Title
- MambaOut: Do We Really Need Mamba for Vision? (Yu & Wang, Arxiv 2024)
Abstract
- Mamba -> architecture with RNN-like token mixer of SSM
- Mamba adresses quadratic complexity of the attention -> applied to vision tasks
- Performance of Mamba for vision -> underwhelming when compared to convolutional and attention-based models
- This paper conceptuallly conclude that Mamba is ideally suited for tasks with long-sequence and autoregressive characteristics.
- Hypothesize that Mamba is not necessary for image classification
- Detection & segmentation -> no autoregressive, but adhere long-sequence characteristics -> worthwhile to explore Mamba's potential.
- MambaOut model to empirically verify the hypothesis
- MambaOut: Stacked Mamba blocks without SSM
- MambaOut model surpasses all visual Mamba models on ImageNet classification
- MambaOut cannot match the performance of sota visual Mamba models.
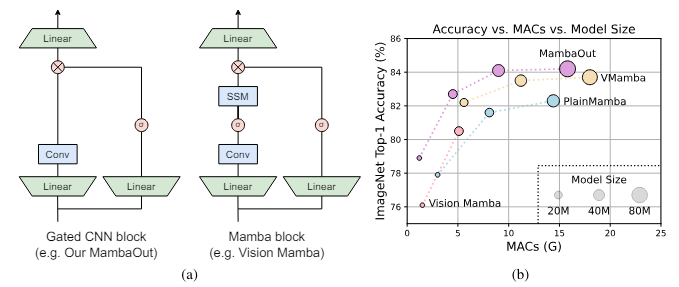
1 Introduction
- Transformer and linear complexity model
- Vision in Mamba
- Vision Mamba
- VMamba
- LocalMamba
- PlainMamba
- Underwhelming performace compared with sota convolutional and attention based models
Do we really need Mamba for Vision?
The paper's works
- Mamba is ideally suited for tasks with
- Long-sequence
- autoregressive
Two hypotheses
- SSM is not necessary for image classification, since this task conforms to neither the long-sequence or autoregressive characteristic
- SSM may be potentially beneficial for object detection & instance segmentation and semantic segmentation, since they follow the long-sequence characteristic, though they are not autoregressive.
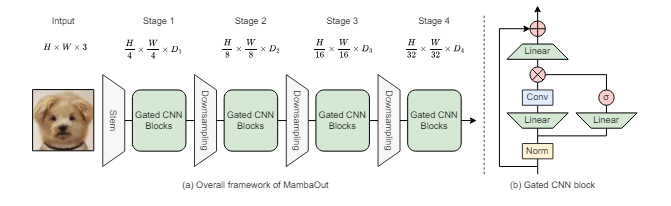
MambaOut
- Gated CNN blocks(Mamba without SSM)
- Performs better than Mamba in ImageClassification => verifying Hypothesis 1.
- Falls short of detection and segmentation => validating Hypothesis 2.
Contribution
- Analyzing the RNN-like mechanism of SSM and conceptually concluding that Mamba is suited for tasks with long-sequence and autoregressive characteristics
- Examined characteristics for visual tasks and hypothesize that SSM is unnecessary for image classification on ImageNet, yet potential of SSM for detection and segmentation tasks remains valuable.
- Developing MambaOut based on Gated CNN blocks without SSM. MambaOut may readily serve as a natural baseline for future research on visual Mamba models.
2 Related work
- Transformer and models to solve its quadratic scaling
- SSM and Mamba for visual tasks
- Vision Mamba - isotrophic vision models akin to ViT
- VMamba - hierarchical vision models similar to ResNet
- LocalMamba - enhance visual Mamba with local inductive biases
- PlainMamba - aims to enhance performance of isotropic Mamba models
3 Conceptual discussion
3.1 What tasks is Mamba suitable for?
-
Selective SSM (token mixer of Mamba)
-
Four input-dependant parameters
-
Transforms them to
-
Sequence to sequence transform of SSM
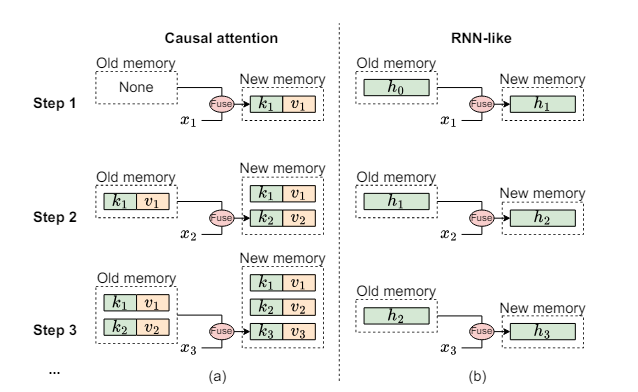
-
Causal attention: stores all keys and valeus as its memory
-
RNN-lie ssm: fixed, constant, lossy memory
-
Limitation of Mamba: can only access information from the previous and current timesteps
Token Mixing
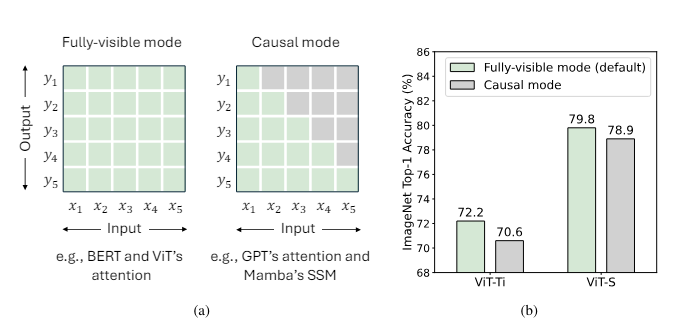
- Causal mode
- Fully-visible mode
- is total number of tokens
- suitable for understanding tasks, where all inputs can be accessed by the model at once
- Attention is in fully-visible mode by default + can easily trun into causal mode (causal masks)
- RNN-like models inherently operate in causal mode -> no fully-visible mode
- Can approximate fully-visible mode using bidirectional branches, but each branch is individually causal.
=> Mamba is well-suited for tasks that require causal token mixing
- Can approximate fully-visible mode using bidirectional branches, but each branch is individually causal.
3.2 Do visual recognition tasks have very long sequences?
-
Consider Transformer block with MLP ratio of 4
-
input:
-
FLOPs:
-
ratio of the quaratic term to the linear term
=> if , computational load of the quadratic term in surpasses linear term.
-
Metric for long sequence tasks
-
ViT-S: 384 channels =>
-
ViT-B: 786 channels =>
On tasks
- ImageNet: => with patch size . => does not qualify as a long-sequence task
- COCO & ADE20K (, )
=> number of tokens: 4K
=> Can be considered long-sequence
3.3 Do visual recognition tasks need causal token mixing mode?
- Visual recognition -> understanding task that model can see the entire image at once
- performance degration in ViT in causal mode
4 Experimental verification
4.1 Gated CNN and MambaOut
- Meta-architecture of Gated CNN and Mamba is identical
- Token mixers of Gated CNN and Mamba

4.2 Image classification on ImageNet
Setup
- Follows DeiT
Results
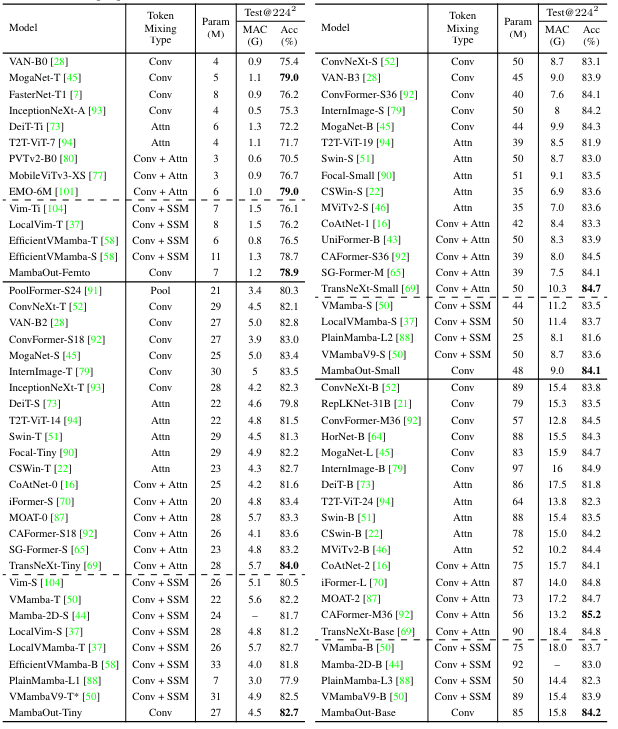
- MambaOut models consistently outperform visual Mamba models across all model sizes
- MambaOut-Small achieves top-1 accuracy 84.1% vs LocalVMamba-S 83.7% while requiring 79% of MACs.
- Visual Mamba models shows significant performance gap compared to sota convolution and attention models.
- CAFormer-M36 (conv + attn) outperforms all Mamba models by 1% in accuracy
4.3 Object detection & instance segmentation on COCO
Setup
- MambaOut as backbone within Mask R-CNN
Results
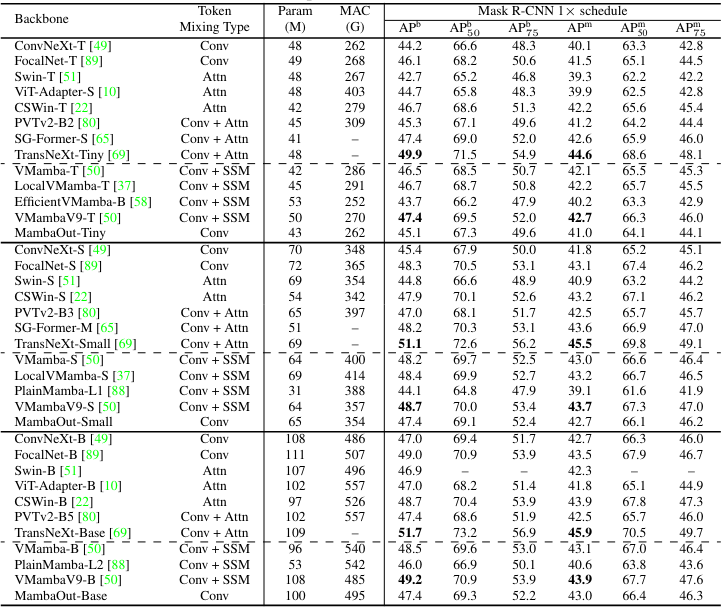
- MambaOut lags behind sota visual Mambas => Mamba in long-sequence visual tasks has benefits
- Still exhibits significant performance gap with sota conv-attn hybrid models, TransNeXt.
4.4 Semantic segmentation on ADE20K
Setup
- MambaOut as backbone for UperNet
Results
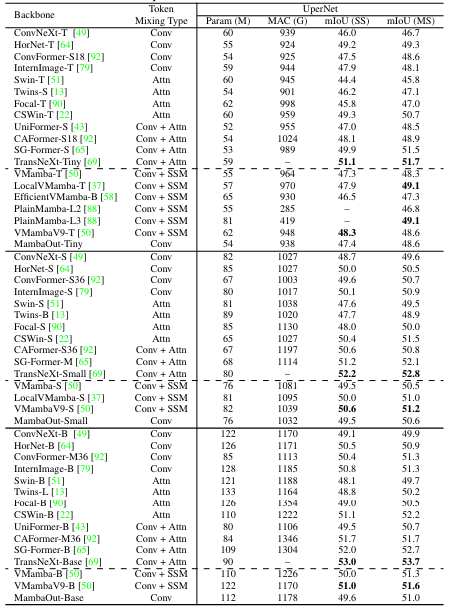
- trends like COCO
5 Conclusion
- Future works
- Further explore Mamba and RNN concepts
- Integratino of RNN and Transformers for LLM and LMMs.
Side Notes

(??)

Undergraduate student at SNU