Are Emergent Abilities of Large Language Models a Mirage?
- 2023 NeurIPS Outstanding Paper Award
Abstract
Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are not present in larger-scale models.
What makes emergent abilities intriguing is two-fold: their sharpness, transitioning seemingly instantaneously from not present to present, and their unpredictability, appearing at seemingly unforeseeable model scales.
Here, we present an alternative explanation for emergent abilities: that for a particular task and model family, when analyzing fixed model outputs, emergent abilities appear due the researcher's choice of metric rather that due to fundamental changes in model behavior with scale.
Specifically, nonlinear or discontinuous metrics produce smooth, continuous, predictable changes in model performance.
We present our alternative explanation in a simple mathematical model, then test it in three complementary ways: we (1) make, test and confirm three predictions on the effect of metric choice using the InstructGPT/GPT-3 family on tasks with claimed emergent abilities, (2) make, test and confirm two predictions about metric choices in a meta-analysis of emergent abilities on BIG-Bench; and (3) show how to choose metrics to produce never-before-seen seemingly emergent abilities in multiple vision tasks across diverse deep networks.
Via all three analyses, we provide evidence that alleged emergent abilities evaporate with different metrics or with better statistics, and may not be a fundamental property of scaling AI models.
1. Introduction
Emergent abilities of large language models
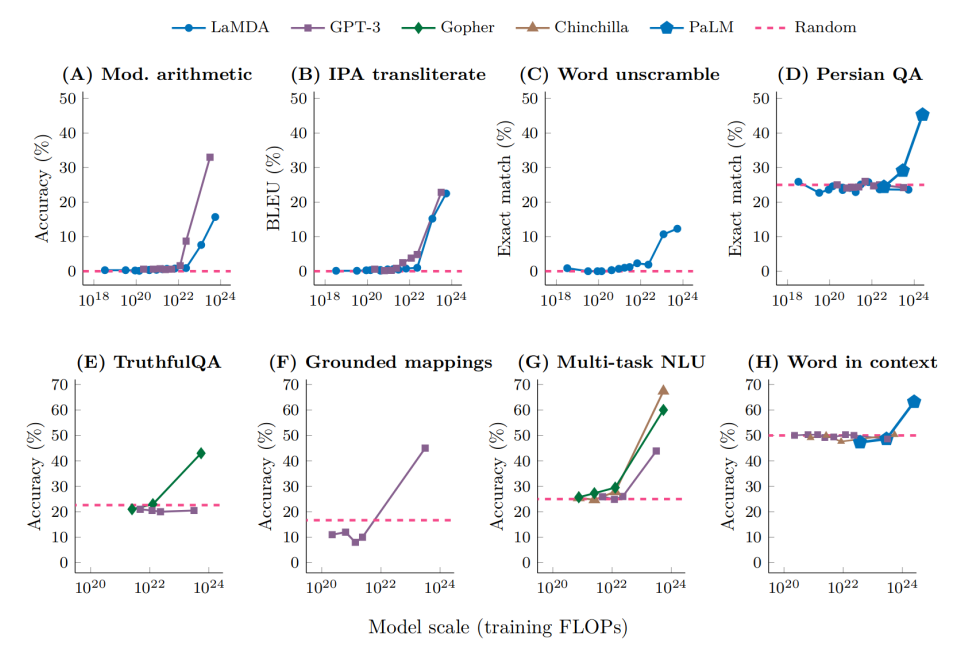
- recently defined as "abilities that are not present in smaller-scale models but are present in large-scale models; thuse they cannot be predicted by simply extraploating the performance improvements on smaller-scale models" (Wei et al, 2022)
- First discovered in the GPT-3 family
Two defining properties of emergent abilities in LLMs
- Sharpness, transitioning seemingly instantaneously from not present to present
- Unpredictability, transitioning at seemingly unforeseeable model scales
Main point of the paper
- Questioning the claim that LLMs possess emergent abilities(sharp and unpredictable changes in model outputs as a function of model scale on specific tasks)
Observation
- emergent abilities seem to appear only under metrics that nonlinearly or discontinuously scale any model's per-token error rate.
92% of emergent abilities on BIG-Bench tasks appear under either of two metrics

Alternative explanation of emergent abilities
Emergent abilities might be induced by the researcher's choice of measurement.
Emergent abilities are a mirage
- Caused by the researcher choosing a metric that nonlinearly or discontinuously deforms per-token error rates
- Caused by possessing too few test data to accurately estimate the performance of smaller models, making smaller models to appear wholly unable to perform the task.
Structure of paper
present a simple mathematical model to quantitatively reproduce the evidence
Test the alternative explanation in three complementary ways
(1) Make, test and confirm three predictions using the GPT model family
(2) Meta-analyze published benchmarks to reveal that emergent abilities only appear for specific metrics, and that changing the metric causes the emergence phenomenon to evaporate
(3) Induce seemingly emergent abilities in multiple vision tasks
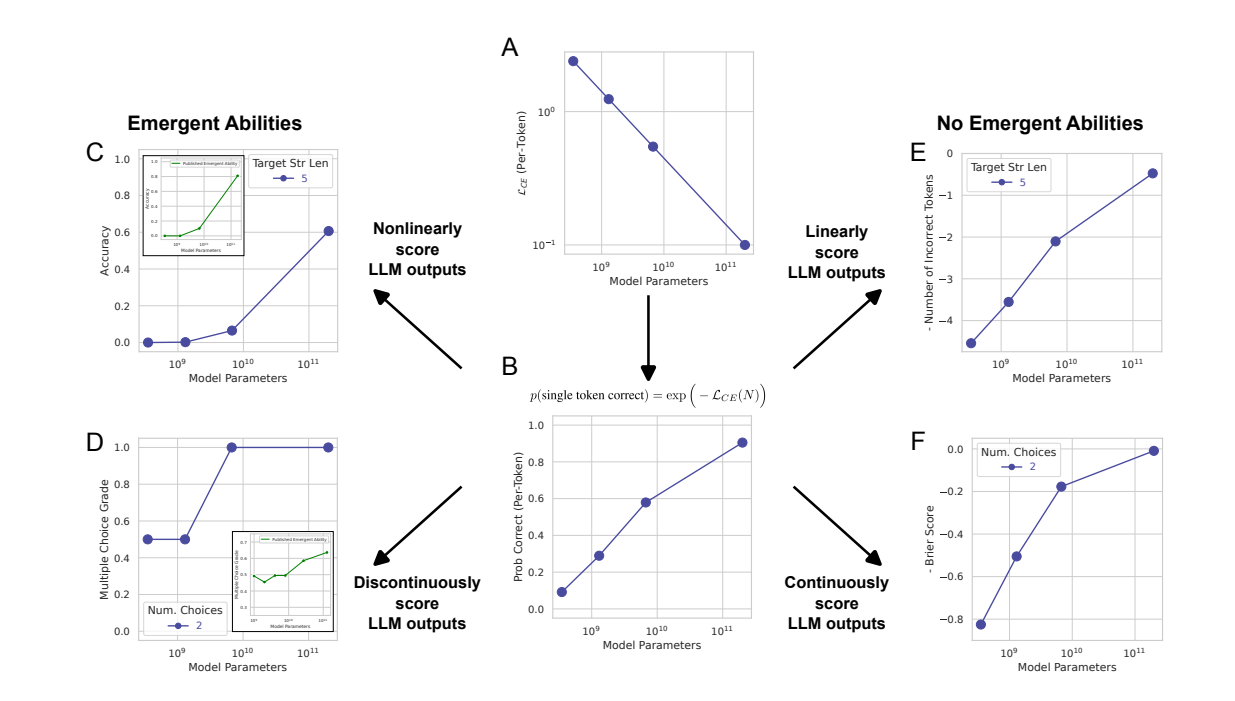
2. Alternative Explanation for Emergent Abilities
Neural scaling laws
- Test loss falls smoothly, continuously and predictably with the number of model parameters withtin a model family.
- each model's per-token cross entropy falls as a power law with the number of model parameters for constants
, for illustrative purposes.
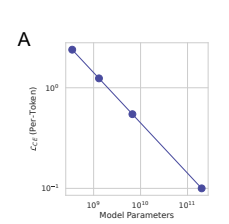
per-token probability of selecting the correct token
definitions
- := set of possible tokens
- := true but unknown probability distribution
- : -parameter model's predicted probability distribution
Per-token cross entropy
- p$ is unknown in practice, is observed token)
Per-token probability of selecting the correct token
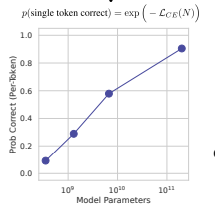
Metric that requires selecting L tokens correctly
L-digit integer addition
- output is scored 1 if all L output digits exactly math all target digits, 0 otherwise.
- probability of scoring 1 is
- nonlinearly scales performance => Sharp unpredictable emergent ability on linear-log plot
Case of metric switch - Token Edit Distance
- approximately linear metric
- Linear metric reveals smooth, continuous, predictable changes in model performance
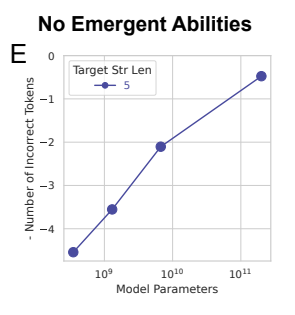
Conclusion of Section 2
Sharp and unpredictable changes with increasing scale can be fully explained by three interpretable factors
1. The researcher choosing a metric that nonlinearly or discontinuously scales the per-token error rate
2. Having insufficient resolution to estimate model performance in the smaller parameter regime
3. Insufficiently samping the larger parameter regime
3. Analyzing InstructGPT/GPT-3's Emergent Arithmetic Abilities
Three predictions
#1
Changing the metric from a nonlinear or discontinuous metric to a linear or continuous metric should reveal smooth, continuous, predictable performance improvement with model scale.
#2
For nonlinear metrics, increasing the resolution of measured model performance by increasing the test dataset size should reveal smooth, continuous, predictable model improvements commensurate with the predictable nonlinear effect of the chosen metric.
#3
Regardless of metric, increasing the target string length should predictably affect the
model’s performance as a function of the length-1 target performance: approximately geometrically for accuracy and approximately quasilinearly for token edit distance.
Prediction #1 & 3: Emergent Abilities Disappear With Different Metrics
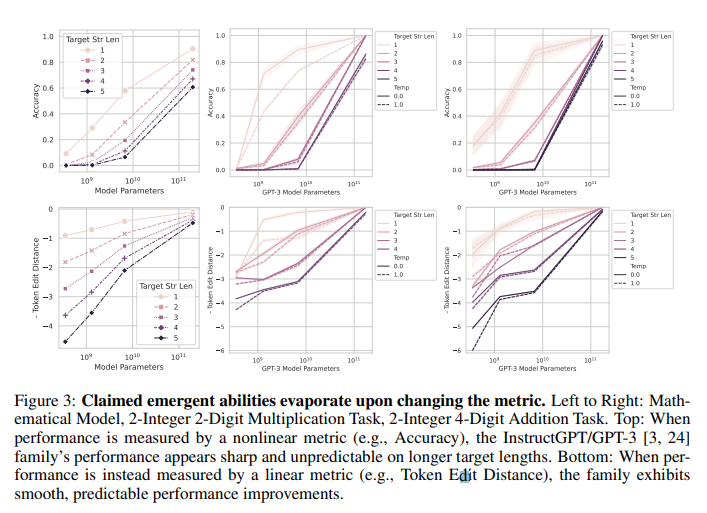
- Accuracy(Nonlinear) => Token Edit Distance (linear)
- Emergent Abilities disappear
=> Confirms prediction #1, and first half of #3
Prediction #2 & 3: Emergent Abilities Disappear With Better Statistics
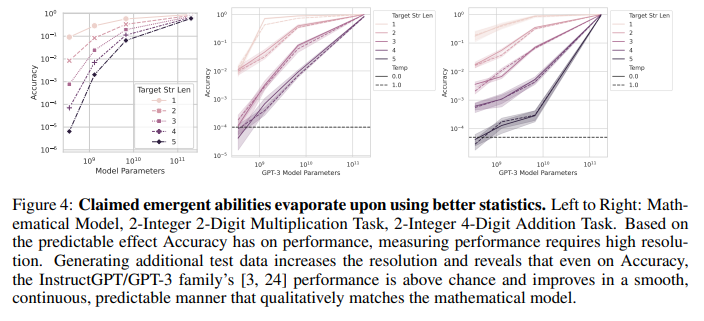
- Increase resolution (generating more test data) => all models achieve above-chance accuracy
=> confirms prediction #2 - As target string length increases, the accuracy falls approximately geometrically with the length of the target string
=> confirms second half of prediction #3
4. Meta-Analysis of Claimed Emergent Abilities
Two predictions
#1
At the “population level” of Task-Metric-Model Family triplets, emergent abilities should appear predominantly on specific metrics, not task-model family pairs, and specifically with
nonlinear and/or discontinuous metrics.
#2
On individual Task-Metric-Model Family triplets that display an emergent ability, changing the metric to a linear and/or continuous metric should remove the emergent ability.
Dataset
- BIG-Bench
Prediction #1: Emergent Abilities Should Appear with Metrics, not Task-Model Families
- If emergent abilities are real, we should expect task-model family to show emergence for all reasonable metrics.
- To test prediction, this paper introduced emergence score
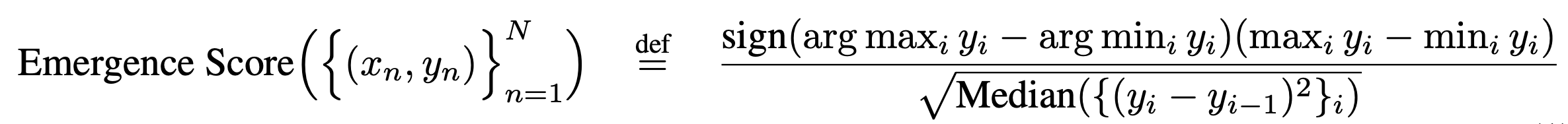
=> Most metrics used in BIG-Bench have zero task-model family pairs that exhibit emergent abilities
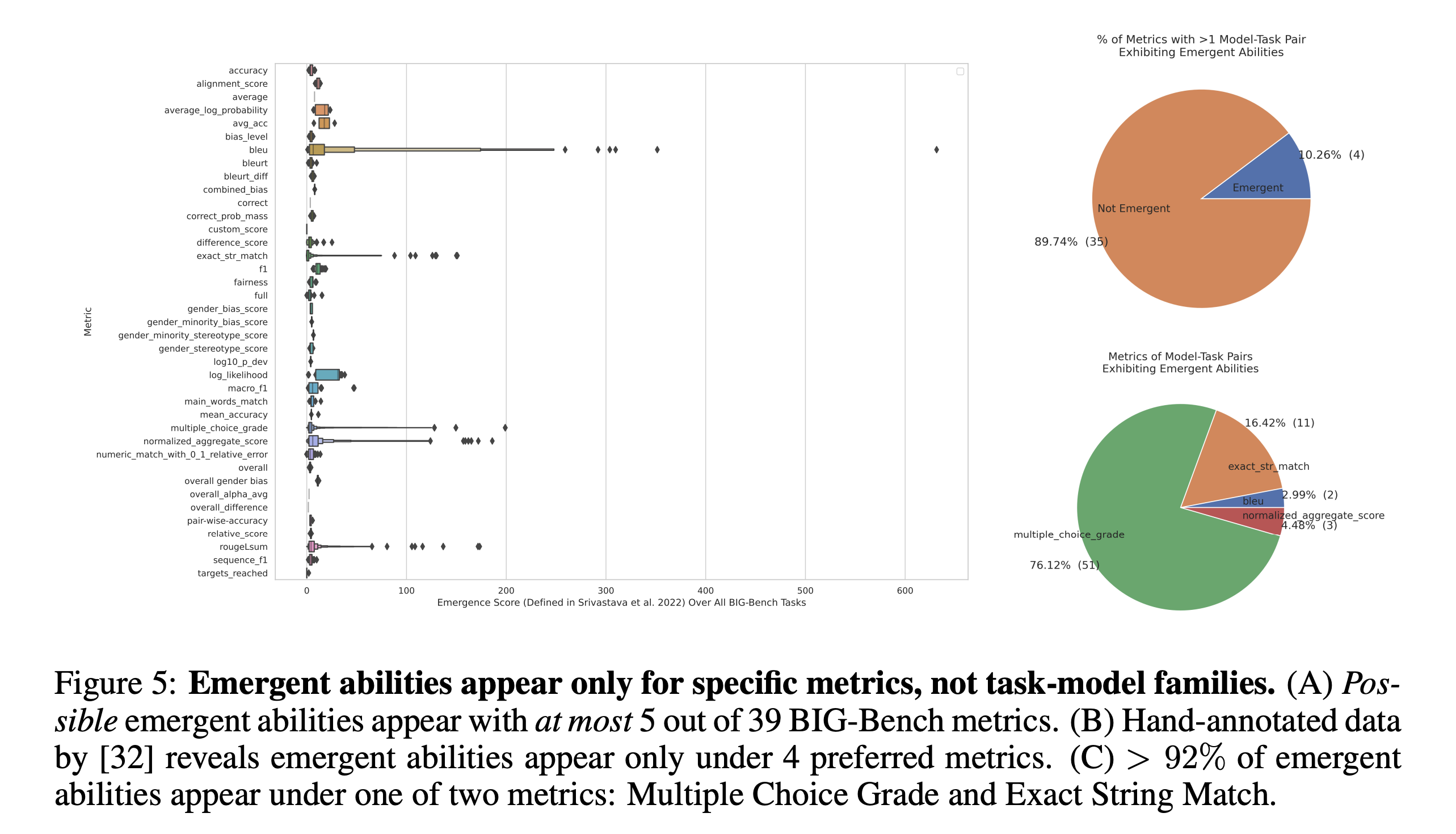
Prediction #2: Changing Metric Removes Emergent Abilities
5. Inducing Emergent Abilities in Networks on Vision Tasks
Vision? => No emergent ability yet found.
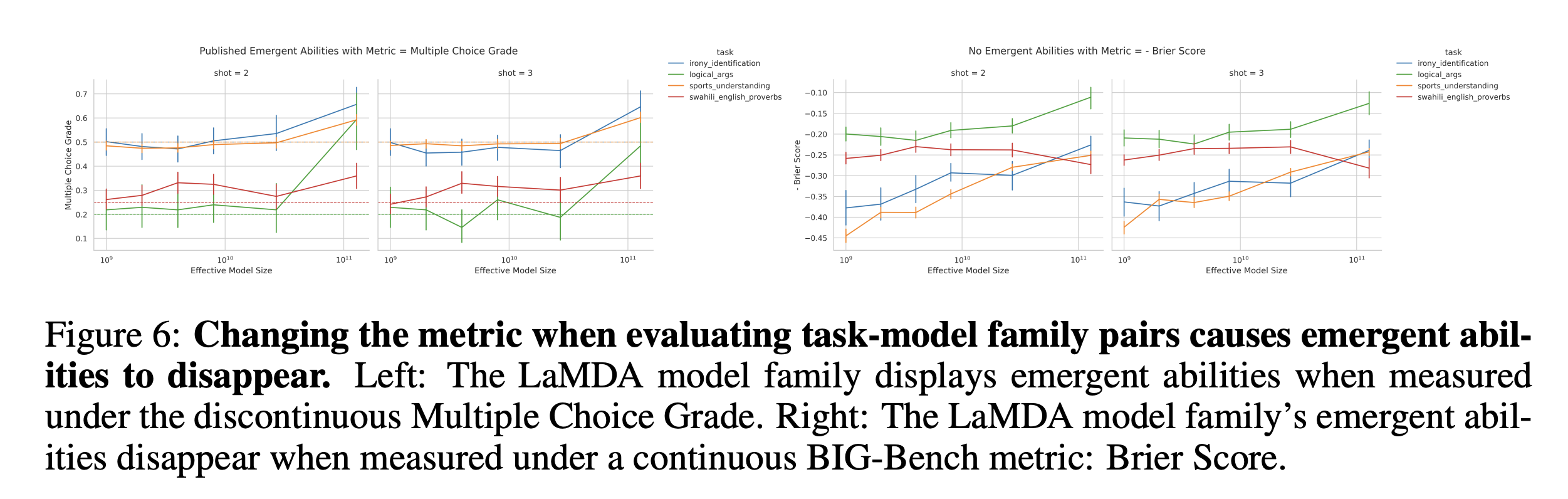
Emergent Reconstruction of CIFAR100 Natural Images by Nonlinear Autoencoders
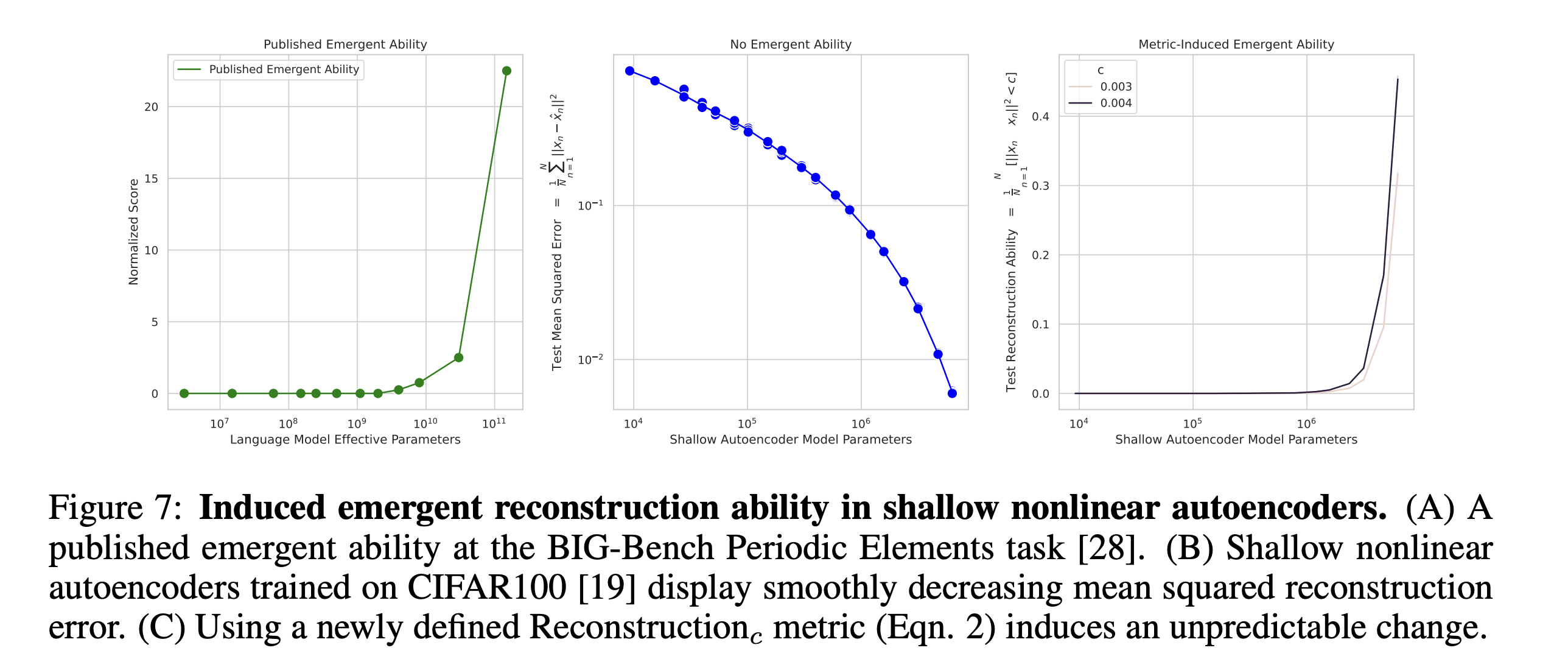
- Intentionally define a discontinuous metric that measures a network’s ability to reconstruct a dataset as the average number of test data with squared reconstruction error below threshold c:
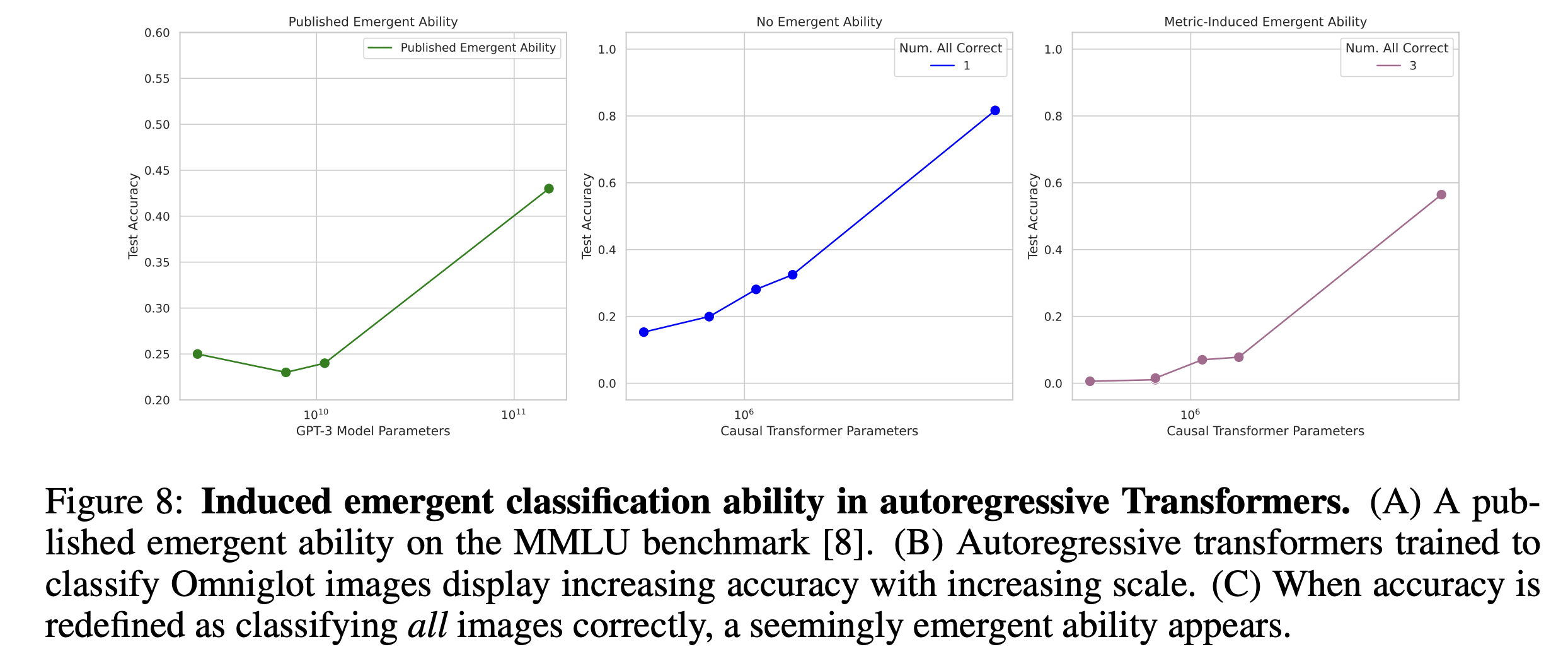
Emergent Classification of Omniglot Characters by Autoregressive Transformers
- Define a subset accuracy: 1 if all L images are classified correctly, 0 otherwise.
6. Related Works
Srivastava et al. observed that while accuracy at a particular task can empirically appear sharp and unpredictable, cross entropy does not; the authors then hypothesized that emergent abilities may
be partially attributed to the metric. This paper converts their discussion into precise predictions, then quantitatively tests the predictions to reveal that: metric choice is likely wholly responsible
for emergent abilities.
7. Discussion
1.
A task and a metric are distinct and meaningful choices
when constructing a benchmark.
2.
When choosing metric(s), one should consider the metric’s effect on the per-token error rate and adapt their measuring process accordingly, e.g., if one chooses accuracy, one should make sure to have sufficient data to accurately measure accuracy to avoid the risk of drawing invalid scientific conclusions.
3.
When making claims about capabilities of large models, including proper controls is critical.
4.
Fourthly, scientific progress can be hampered when models and their outputs are not made public for independent scientific investigation.
