
데이터베이스
분산 데이터베이스
여러 Physical node에 데이터를 분산시켜 저장하는 시스템
장점
- 장애 대응
- 고성능 저비용 → 비싼 1개의 머신보다 저렴한 n개의 머신이 더 싸고 효율적이다.
단점
- 데이터 분산은 어떻게 시킬것인가?
- 병렬처리에 따른 데이터 정합성은 어떻게 해결할 것인가? → 트랜잭션 관리, locking 관리
Replication
- 전체 테이블의 복사본을 분산 노드에 저장
- 장애 대응에 유연해지고 Query 실행효율이 좋아진다. → 하나의 Node가 죽어도 다른 node에 복사본이 있으므로 장애 대응에 효율적 → range가 넓은 쿼리나 cpu 사용량이 많은 쿼리를 분산해서 처리할 수 있으므로 실행효율 향상
- 동기 vs 비동기
Fragmentation
- 전체 테이블을 분할해 저장 → Horizontal / Vertical
Partitioning 전략
Hash partitioning
특정 컬럼의 값을 Hashing 함수를 통해 나오는 location id로 row를 분산처리
→ 로드 밸런싱을 위해 똑같이 row를 분산하고자 할 때 사용한다. 단 컬럼의 값이 중복이 많은 경우 효율이 떨어질 수 있으므로 unique한 슈퍼키를 기반으로 hashing을 하는 것이 좋다.
Range partitioning
특정 컬럼의 값 또는 값의 범위에 따라 파티션을 결정한다.
Round-robin partitioning
row의 순서에 따라 순서대로 분산노드를 결정한다.
병렬 처리
pipelining
여러 operation이 중첩되어 실행되는 기술
→ A 테이블 select 쿼리에 B 테이블 join 연산이 들어있다면, SELECT과 JOIN을 동시에 실행하면서 결과를 도출
Concurrent execution
각 node에 쿼리 실행범위를 분산시킨 뒤 결과를 병합해 결과를 도출
→ SELECT x from A일 경우,
- x < 10
- 10 < x < 100
- x > 100
이런 식으로 스캔할 범위를 분할한 뒤 각 node에 할당해 연산을 실행
Distributed Join
분산 환경에서 조인을 하려면?
→ A, B 테이블이 있다면, 둘 중 하나의 테이블 전체를 특정 node로 옮겨 local node에서 조인하면 된다.
→ 그런데 데이터를 full scan하는 비용, 옮기는 비용이 너무 비효율적이다.
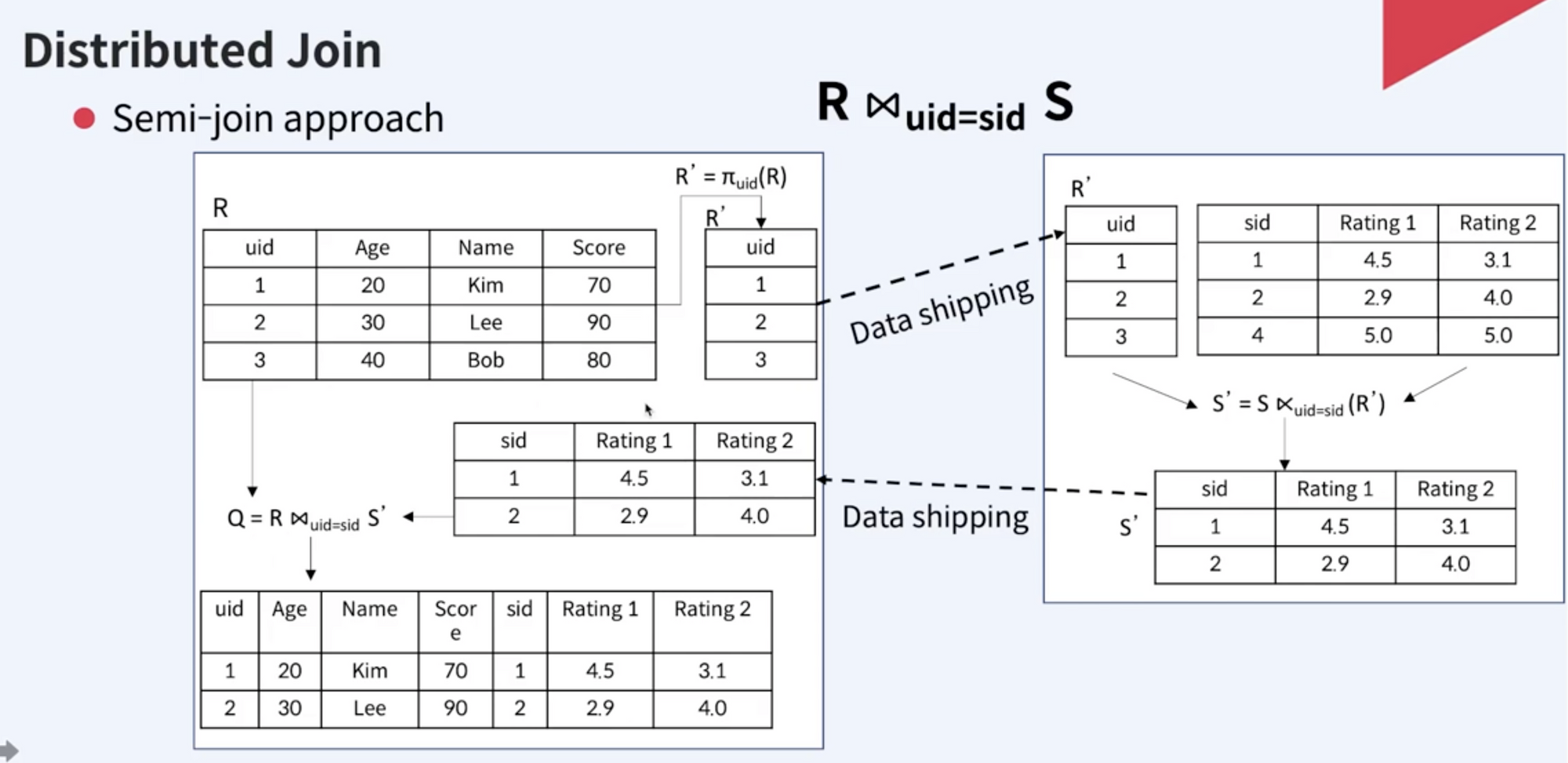
Semi-join
전체 테이블을 옮기지 않고, 둘 중에서 작은 테이블 & join에 필요한 컬럼만 node로 옮겨 연산하는 방식. 전체 테이블을 통으로 옮기지 않으므로 shipping에 드는 네트워크 비용을 아낄 수 있다.
Distributed Transaction
여러 node에서 동시에 트랜잭션이 들어오면 commit / rollback은 어떤 식으로 처리하는가
2 phase commit
prepare phase
→ 분산 환경을 관리하는 coorninator(주키퍼?)가 참여자들에게 precommit을 물어보고 그 결과를 취합한다. 각 node는 트랜잭션의 commit에 대해 찬성하거나 반대할 수 있다.
commit phase
→ 모든 node가 precommit이 끝나고 commit 준비가 되면 coordinator가 commit or rollback을 결정해 실제 commit을 하는 단계
![]()
RDB에서 commit을 하기 위해서 UNDO / REDO log를 작성하고 그에 맞게 commit을 하거나 rollback을 했던것과는 달리 commit에 상당히 복잡한 과정이 필요하다.
드디어 패캠챌린지 마지막날!!
https://bit.ly/3FVdhDa
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
