Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks (Park et al, 2024)
Abstract
State-space models (SSMs), such as Mamba (Gu & Dao, 2023), have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, their in-context learning (ICL) capabilities, a remarkable emergent property of modern language models that enables task execution without parameter optimization, remain underexplored compared to Transformers. In this study, we evaluate the ICL performance of SSMs, focusing on Mamba, against Transformer models across various tasks. Our results show taht SSMs perform comparably to Transformers in standard regression ICL tasks, while outperforming them in tasks like sparse parity learning. However, SSMs fall short in tasks involving non-standard retrieval functionality. To address these limitations, we introduce a hybrid model, MambaFormer, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently. Our findings sugest that hybrid architectures offer promising avenues for enhancing ICL in language models.
1. Introduction
In-context learning (ICL)
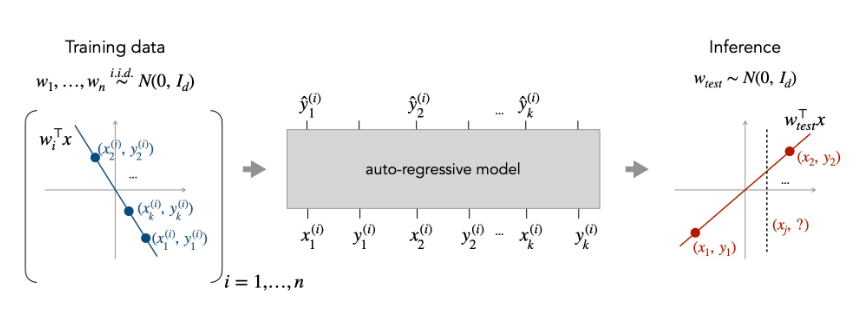
- Figure from "What Can Transformers Learn In-Context? A Case Study of Simple Function Classes (Garg et al, 2022)"
Transformer language models -> currently the only large models that is capable of ICL in practice.
Can attention-free models perform ICL?
ICL study
- ICL capabilities usually emerge(?) at scales beyond 3 billion parameters
- Testing the hypothesis usually requires 7B or more.
Small-scale ICL capabilities
- specifically training a model to perform in-context learning, following Garg et al (2022)
Mamba vs Transformer in ICL
- most of SSMs matches the performace of Transformers across multiple tasks
- Mamba shows limitations in learning decision trees and retrieval tasks
- Mamba outperforms Transformers in other complex tasks like sparse parity
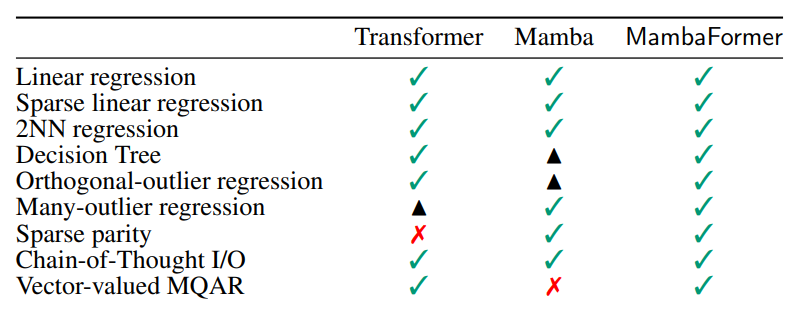
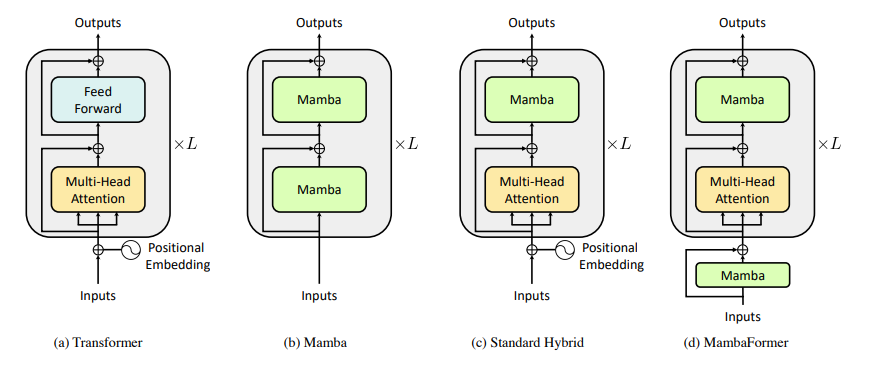
MambaFormer
- Interleaving SSM blocks with MHA blocks
- Leverage the strengths of both Mamba and Transformers (good at both sparse parity and retrieval)
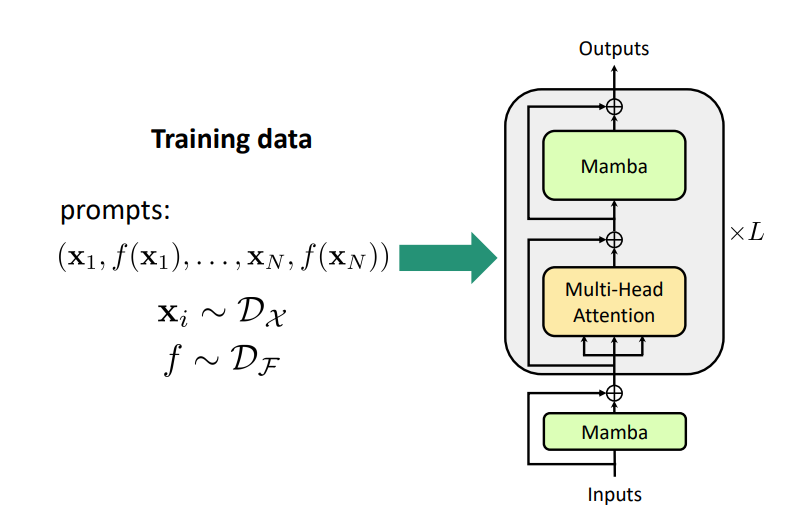
2. Related Works
ICL in Transformers
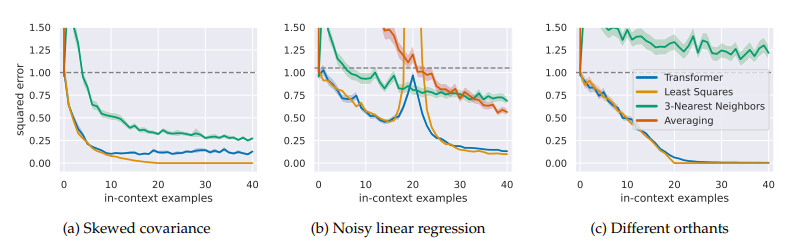
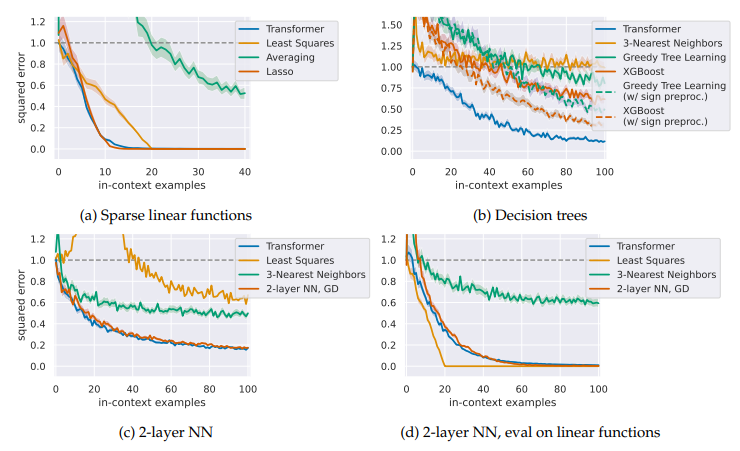
- Figures from "What Can Transformers Learn In-Context? A Case Study of Simple Function Classes (Garg et al, 2022)"
Sub-quadratic architectures
S4
- family of sequence models with discretized state-space model
Mamba
- selection mechanism in , making them dependent on
3. Experimental Setup
- Trained each model from scratch

3.1 Model Training in In-context Learning
- Train models to learn specific fuction classes in-context
- Training Step
- Select a function from distribution
- Sample a seq of random inputs i.i.d from
(N: number of in-context example, d is dim of - Prompt from 1 & 2
- Train model
With
, For , append d-1 zeros to .
Model architectures
- Mamba (state-of-the-art SSM)
- S4 (linear time-invariant counterpart to Mamba)
- S4-Mamba (Mamba's S6 replaced with S4)
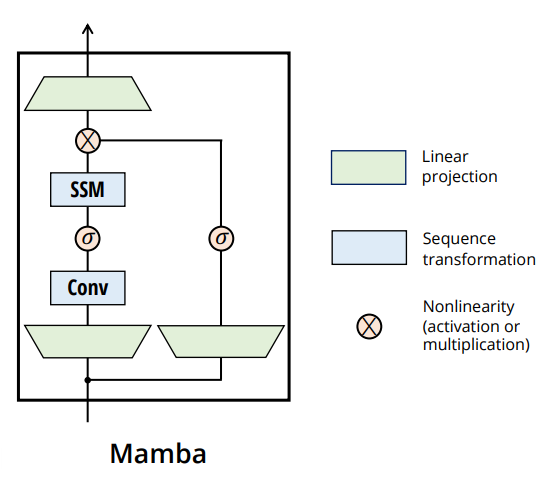
- Figure from Mamba (Gu & Dao, 2023)
Model Training & Evaluation
- 500,000 iterations of training
- 1,280 prompts sample for evaluation, sampled from consistent with training.
3.2 ICL tasks
3.2.1 Learning regression
In-context examples : sampled from the Gaussian distribution
Loss: squared error loss
-
Linear regression: , sampled from .
-
Sparse linear regression: Identical to linear regression, except only coordinates of are randomly used (rest set to 0)
-
Two-layer neural network: , is ReLU.
-
Decision Tree: full binary tree with a fixed depth and input
3.2.2 Learning with outliers
Each pair of is replaced with "dummy" vectors with a fixed probability
The loss is not computed for the replaced outliers during training
- Orthogonal-outlier regression
- Many-outlier regression: x and f are randomly replaced with a and one-hot vector with 90% probability
3.2.3 Learning discrete functions
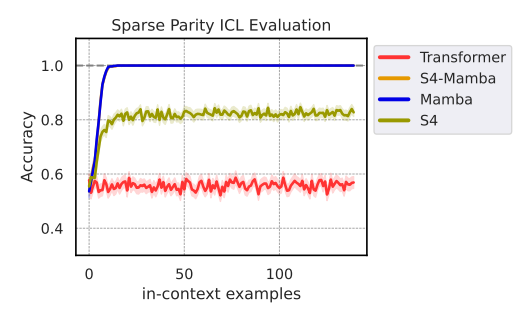
- Sparse parity: sampled uniformly at random from , , uses cross-entropy loss
3.2.4 learning Chain-of-Thought
- Chain-of-Thought-I/O: , Interleaves the intermediate hidden feature to create input sequence
3.2.5 Learning Retrieval
- Vector-valued multi-query associative recall(MQAR)
Model's associative recall ability is highly related to ICL abilitiesModel is given key-value pairs of vectors
Query: , each sample is from key set.
Model must output for each .
4. Experiment results
4.1 Mamba can in-context learn!
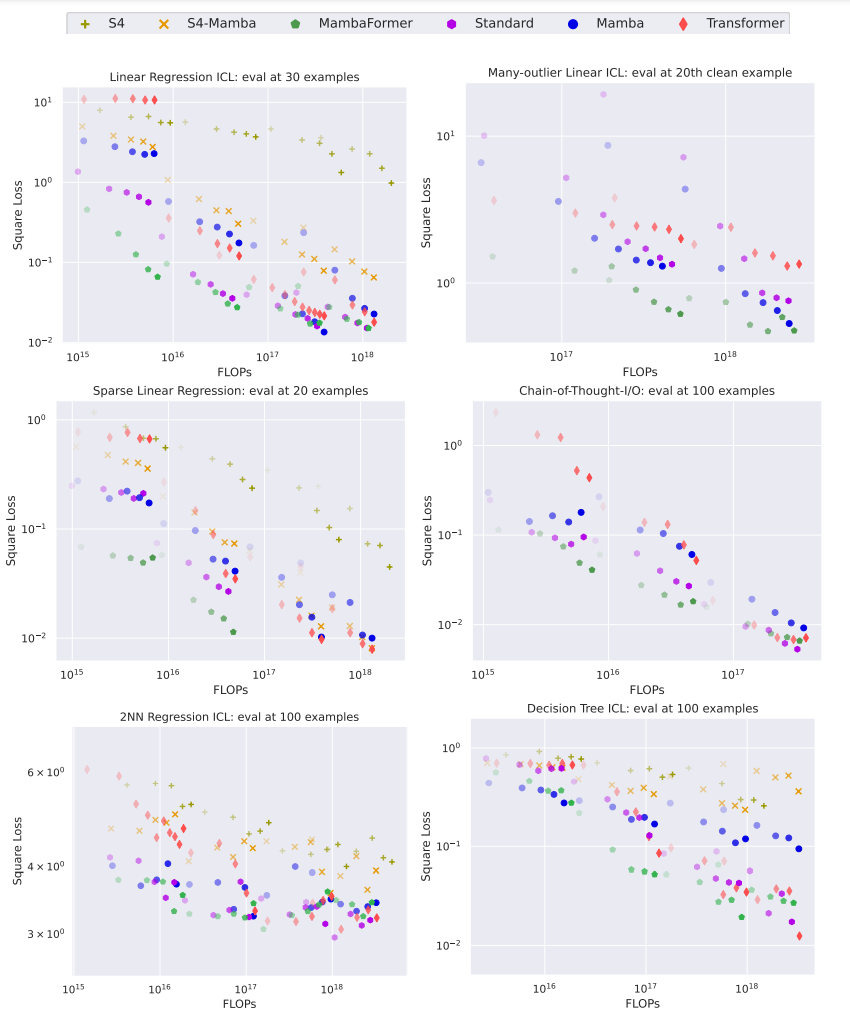
Performance gaps in more complex ICL tasks
- Concerning Decision tree, sparse parity, Chain-of-Thought
Transformers > Mamba
- Decision tree, MQAR
Mamba > Transformers
- Sparse parity
Filtering Outlier in regression
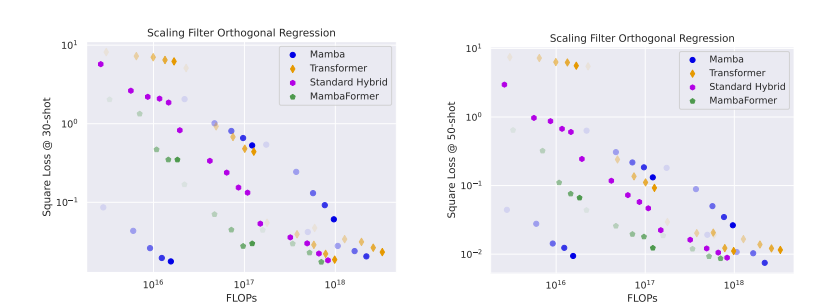
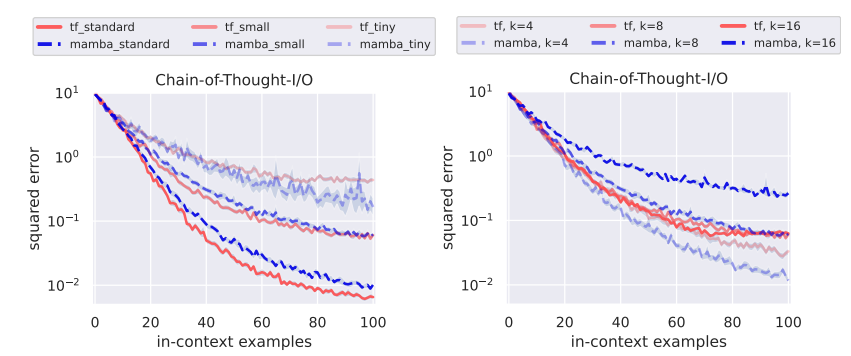
Chain of Thought
- Mamba models excel over Transformer at smaller sizes
MQAR
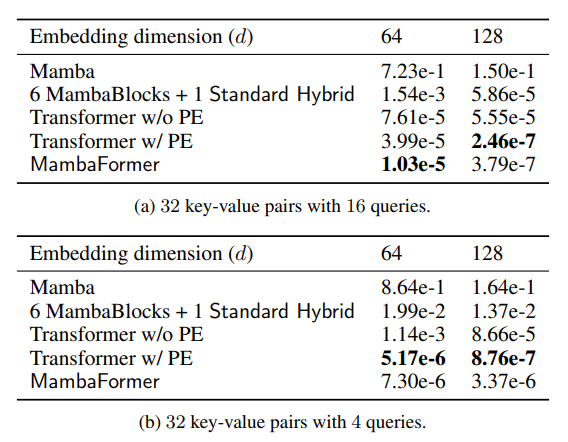
5. The Advantages of Hybrid Architectures for In-context Learning
5.1 Simultaneously learning parities and retrieval
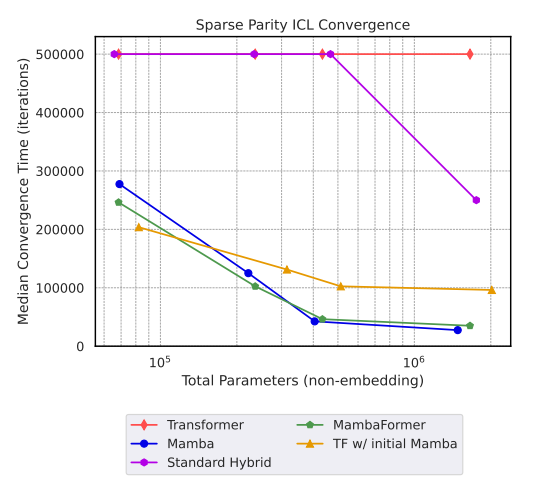
6. Discussion
- SSMs are capable in-context learners
- Neither SSMs nor Transformers are great at all tasks.
- Hybrid architecture MambaFormer achieves best-of-both-worlds performace
Future research directions
- How performance on artificial ICL tasks correlates with general language modeling capabilities, such as perplexity on standard NLP benchmarks.
- The potential for developing more effective architectures by integrating elements from transformers, SSMs, and gating mechanisms.
- Identifying architectural features that contribute to effective
in-context learning - Assessing the impact of MambaFormer and other innovative architectures on language modeling performance.

For those exploring international study opportunities, understanding how to approach new learning methods is key, just like the mamba study highlights adaptive learning strategies. https://studyvista.pk/ provides personalized guidance for students aiming for a student visa for Germany, helping them navigate university applications, scholarships, and interview prep to succeed confidently abroad. This ensures learners not only adapt academically but also transition smoothly into global education environments.