paper_reviews
1.논문 리뷰: Paint Transformer
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction Stroke를 통해서 painting을 재현하는 방식의 논문이다. 특히, 데이터 셋 없이 Self-training pipeline 을 활용하여
2.TabNet & Tabular data: Deep Learning is not all you need

While working on a project in my lab, I saw that XGBoost and LightGBM outperforms any deep learning implementation. This led to the search of TabNet.
3.Denoising Vision Transformers
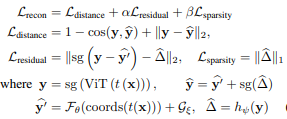
Denoising Vision Transformers(2024) Abstract Problem definition Grid-like artifacts in ViTs' feature maps hurts the performance Positional embedding
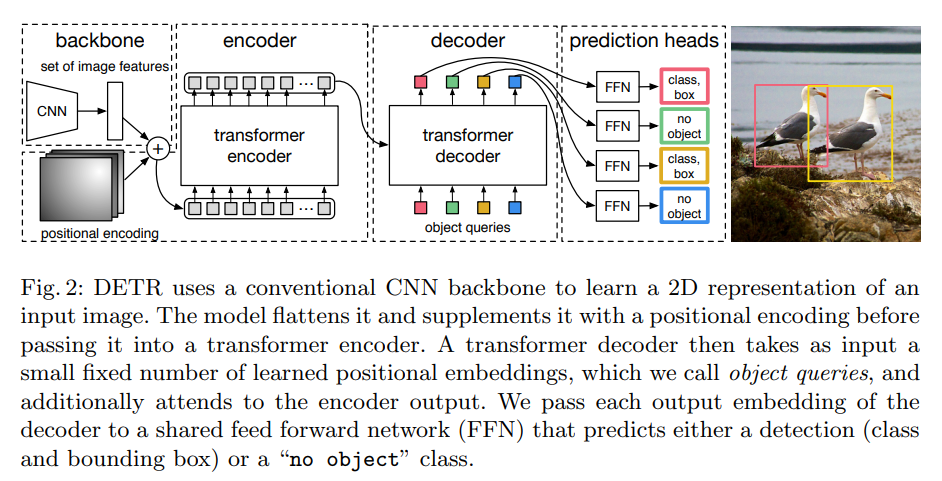
4.Paper Review: Transformers are Multi-State RNNs
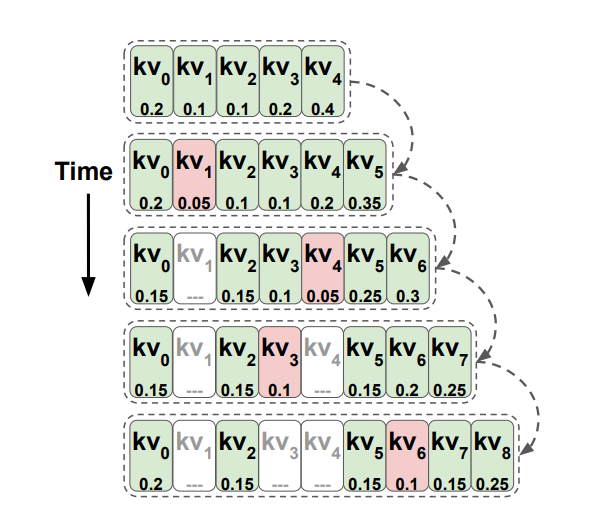
Transformers are Multi-State RNNs Abstract Decoder-only transformers can be conceptualized as infinite multi-state RNNs Multi-state RNNs: an RNN var
5.Vision Mamba vs VMamba vs S4ND
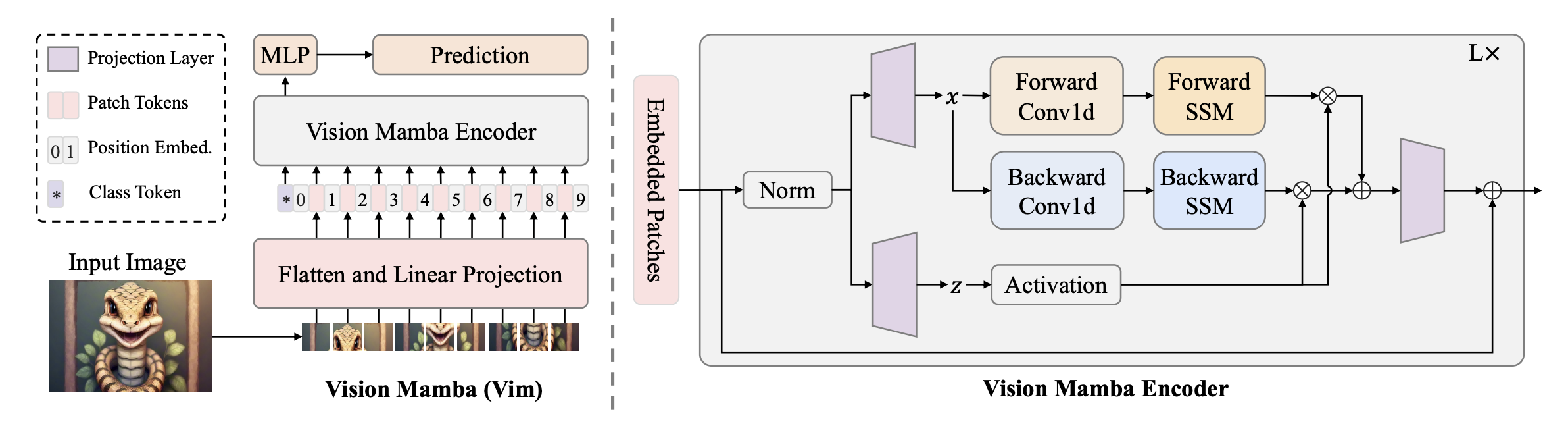
dd
6.Paper Review: Are Emergent Abilities of Large Language Models a Mirage?
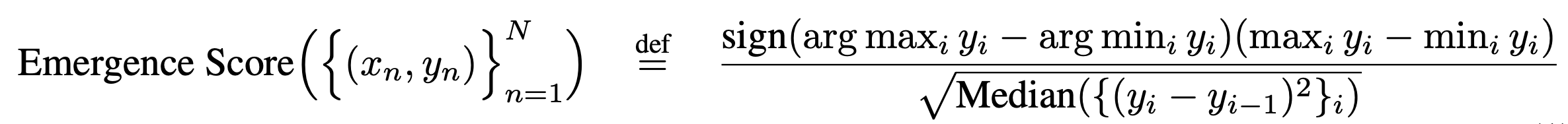
Are Emergent Abilities of Large Language Models a Mirage? 2023 NeurIPS Outstanding Paper Award Abstract Recent work claims that large language model
7.Grandmaster-Level Chess Without Search
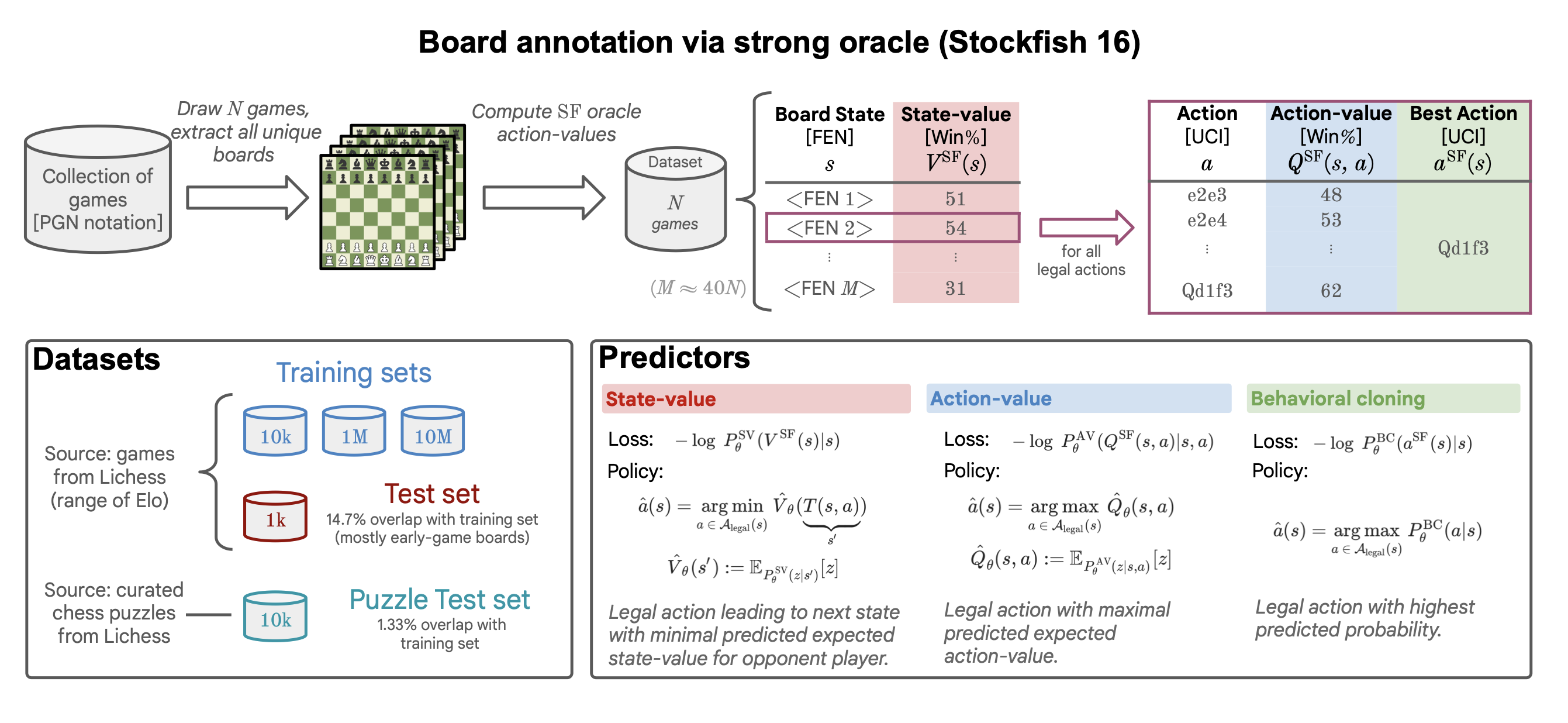
A paper by Google Deepmind.The recent breakthrough successes in machine learning are mainly attributed to scale: namely large- scale attention-based a
8.Vision Transformers Need Registers
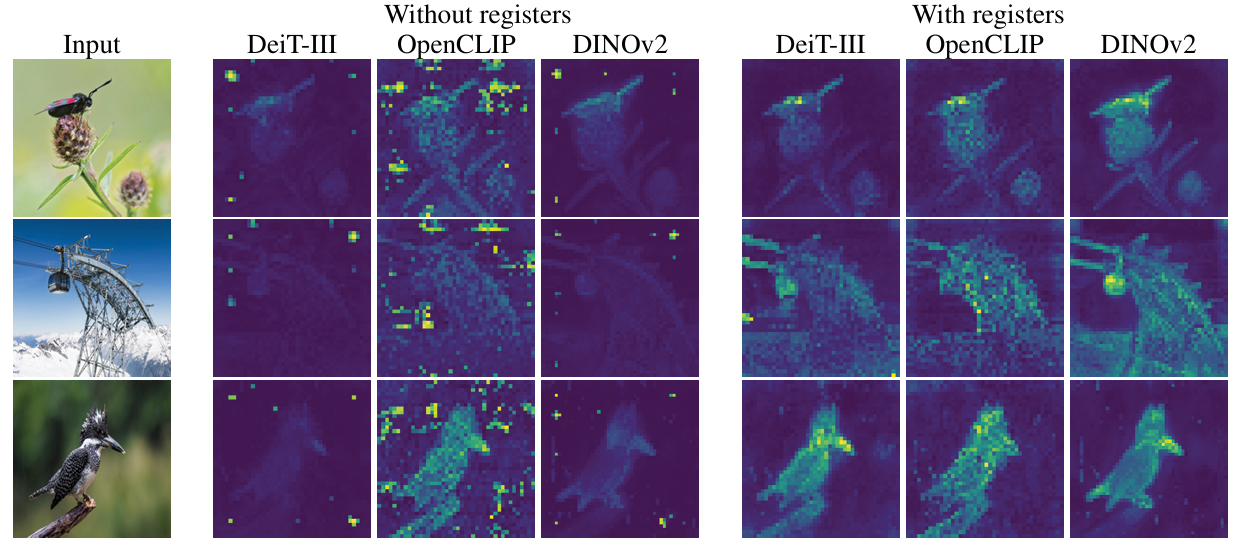
Vision Transformers Need Registers (ICLR 2024 Oral)Artifacts in feature maps of ViT(both supervised and self-supervised)The artifacts are high-norm to
9.UniMSE review
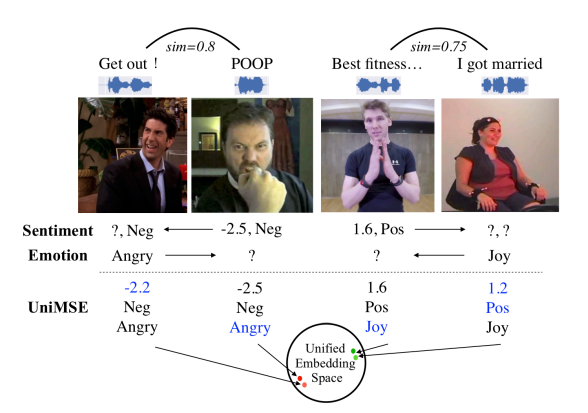
UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition (EMNLP 2022)Multimodal sentiment analysis (MSA)Emotion recognition in co
10.NeRF review

Title NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (ECCV 2020, Oral) Abstract SOTA for synthesizing novel views of complex
11.3D Gaussian Splatting

Title 3D Gaussian Splatting for Real-Time Radiance Field Rendering (SIGGRAPH 2023, Kerbl & Kopanas et al.) Abstract Radiance Field NN -> costly to tra
12.ViTAR review
Title: ViTAR: Vision Transformer with Any Resolution (Fan et al, 2024) Abstract ViT -> constrained scalability accross different image resolutions
13.xLSTM review
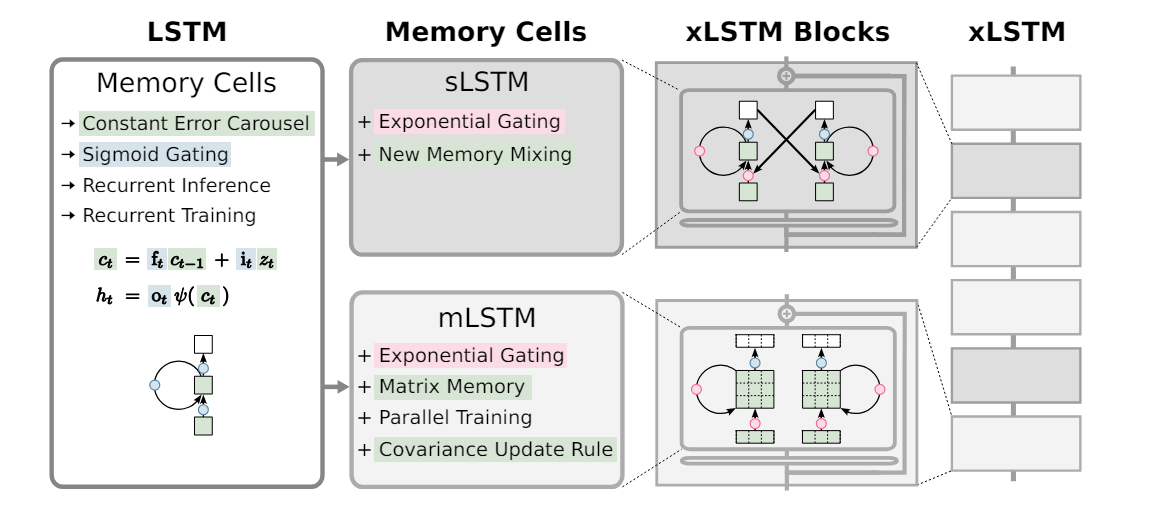
xLSTM: Extended Long Short-Term Memory (arxiv 2024)1990s -> Long Short-Term Memory with constant error carousel and gatingLSTMs -> Contributed to nume
14.MambaOut
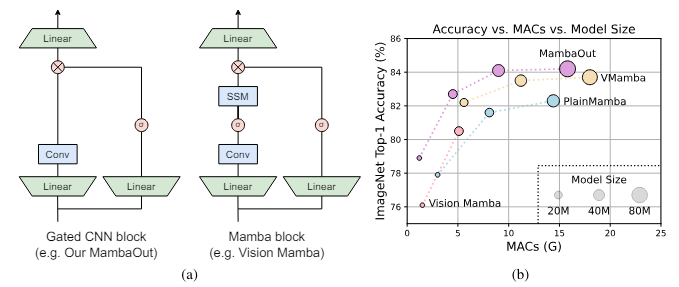
MambaOut: Do We Really Need Mamba for Vision? (Yu & Wang, Arxiv 2024)Mamba -> architecture with RNN-like token mixer of SSMMamba adresses quadratic co