Title:
ViTAR: Vision Transformer with Any Resolution (Fan et al, 2024)
Abstract
ViT -> constrained scalability accross different image resolutions
ViTAR
-
Element 1
- Dynamic resolution adjustment with single Transformer block
- highly efficient incremental token integration
-
Element 2
- fuzzy positional encoding
- consistent positional awareness across multiple resolutions
-
Results
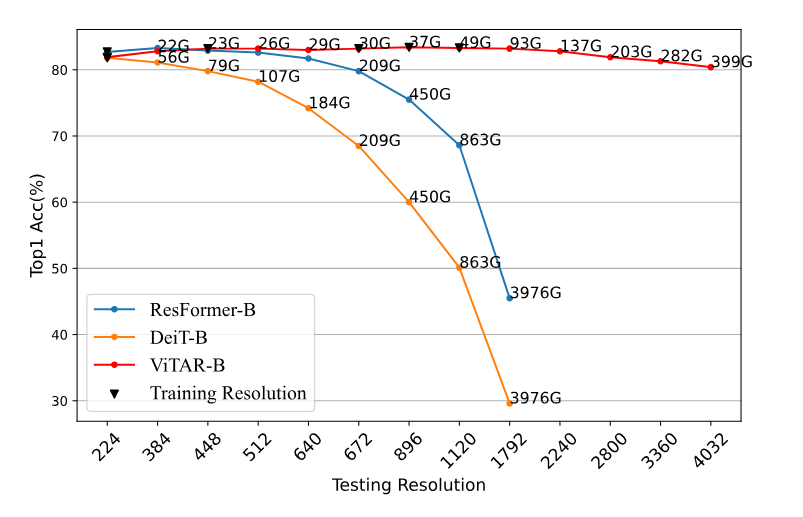
- 83.3% top-1 acc (1120x1120)
- 80.4% top-1 acc (4032x4032)
- compatible with self-supervised learning
1. Introduction
ViTs
- Segment images into non-overlapping patches, project each patch into tokens, and then apply MHSA to capture the dependencies among different tokens
Results
- Diverse visual tasks
- Image classification (Swin Transformer, Neighborhood attention transformer)
- Object detection (DETR, PVT)
- Vision-language learning (ALIGN, CLIP)
- Video recognition (Svformer)
Variable input resolutions
- Previous works -> no traning can cover all resolution
Direct interpolation
- Simple and widely used approach
- Directly interpolate the positional encodings before feeding them into the ViT
- Significant performance degradation
ResFormer
- Multiple resolution images during training
- Improvements on positional encodings -> flexible, convolution-based positional encoding
Challenges
- High performance on relatively narrow range of resolution
- Cannot integrate with self-supervised learning(Masked AutoEncoder) because of convolution-based positional encoding
Vision Transformer with Any Resolution (ViTAR)
- ViT which processes high-resolution images with low computational burden and exhibits strong resolution generalization capability
- Adaptive Token Merger (ATM) module
- Iteratively processes tokens that have undergone the patch embedding
- Scatters all tokens onto grids
- Tokens within a grid as a single unit -> merges tokens within each unit -> mapping all tokens onto a gride of fixed shape => grid tokens
- low computational complexity with high-resolution images
- Fuzzy Positional Encoding (FPE)
- introduces a positional perturbation
- Precise position perception -> fuzzy perception with random noise
- Prevents the model overfitting to position at specific resolutions
- Form of implicit data augmentation
2. Related Works
Vision Transformers
Multi-Resolution Inference
- Remains uncharted field
- NaViT -> employs original resolution images as input to ViT
- FlexiViT -> use patches of multiple sizes to train the model -> adapt to various patch size
- ResFormer -> multi-resolution training -> CNN based positional encoding
- Challenging to be used in self-supervised learning
- Significant computational overhead (based on original ViT)
Positional Encodings
- Crucial for ViT -> providing it with positional awareness and performance improvements
- Early ViTs -> sin-cos encoding -> limited resolution robustness
- CNN based PEs -> stronger resolution robustness
3. Methods
3.1. Overall Architecture
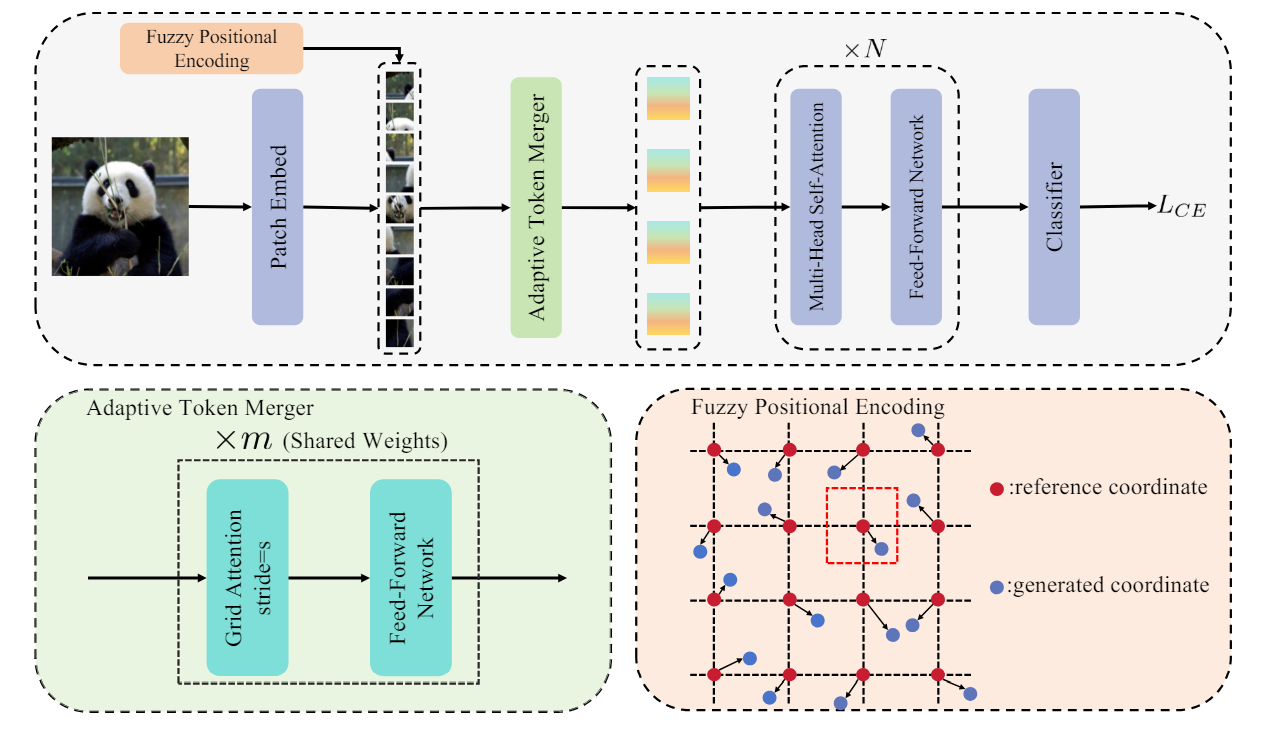
- ATM + FPE + ViT
3.2. Adaptive Token Merger (ATM)
-
Receives tokens that have been processed through patch embedding as its input
-
-> number of tokens ultimately aim to obtain
-
ATM partitions tokens with the shape of into a grid of size
-
Assume is divisible by , is divisible by
=> Number of tokens contained in each grid -> (each typically set to 1 or 2) -
Case -> ->
-
Case -> pad to , set ->
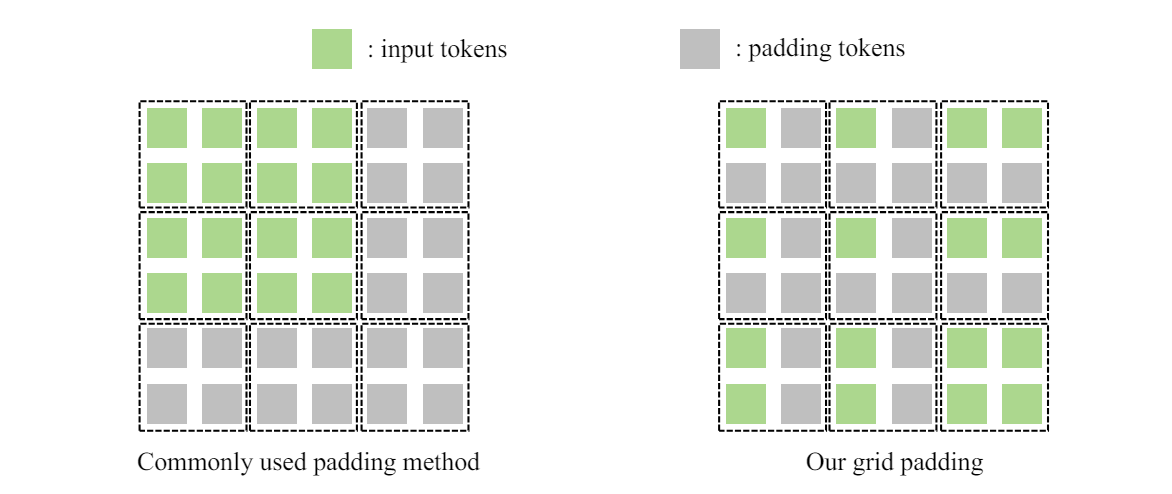
-
Case -> tokens on the edge of are no longer fused ->
-
Same with
-
Grid Attention
-
Specific grid -> has tokens , and
-
Average pooling on all -> mean token
-
Cross attention to merge all tokens within a grid into a single token
- Q: mean token
- K, V: all
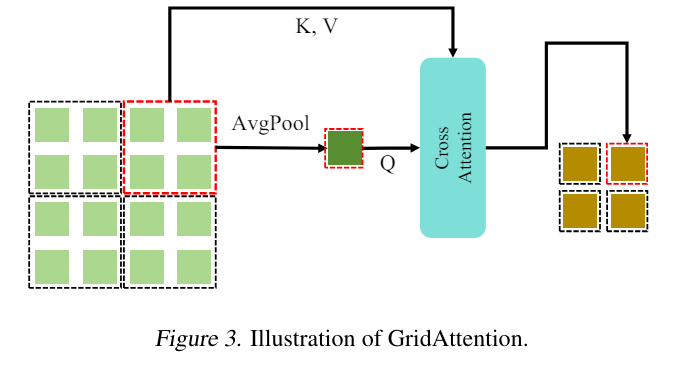
-
Residual connections
-
-
-
Fused token -> FFN to complete channel fusion => One iteration of merging token
-
All iterations share the same weights
-
Gradually decreasing the value of until &
- (similar to standard ViT)
3.3. Fuzzy Positional Encoding
-
Learnable positional encoding + sin-cos positional encoding
=> highly sensitive to changes in input resolution (fail to provide effective resolution adaptability) -
Conv-based PE -> better resolution robustness
- perception of adjacent tokens -> prevents its application in self-supervised learning
Advantages of FPE
- Enhance the model's resolution robustness
- No specific spatial structure like convolution -> self-supervised learning
FPE
Training
-
Randomly initialize a set of learnable PE.
- Typical PE -> provide precise location information to the model
- FPE supplies the model with fuzzy positional information
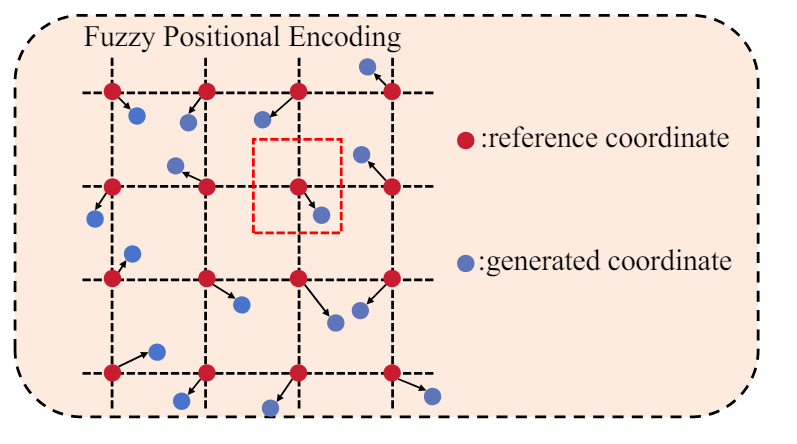
-
Positional information shifts within a certain range
-
as positional coordinates generated with FPE
- : Precise coordinates of the target token
- , uniform distributions
-
Add randomly generated coordinate offsets to the reference coordinates in the training stage
-
Perfrom grid sample on the learnable positional embeddings -> resulting in the FPE
Inference
- Use precise PEs
- Change in the input image resolution -> interpolation on the learnable PEs.
- The model may have seen the interpolated PEs due to FPEs.
=> Robust positional resilience
- The model may have seen the interpolated PEs due to FPEs.
3.4. Multi-Resolution Training
- Multi-resolution training following ResFormer
- ViTAR: high-resolution image with significantly lower computational demands
Traning detail
ResFormer
- process each batch containing various resolutions
- KL loss for inter-resolution supervision
ViTAR
- processes each batch with consistent resolution
- Basic cross-entropy loss for supervision
4. Experiments
- Classification (ImageNet-1K)
- Segmentation (COCO)
- Semantic segmentation (ADE20K)
- Self-supervised (MAE)
4.1. Image classification
Setting
- ImageNet-1K
- Training strategy following DeiT without distillation loss
- AdamW optimizer
- Strong data augmentation and regularization
- Layer decay
Results
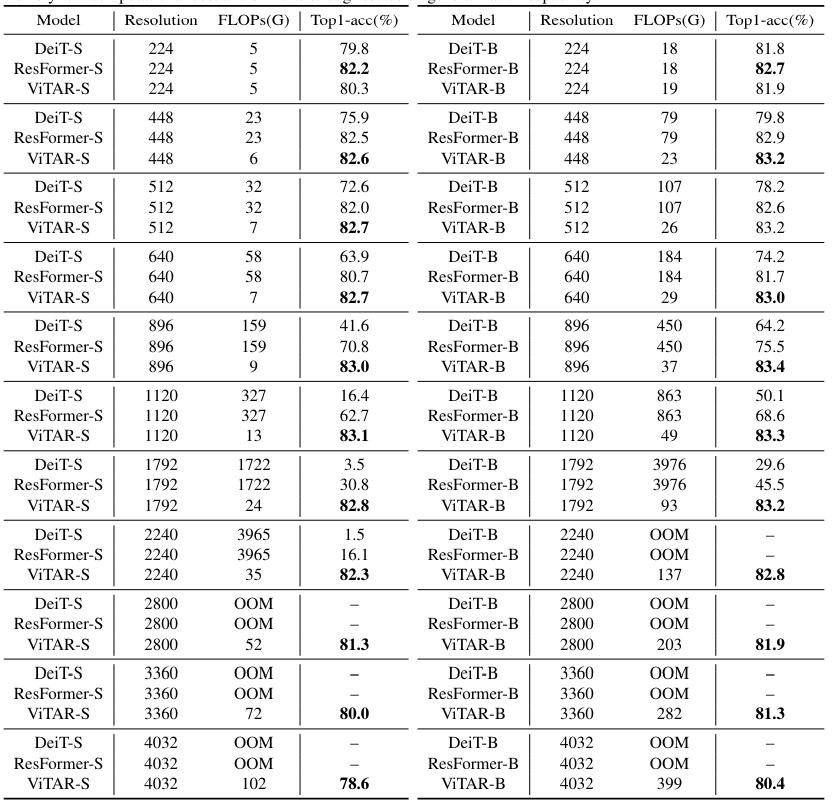
- Capable of inferencing high resolution images
4.2. Object Detection
Setting
- COCO
- Experiment setting s follow the ResFormer and ViTDet
- AdamW
- Do not utilize multi-resolution training strategy
- ATM iterates only once
- => Excellent performance
- => effective
Results
-
Case 1
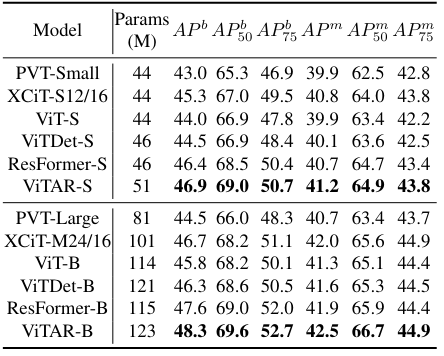
-
Case 2
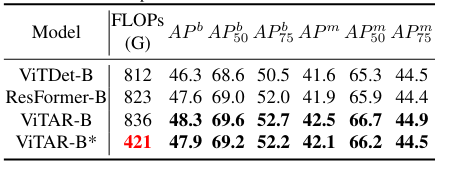
4.3. Semantic Segmentation
Setting
- ADE20K
- UperNet with the MMSegmentation
- => Excellent performance
- => effective
Results
- Case 1
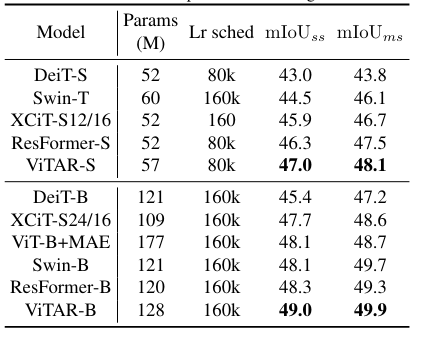
- Case 2
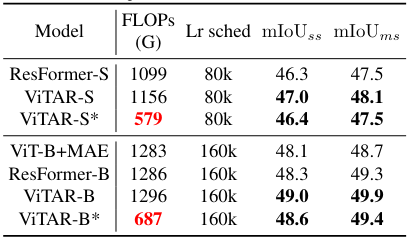
4.4. Compatibility with Self-Supervised Learning
Setting
- FPE > ResFormer in self-supervised learning
- MAE
- Multi-resolution input strategy
- Pretrain 300 epoches, fine-ture 100 epoches
Results

- Better performance overall
Explanation for performance advantage
- ATM enables the model to learn higher-quality tokens (information gain)
- FPE as implicit data augmentation -> robust positional information
4.5. Ablation Study
Adaptive Token Merger
- ATM vs AvgPool
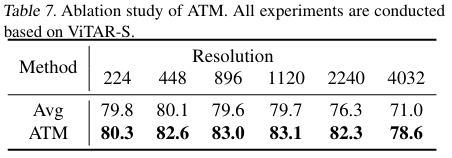
Fuzzy Positional Encoding
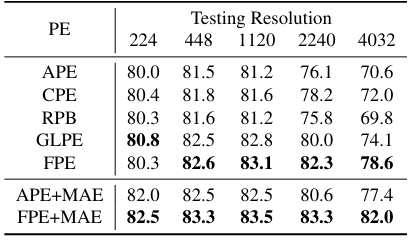
Comparision
- Absolute positional encoding (APE)
- Conditional positional encoding (CPE)
- Global-local positional encoding (GLPE in ResFormer)
- Relative Positional Bias (RPB in SwinT)
- FPE
MAE
- only APE and FPE are compatible with MAE
Results
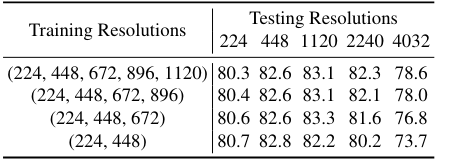
Training resolutions
5. Conclusion
- ViTAR

ssss