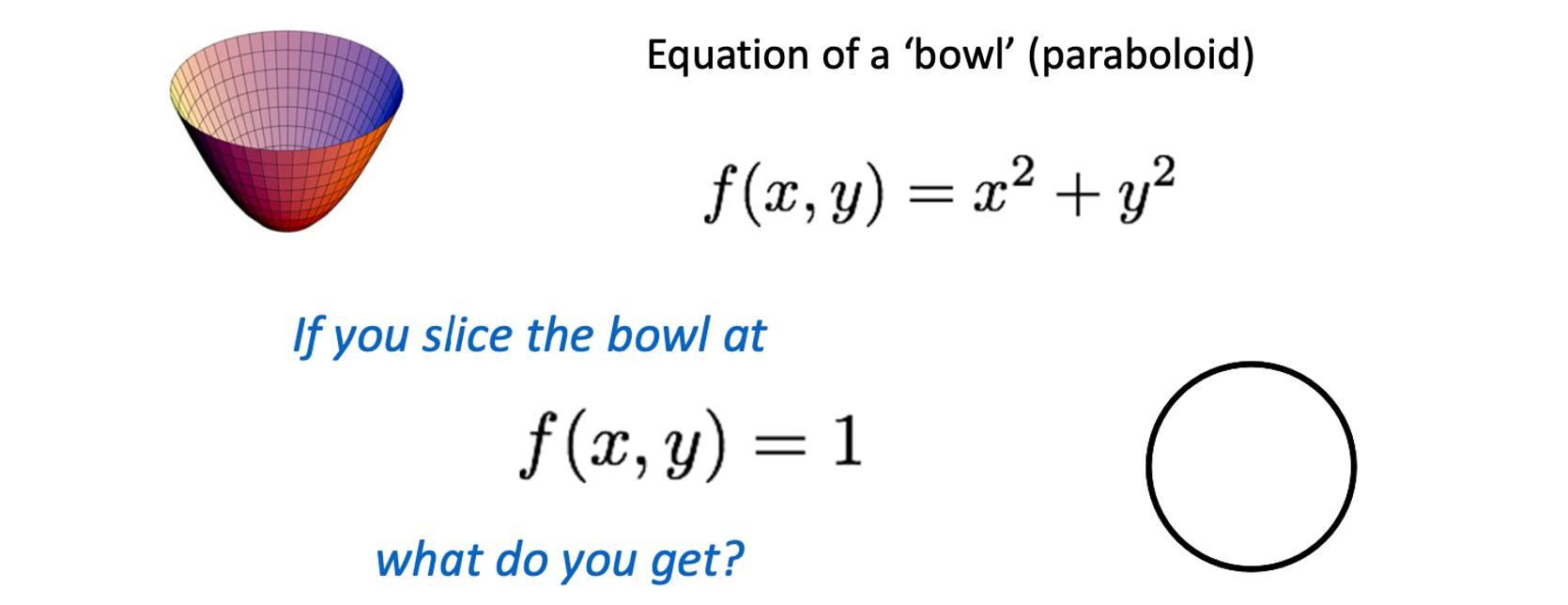
에서 이 반지름임을 이미 알고 있다. 이미 1학년 Calculus에서 배워서 알고 있겠지만(너무 오래되서 언제 배웠는지 정확히 기억나지는 않는다.), 를 3차원으로 표현한다면 위의 그림과 같이 bowl 모양을 가지게 된다는 것을 알고 있을 것이다. 이를 Paraboloid라고 한다. 이 Paraboloid를 가 1인 지점에서 평면으로 자른다면 위와 같이 반지름이 1인 원이 나올 것이다. 마찬가지로 에서 자른다면 인 원이 될 것이다. 해당 를 matrix로 나타내보면 다음과 같다.
그렇다면 가운데에 있는 matrix를 일부 수정해서
와 같이 바꾸고 를 1에서 자른다면 Ellipse Equation이 될 것이다.
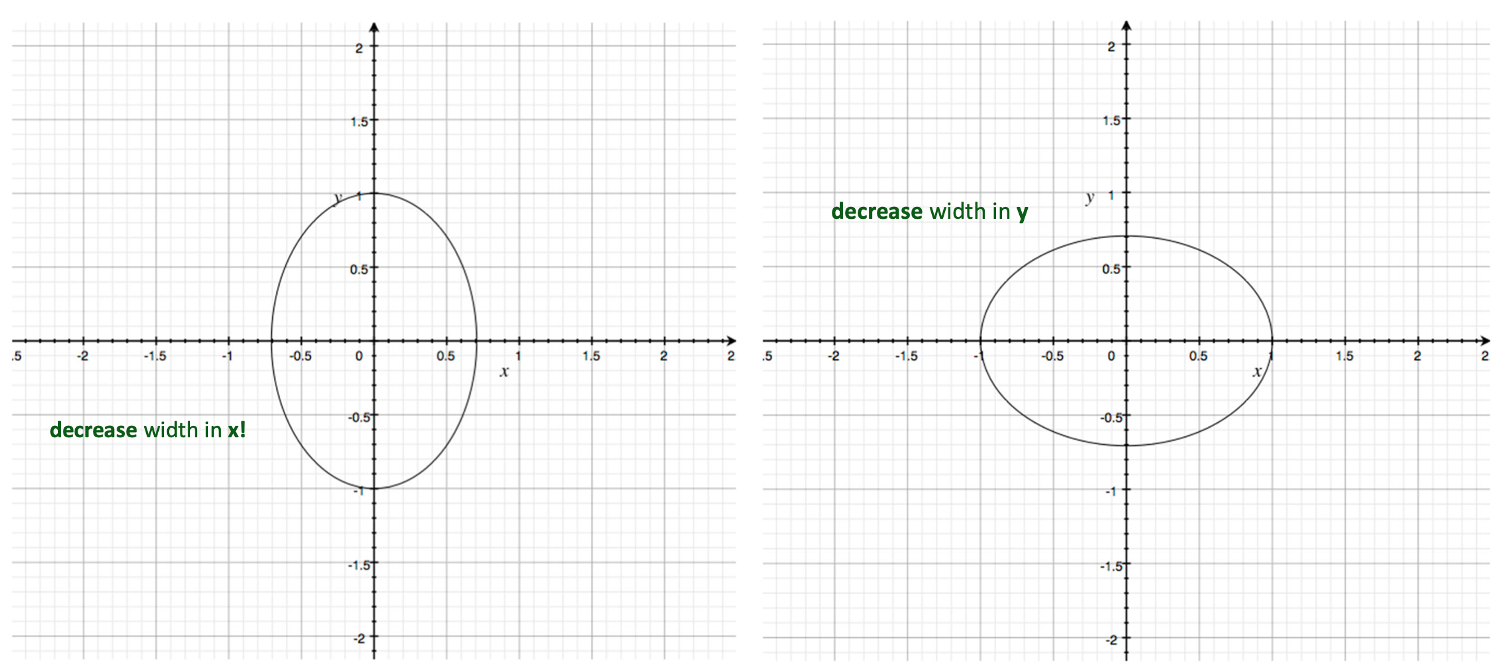
오른쪽 Ellipse는 수식이 다음과 같을 것이다.
그렇다면
위의 수식에서 가운데에 있는 Identity matix에 SVD(Sigular Value Decomposition)을 적용해 보자.
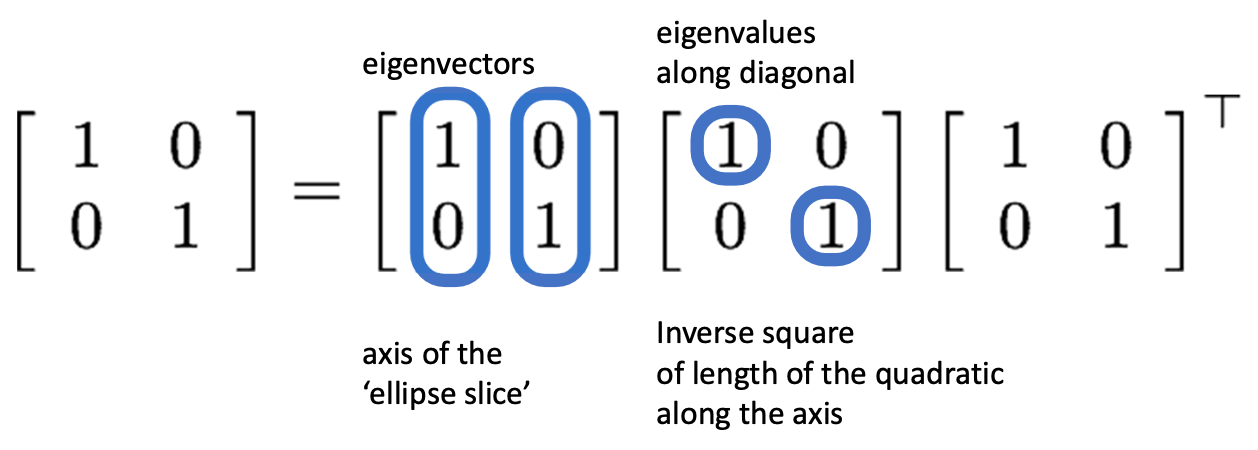
결과는 다음과 같을 것이다. 첫 번째 matrix에 있는 두 개의 값들이 eigenvector이며, 가운데 matrix의 대각선에 위치한 값들이 eigenvalue이다. 해당 수식을 Paraboloid를 통해서 Geometic하게 해석해보면 eigenvector는 Paraboloid를 슬라이스한 Ellipse의 Axis가 될 것이고, eigenvalue는 타원의 긴 반지름, 작은 반지름의 역수가 된다는 것을 Linear Algebra에서 배웠을 것이다. 이것을 통해 알아야 할 것은 의 가운데 matrix가 bowl의 형태를 결정짓기 때문에, 이를 잘랐을 때의 모양도 이 matrix가 관할하게 된다는 것이다.
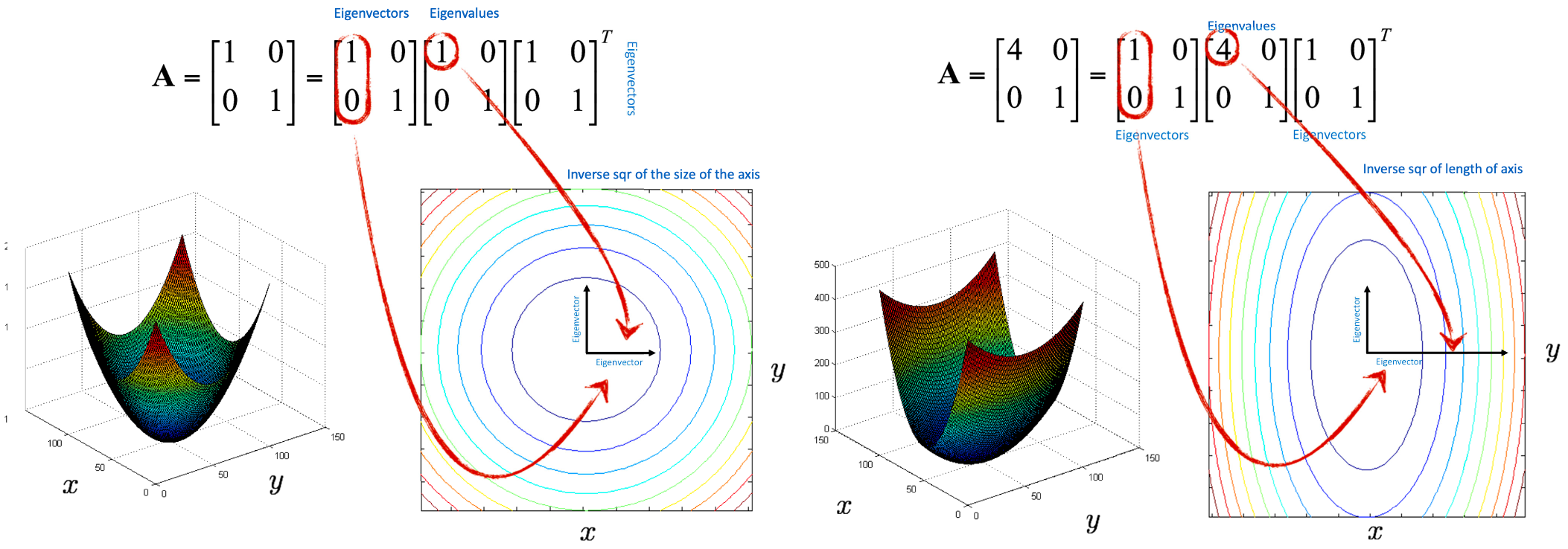
위의 그림으로 설명해보자면 오른쪽의 첫 번째 eigenvalue가 4이기 때문에 에 대한 반지름이 이므로 에 대한 긴 반지름이 2배가 되는 ellipse의 형태가 될 것이다.
Harris Corner Detector
Harris Corner Detector는 Corner를 검출하는 Gradient 기반의 KeyPoint Detector이다. 그렇다면 Corner의 특징이 무엇일까?
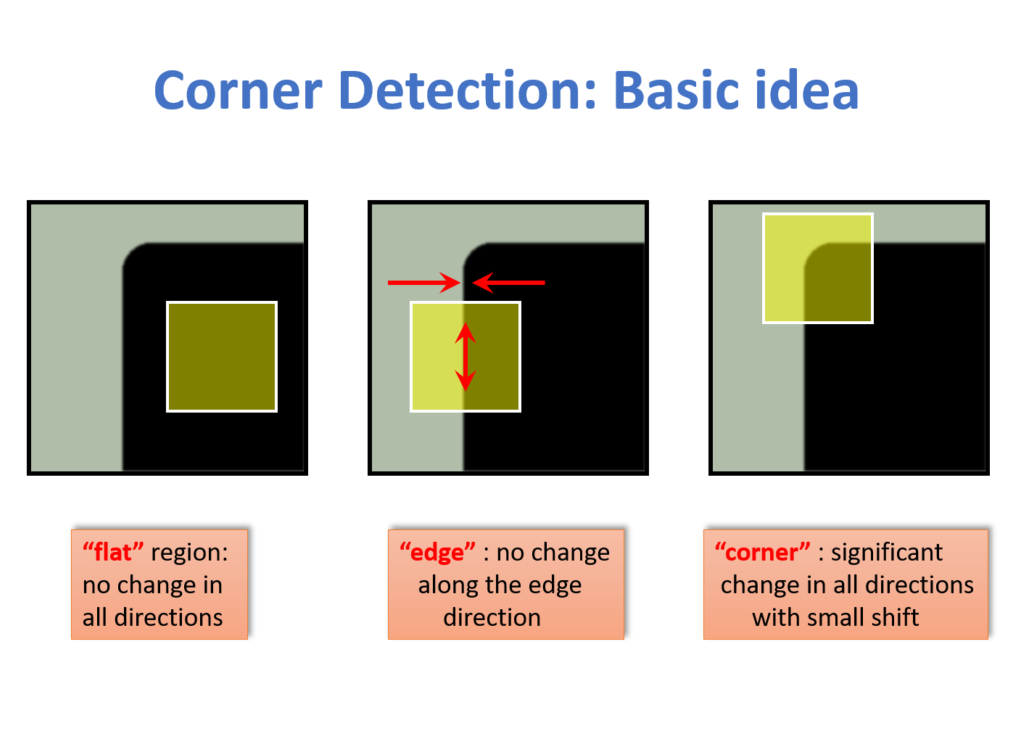
Corner는 위의 Figure에서 보듯이 모든 방향으로 Pixel값의 변화량이 크다. 따라서, 이미지 상의 어떤 지점에서 Pixel의 Gradient를 측정하고, 그 크기가 모든 방향에 대해서 크다면 Corner라고 판단할 수 있을 것이다.
Harris Corner Detector가 수행하는 과정을 정리하면 다음과 같을 것이다.
- Compute image gradients over small region
- Subtract mean from each image gradient
- Compute the covariance matrix
- Compute eigenvectors and eigenvalues
- Use threshold on eigenvalues to detect corners
Compute image gradients over small region

5 x 5인 Image Patch를 활용하여 각기 다른 형태의 이미지에 대하여 derivative를 수행한 결과이다. 가장 오른쪽의 Corner 결과에서 모서리에 해당하는 곳에서 X derivative 와 Y derivative가 모두 큰 것을 확인할 수 있다. Graph를 통해서 표현하면 아래와 같을 것이다.
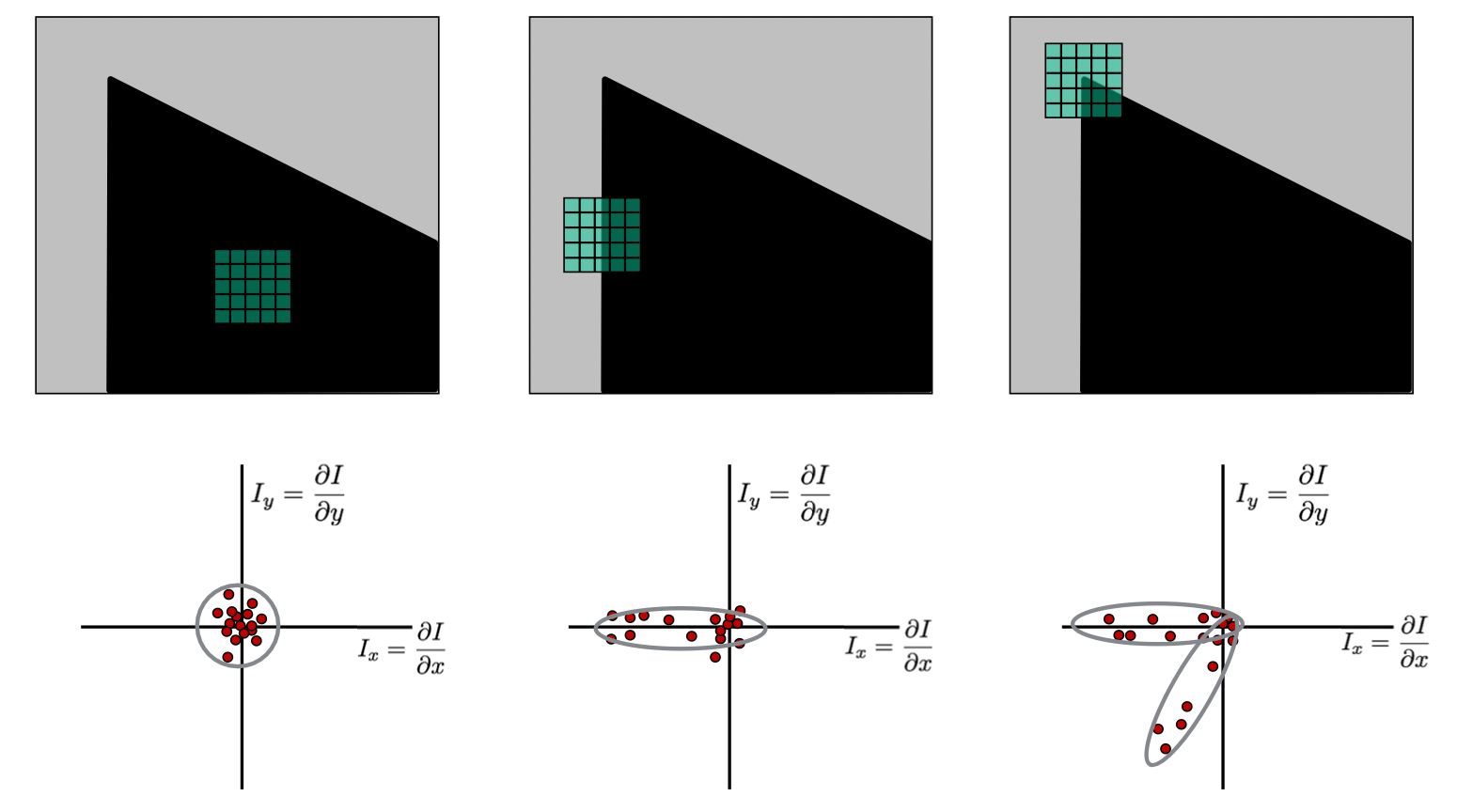
- Flat 영역: 와 가 모두 작으므로 분산이 적다.
- Edge 영역: 의 절댓값이 크고 는 작으므로 한쪽으로 길게 분포된 형태를 볼 수가 있다.
- Corner영역: Patch 내에 검정 영역이 수직으로 되어 있는 부분에 대해서는 edge 영역과 같이 나온다. 대각으로 떨어진 영역을 보게 되면, 와 는 어느 정도 절댓값을 같기 때문에 좌표에 대각선으로 분포하게 된다. 즉, Corner 영역에서는 , 두 개로 분리되어 분포하게 된다.
Subtract the mean from each image gradient
Image의 Edge 영역의 경우에는 필연적으로 그라데이션이 존재하게 된다. 아래의 Intensity(강도) graph에서 Gradient(기울기)가 큰 부분이 Edge라고 말할 수 있다. Edge 양쪽에도 기울기가 존재하기에 Edge 라고 생각하게 될 수 있지만 실제로는 그 값이 매우 작은 그라데이션 영역인 것이다.
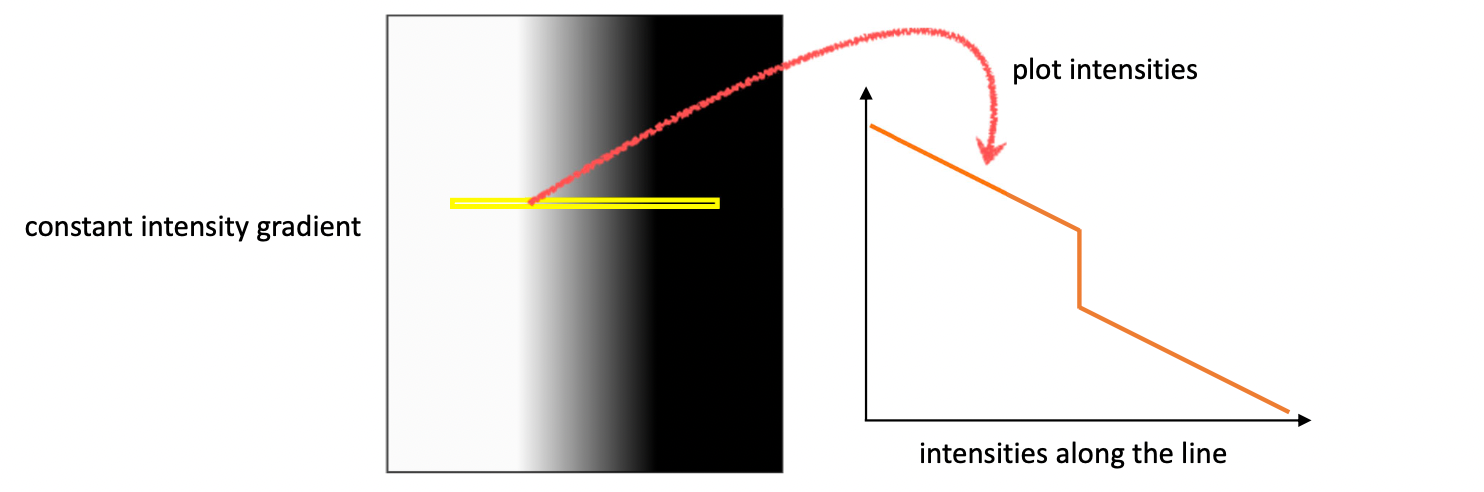
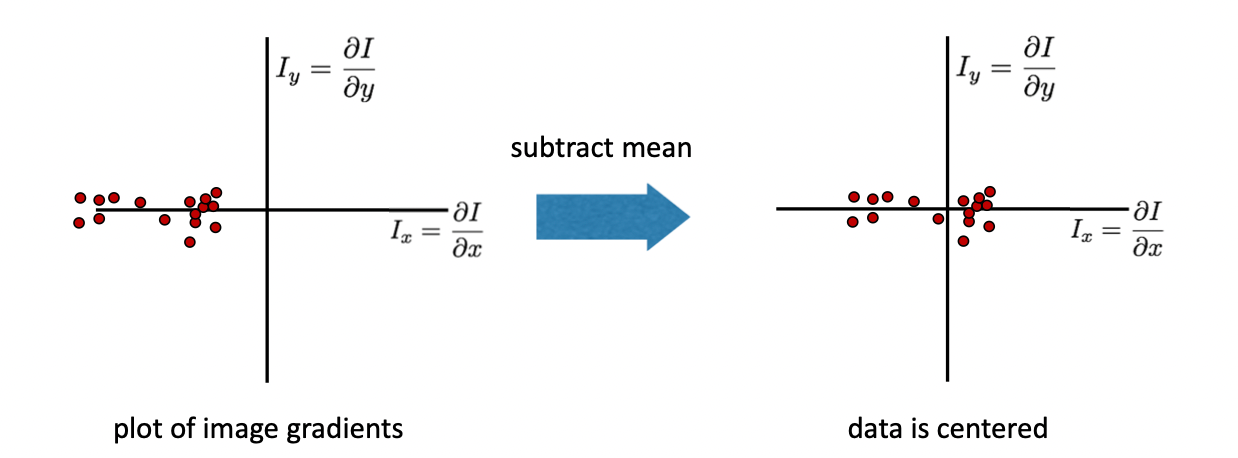
전체적으로 기울기가 어느 정도 존재하기 때문에 위 그림의 왼쪽 그래프와 같이 분포가 왼쪽으로 편향되어 있는 것을 확인할 수 있다. 이러한 편향을 보정하기 위하여 mean(평균)을 빼준다. 그러면 값들이 아래 Figure와 같이 원점을 기준으로 평행 이동하게 된다.
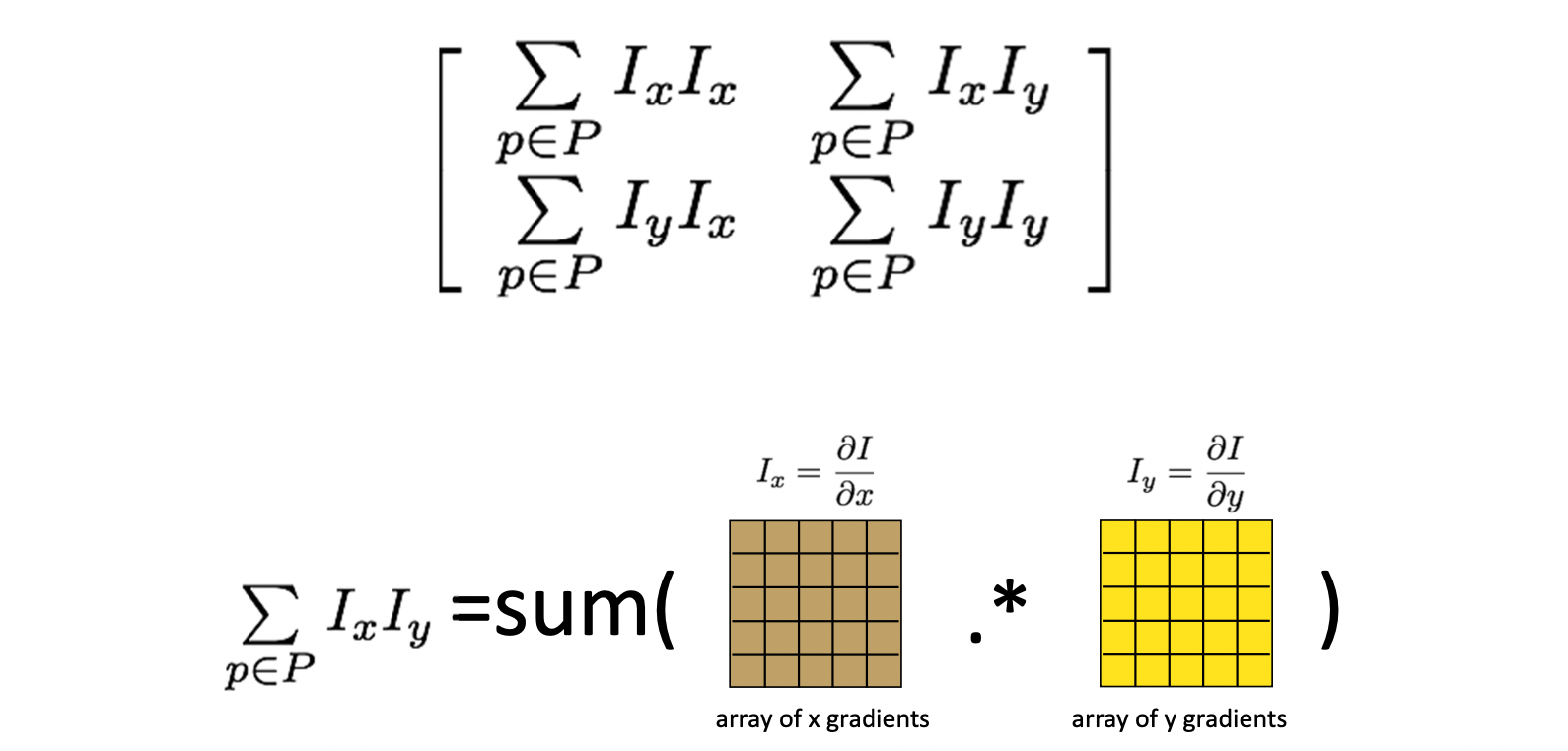
Compute the covariance matrix
Covariance Matrix 즉, 공분산 행렬은 아래와 같다.
Covariance Matrix에 대해서 잘 모를 수도 있어서 살짝만 설명하고 넘어가겠다.
인공지능을 공부해보았다면 Covariance가 두 Data 간의 관계를 나타내는 식이라고 이해할 것이다.
예를 들어서 [a, b, c]라는 데이터가 있고 해당 data의 평균은 m, [d, e, f]라는 데이터의 평>균은 n이라고 하자. 그러면 공분산(Covariance)는 다음과 같이 구할 수 있다.
이를 표준화 한다면 수식은 다음과 같다.
그렇다면 Covariance Matrix는 무엇일까? Covariance matrix란 Covariance와 Matrix의 기하학적인 의미가 합쳐진 matrix이다.(아래수식에서 는 가 퍼진 정도, 는 가 퍼진 정도를 의미한다.)Covariance matrix는 여러 변수의 분산(각 변수의 퍼짐) 과 공분산(변수들 사이의 함께 움직임) 을 한 번에 담아 놓은 행렬이다. 즉, 단순히 cov 값을 하나 계산하는 것을 넘어, 데이터가 2차원(또는 그 이상) 공간에서 어느 방향으로 얼마나 퍼져 있는지를 표현한다. 결국 covariance matrix는 데이터의 분포를 “타원”으로 보았을 때, 타원의 크기(퍼짐) 와 기울어진 방향(상관 구조) 을 결정하는 핵심 정보라고 볼 수 있다.
다시 본론으로 돌아가서 위 Figure에서 는 element-wise product을 의미한다.
즉, 같은 크기의 두 행렬 에서 같은 위치 Pixel의 값끼리 곱해 새로운 행렬을 만든다.
그 다음에는 이렇게 만들어진 행렬의 모든 원소를 합하여 하나의 스칼라 값을 얻는다.
또한 곱셈은 순서를 바꿔도 같으므로 이고, 따라서
가 되어 공분산 행렬이 symmetric이 되는 이유를 설명할 수 있다.
쉽게 설명하자면 말 그대로 Covariance 이기 때문에 어떤 하나가 변할 때, 즉 x 축이 변할 때 y 축이 얼마나 변하는지를 나타내주는 행렬이 바로 Covariance Matrix이게 되는 것이다.
이를 활용하여 Flat, Edge, Corner를 구분할 수 있겠다는 것이 핵심 아이디어라고 할 수 있다.
그렇다면 window를 만큼 얼마나 움직였을 때 얼마나 달라지는 지 Error Function을 정의해 보자.

는 Image를 만큼 평행이동한 값과 원래의 값을 빼어주어 곱하는 식이다. 해당 식은 이미지의 전체 영역에 대하여 계산하기 때문에 우리의 윈도우 영역으로 이를 한정해주는 함수가 필요한 데 이것이 바로 Window Function이다.
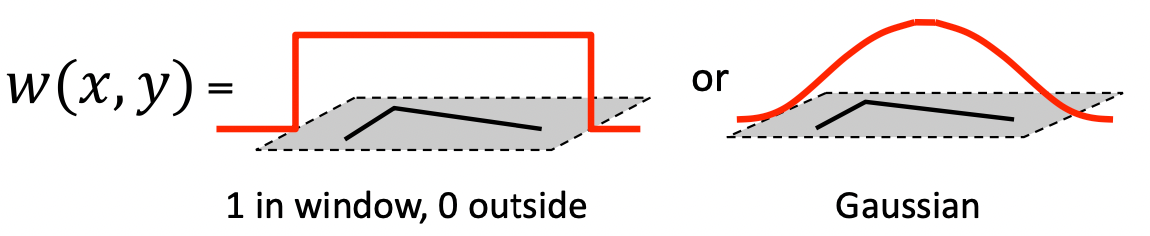
Window 영역에서만 1이고, 나머지 부분을 0으로 하여 Window 부분만만 고려할 수도 있고 오른쪽과 같이 Gaussian 을 적용할 수도 있다. 이때, 는 매우 작다는 것을 이용하면
와 같이 Approximation이 가능하다. 이를 대입해서 Error Function 을 다시 쓰면 quadratic equation이 나오게 된다.
이를 Matrix 형태로 정리하면 다음과 같을 것이다.
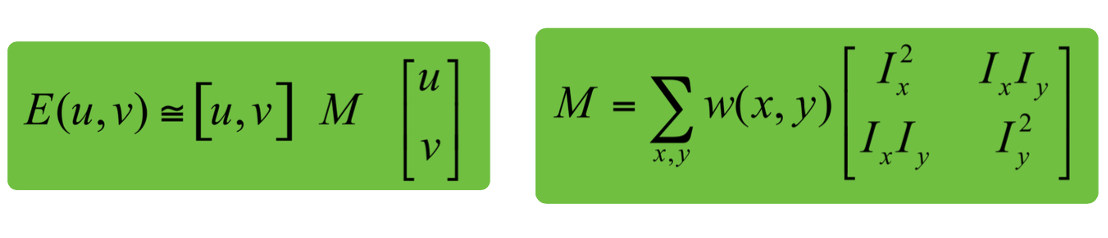
에서 Covariance Matrix를 확인할 수 있으며, 이러한 matrix를 second moment matrix 혹은 structure tensor라고 한다.이를 통해서 를 축으로 하는 차원 Surface를 그릴 수 있으며 이를 보고 flat, edge, corner인지를 판단한다.
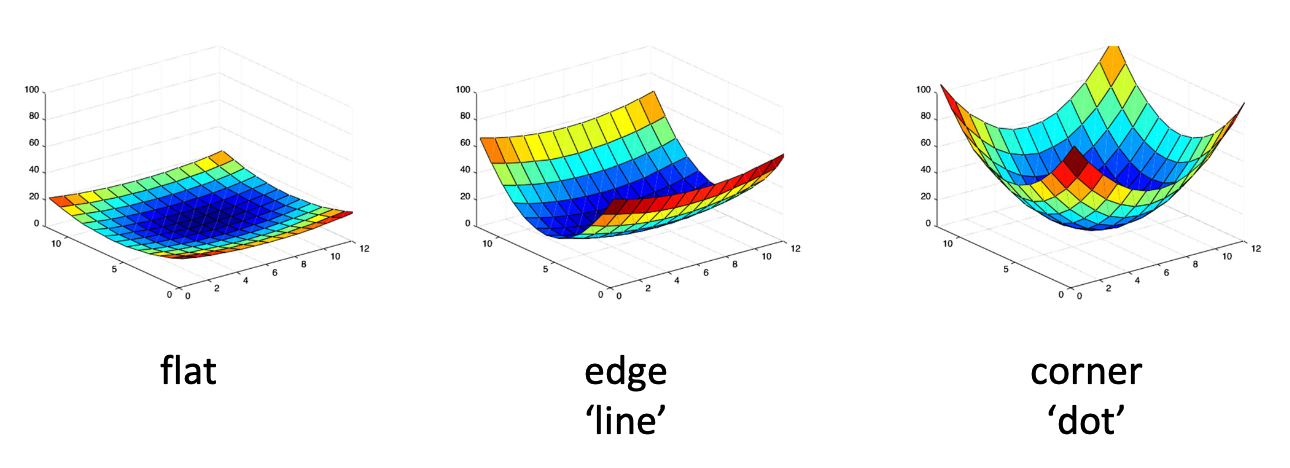
마지막 가장 오른쪽 그림은 어디로라도 값의 변화가 크기 때문에 corner가 된다.
Compute eigenvectors and eigenvalues
컴퓨터는 3D surface 그림을 직접 보고 판단하지 않으므로, 수치적으로 corner,edge,flat을 구분할 기준이 필요하다. 앞에서 얻은 error function은 다음과 같이 쓸 수 있다.
여기서 은 (가중치 를 포함하면) 다음과 같은 형태의 대칭행렬이다.
대칭행렬 은 항상 고유값분해(eigendecomposition)로 아래처럼 표현할 수 있다.
- 의 각 열벡터는 의 고유벡터(eigenvector)이며, 타원의 축 방향을 결정한다.
- 는 고유값(eigenvalue)이며, 그 축 방향으로 얼마나 민감하게 값이 변하는지(곡률/퍼짐)를 결정한다.
이제 좌표를 고유벡터 축으로 바꿔보자.
그러면 error는 다음처럼 아주 단순해진다.
즉 (상수)인 등고선은
이므로 ellipse)이 된다.
이때 타원의 두 반지름은
로 해석할 수 있다.
따라서 가 클수록 해당 방향으로 가 더 빨리 증가하므로(더 “가파름”), 타원의 반지름은 더 작아진다.
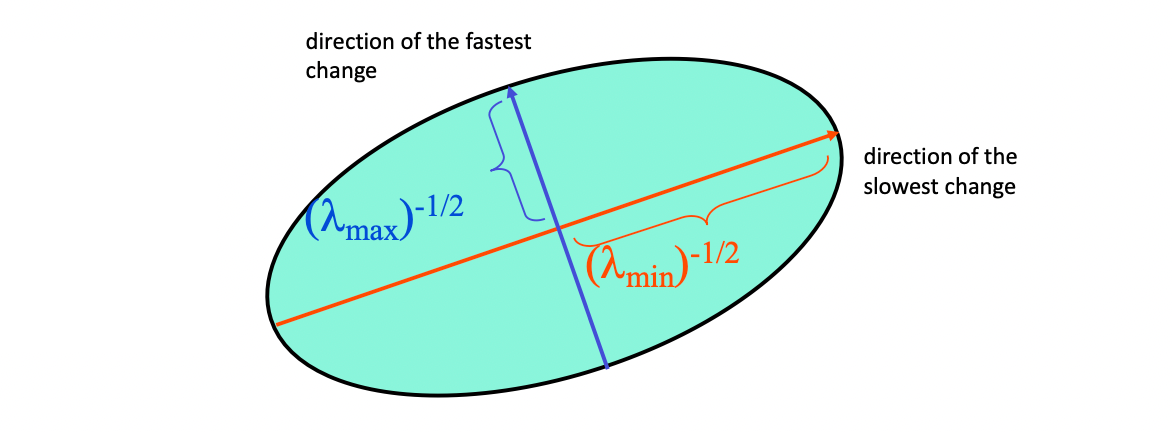
이 성질로 flat,edge,corner를 구분할 수 있다.
- Flat:
로 조금 움직여도 가 거의 변하지 않는다. - Edge: (또는 반대)
어떤 한 방향(엣지 방향)으로는 움직여도 변화가 작고, 수직 방향으로만 변화가 크다. - Corner: 둘 다 큼
어느 방향으로 움직여도 가 크게 증가한다.
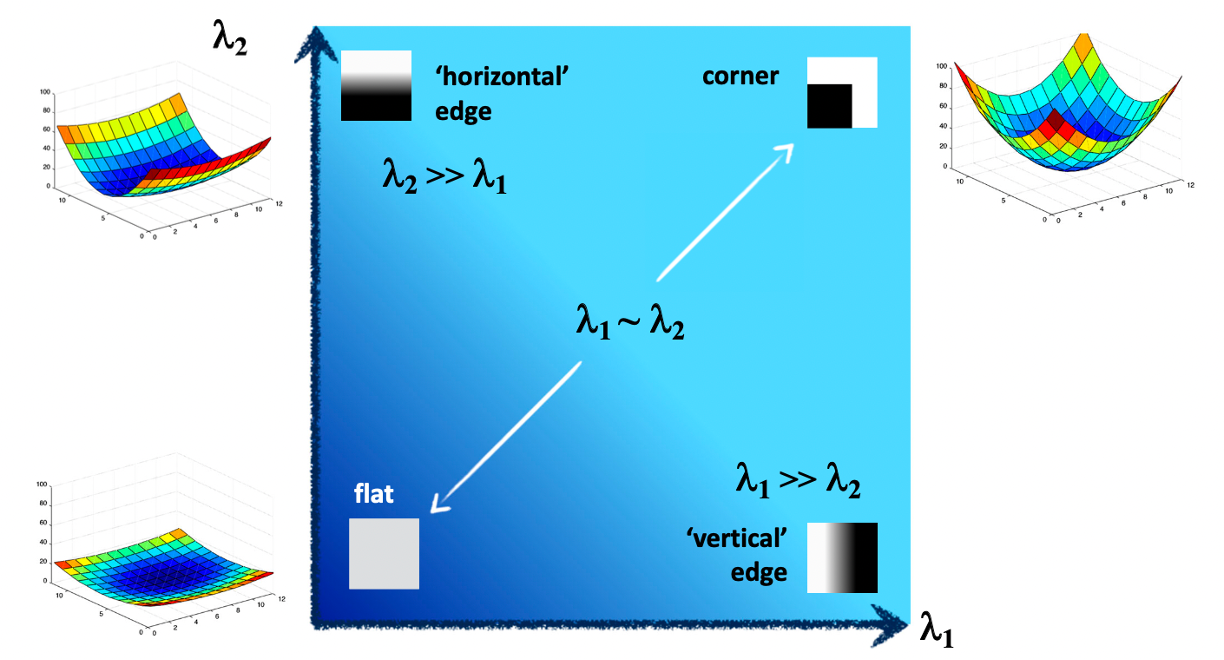
Use threshold on eigenvalues to detect corners
그럼 와 가 어떤 값보다 클 때 corner라고 해야 할 것인가? thresholding 을 해야 하는 값이 , 로 두 개이기 때문에 우리는 이 두 값을 모두 적용한 하나의 기준 이 되어줄 응답 함수 이 필요하다. 가장 간단하게 생각할 수 있는 것은 이다.
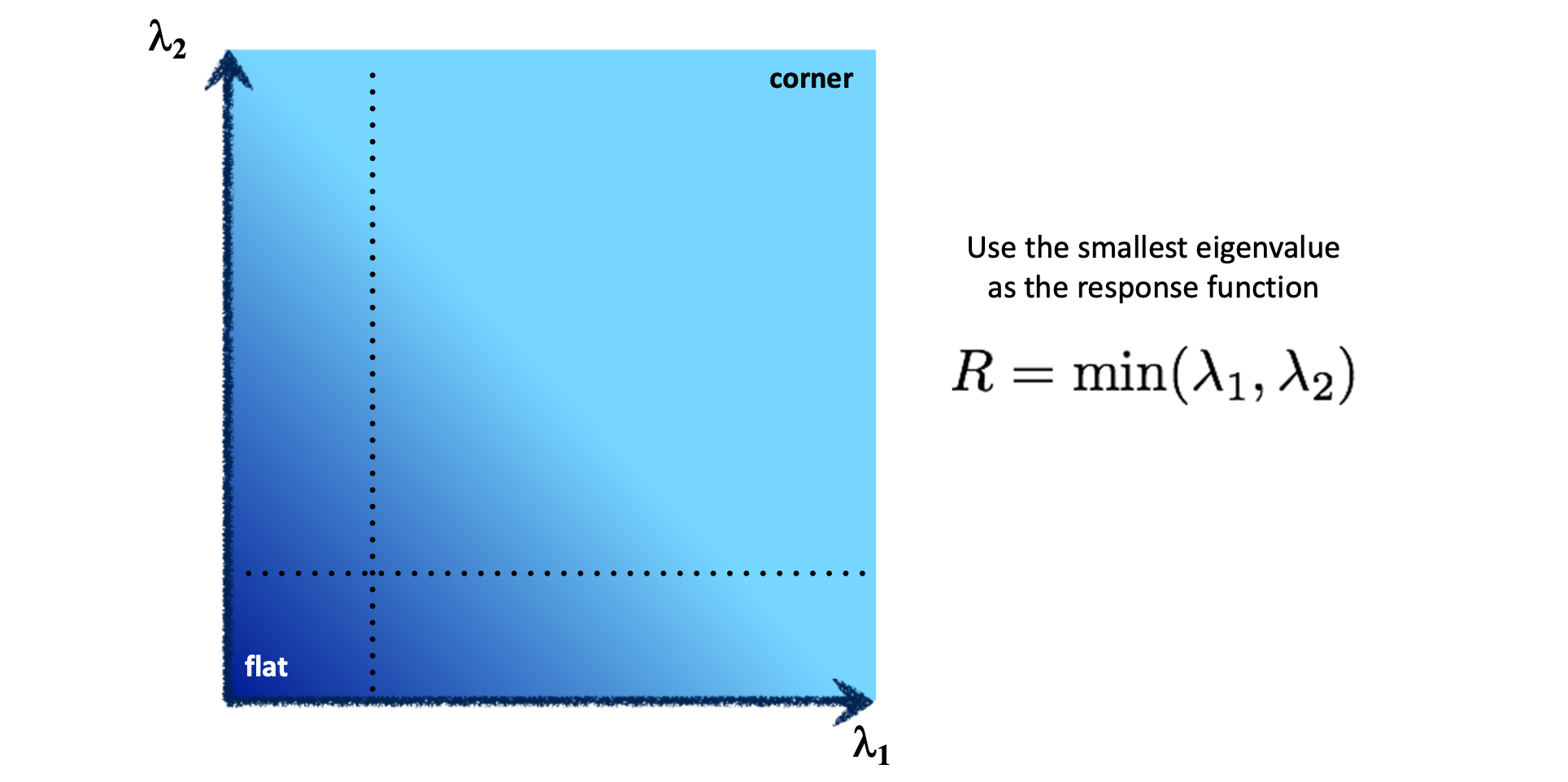
Harris Corner Detector에서 사용하는 응답함수 는 다음과 같다.
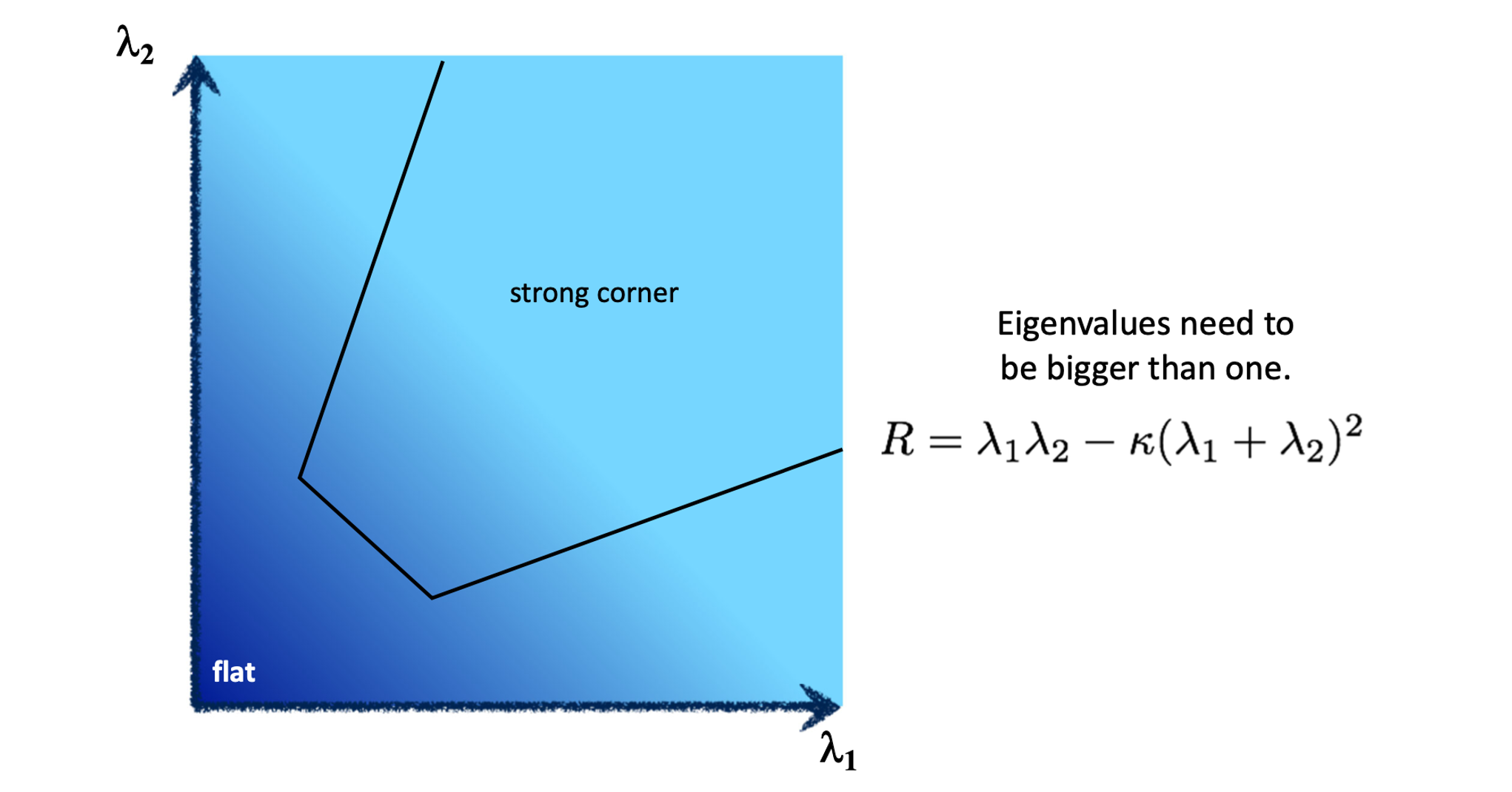
이 식에서 쓰이는 항인 와 는 아래 그림과 같이 matrix 에서 determinant 와 trace 를 활용하여 구할 수 있다.
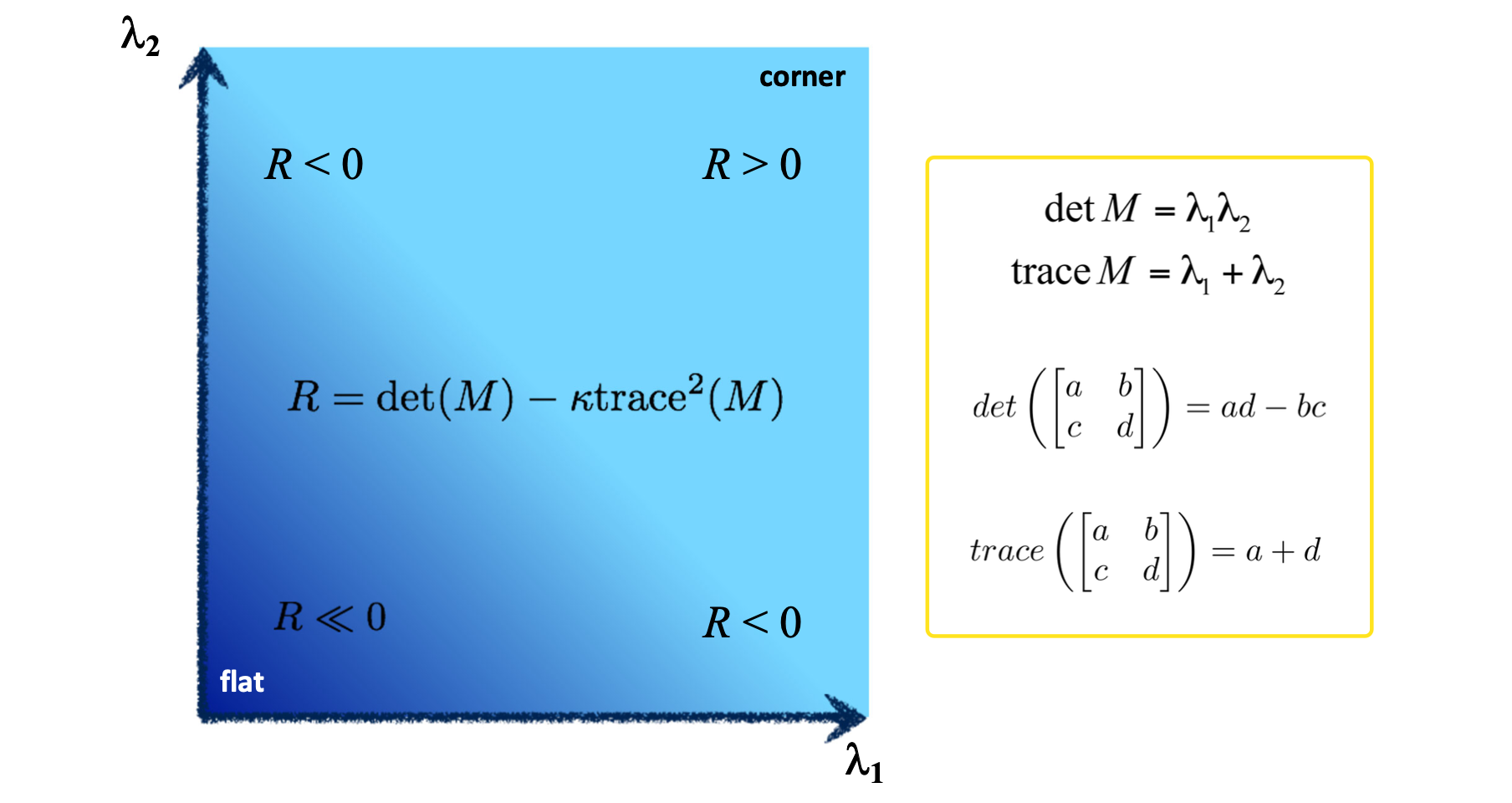
해당 을 활용하면 0보다 클 경우에 Corner라고 판단할 수 있게 된다.
3. FAST(Features from Accelerated Segment Test)
FAST알고리즘을 속도를 빠르게하기 위한 알고리즘이다. 이에 관련해서는 간략하게 설명하도록 하겠다.(하다보니 너무 많은 내용을 적고 있는 것 같다.)
FAST 알고리즘은 다음과 같이 이루어진다.

- 하나의 Pixel P를 선택, 는 픽셀의 강도(밝기)
- 임계값 를 설정
- P 주위의 16개의 Pixel의 원을 구함.
- 원에서 연속된 n개 이상의 픽셀이 보다 어둡거나, 보다 밝다면 픽셀 P를 코너로 판단함.
- 알고리즘 가속을 위하여 처음부터 16개의 Pixel 모두를 검사하는 것이 아니라 1, 5, 9, 13번 Pixel만 검사하는데 이 중에서 적어도 3개는 보다 어둡거나 보다 밝아야 함.
4. SIFT
Harris Corner Detector는 회전에 대한 불변성을 가진다. 즉, 회전을 하더라도 Key point를 잘 검출해낸다.
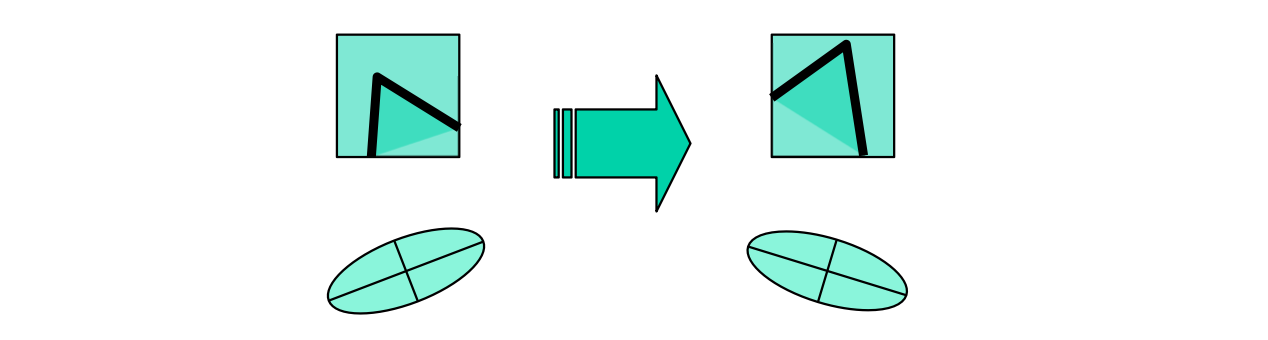
하지만 Scale에 대한 불변성은 없다. 아래 그림과 같이 Scale이 작을 때는 Corner라고 판단하던 것이 Image의 Scale이 커지면 이를 Edge라고 판단한다.
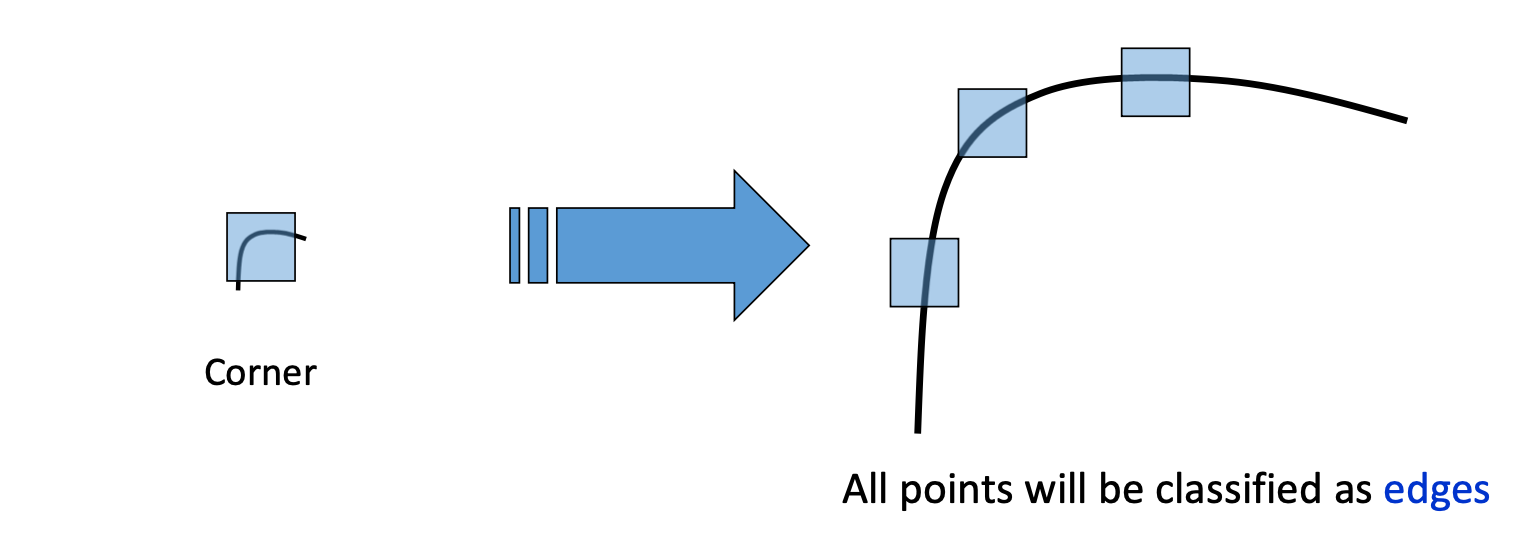
SIFT(Scale -Invariant Feature Transform)은 Scale 불변성을 가지고 있는 Keypoint detector와 각 keypoint를 matching하기 위한 descripter 방법을 제시한다.
Harris Corner Detector와 FAST 알고리즘은 Descripter가 존재하지 않는다.
SIFT의 구성요소는 다음과 같다.
- Multi-scale extrema detection
- Keypoint localization
- Orientation assignment
- Keypoint descripter
Multi-scale extrema detection
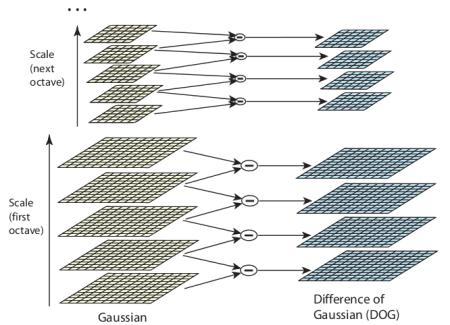
SIFT 알고리즘에서는 Scale에 대한 문제를 해결하기 위해 Image Pyramid를 생성한다. 각 Scale별로 Octave를 구성하고 각 Octave 내에 Gaussian Filter를 적용한다. 이후 각 결과물 간의 차이를 구혀여 DOG(Difference of Gaussian)을 구한다.
Gaussian을 빼주는 이유는 한 지점에서 Peak가 되는 지점만 살아남고 평균이 되는 부분을 사라지기 때문이다.
이후에 Extrema Detection, 쉽게 설명하자면 변화량을 통해서 Keypoint의 후보군을 찾을 수 있다.
keypoint localization
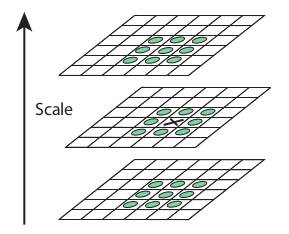
Dog Space에서 근접한 26개 값과 비교하여 최소 혹은 최댓값을 가지는 지점을 찾아내는 과정이다.
Orientation assignment
이후에 descirptor가 회전 불변성을 가지도록 keypoint의 방향을 구하는 것이다. 이는 HOG 방식과 유사하다. 먼저 주변 Pixel들에 대한 Gradient를 계산하고 Histogram으로 쌓아서 Descriptor로 사용한다. 검출된 Keypoint 위치 근처 Pixel들에 대하여 local gradient를 구하는 식은 다음과 같다.
이렇게 계산된 Gradient를 Histogram으로 만들어 가장 Dominanat한 방향을 찾고 이를 해당 Keypoint의 Orientation으로 설정한다.
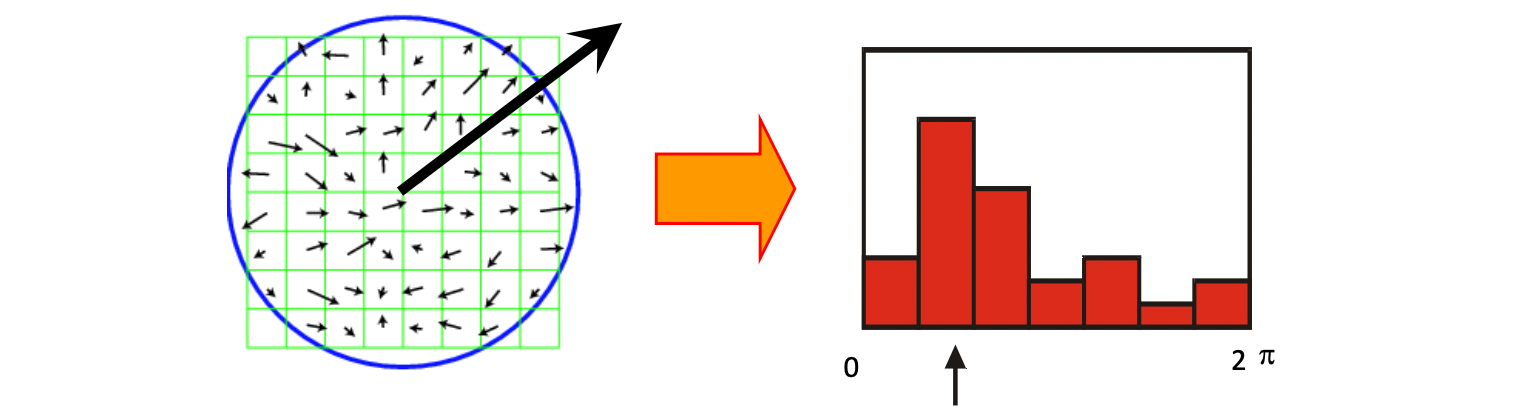
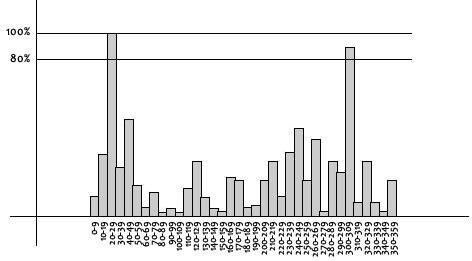
matching의 안정성을 위하여 80%에 해당하는 방향에 대한 keypoint도 생성한다.
Keypoint Descriptor
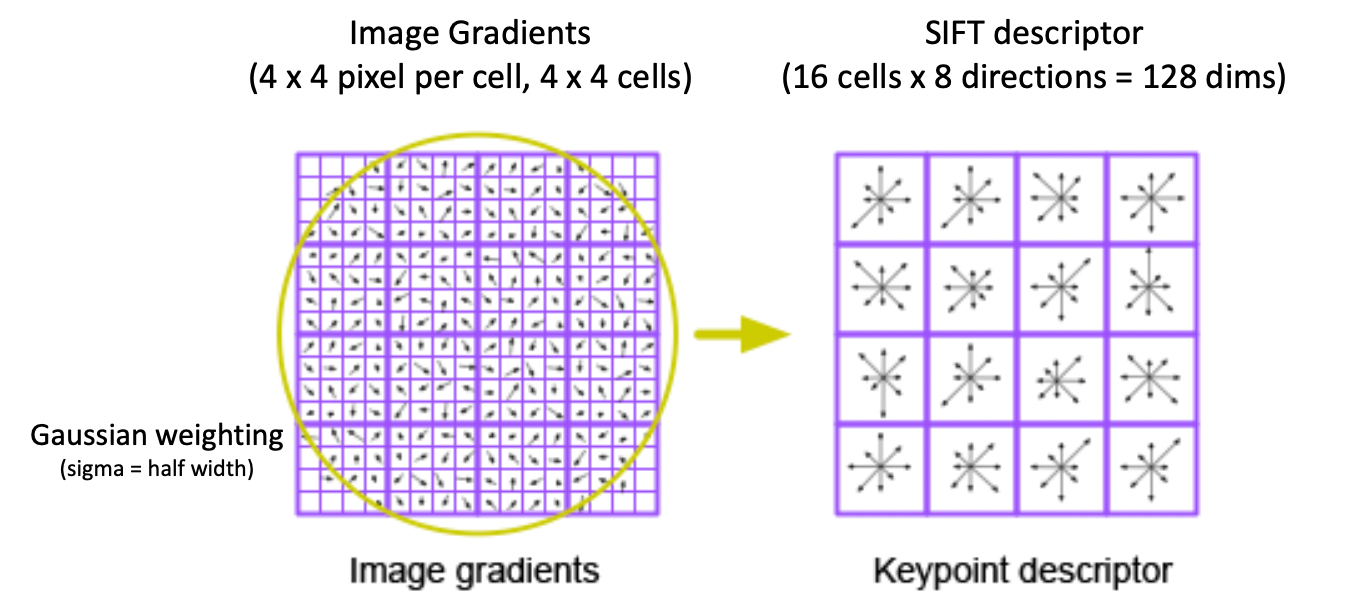
Keypoint Descripter는 각 Keypoint를 구별하는 특징 벡터를 만들어낸다. 우선 주변 16 x 16 Pixel을 4 x 4 cell로 나누고, 각 cell에서 8방향에 대한 Gradient Histogramd을 작성한다. 해당 Histogram을 Vector화 한 것이 Keypoint의 특징 Vector가 된다.
Keypoint에 근접한 Pixel에 대해서 가중치를 더주기 위해서 Gaussian Weighting을 수행하고, 왼쪽 그림과 같이 회전불변성을 위하여 앞에서 구한 Keypoint의 Orientation을 빼준다.
이러한 방식으로 만든 SIFT 알고리즘은 검출된 Keypoint에 대해서 Descriptor Vector들을 비교하고 가장 가까운 Keypoint끼리 매칭하게 된다. 아주 짧게 쓰고 싶었지만, 어쩌다 보니 글이 너무 길어진 거 같다.(매번 분량 조절을 실패하는 거 같다....) 다음 포스트에서는 Camera Parameter와 Stereo Matching과 관련한 주제에 관련해서 써보고자 한다. 해당 내용도 길어질 거 같긴 하지만, 그래도 최대한 요약해보도록 노력하겠다.
