Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Stroke를 통해서 painting을 재현하는 방식의 논문이다. 특히, 데이터 셋 없이 Self-training pipeline 을 활용하여 만들어 냈다는 점이 인상깊었다.
Abstract
Neural Painting
Procedure of producing a series of strokes for a given image + non-photo realistic recreation using NN.
RL?
Can generate a stroke sequence step by step
But, training stable RL agents is not easy.
Iterative stroke optimization methods
Stroke optimization methods search for as set of stroke parameters "iteratively" in a large search space, making it less efficient.
Paint Transformer
A novel Transformer-based framework that predicts the parameters of a stroke set with as FFN.
It can generate a set of strokes in parallel and obtaion the final painting of size 512 X 512 in near real time.
Self-training pipeline
No dataset is available for training of the Paint Transformer.
The researchers created self-training pipeline that can be trained w/o any off-the-shelf dataset.
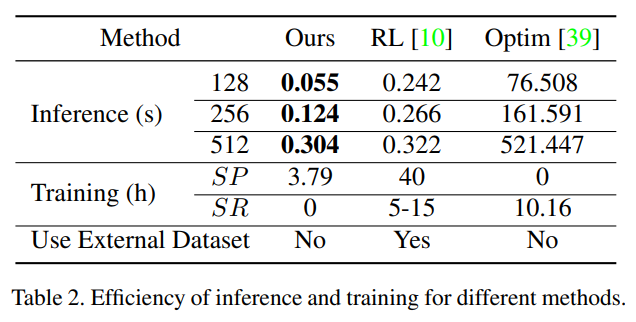
With cheaper traning and inference costs, the methode achieves better painting performance.
Introduction
The goal of this paper seems to be creating a human-creation-like painting, since humans draw painting by stroke-by-stroke procedure. Especially for painting with oil paint or watercolor, the generated paintings can look more like real human.
Previous works
RNN
- Sequential process of generating strokes 1-by-1
- Referred to Sketch-RNN
Step-wise greedy search
- Sequential process of generating strokes 1-by-1
RL
- Sequential process of generating strokes 1-by-1
- Pros: Inference is fast
- Cons: Long training time, Unstable agents
Stroke parameter searching
- iterative optimization
- Pros: results are attractive
- Cons: not enough efficiency and effectiveness.
Overview
Stroke set prediction instead of stroke sequence generation.
Given (initial canvas & target natural image) => predicts set of strokes and render them on the initial canvas to minimize the difference between the rendered image and target one.
This is repeated at K coarse-to-fine(coarse parameter set -> finer parameter set close to the best one in coarse set) scales.
The initial canvas is the output of the previous scale.
The paper suddenly comes with a new concept here.
Set prediction problem? => Object detection!
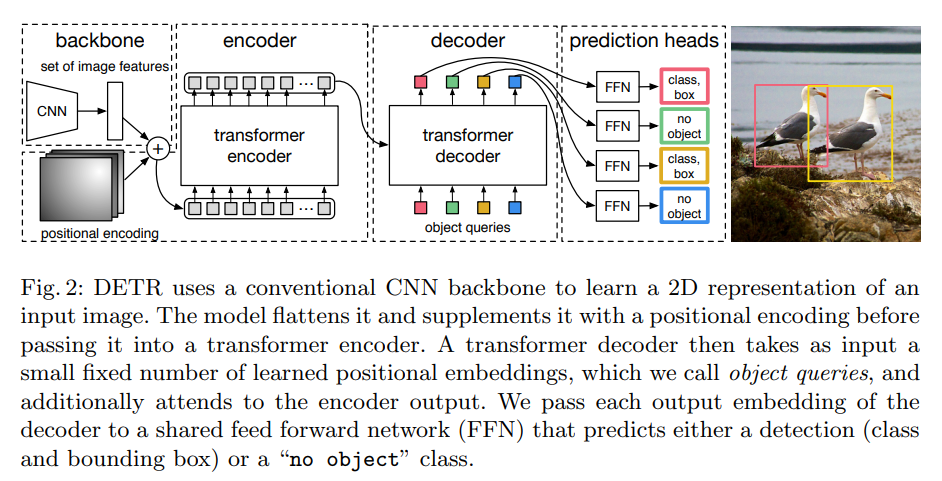
DETR (DEtection TRansformer)
On paper "End-to-end object detection with transformers (2020)" by Facebook AI.
Lack of Data
Unlike object detection, annotated data is unavailable.
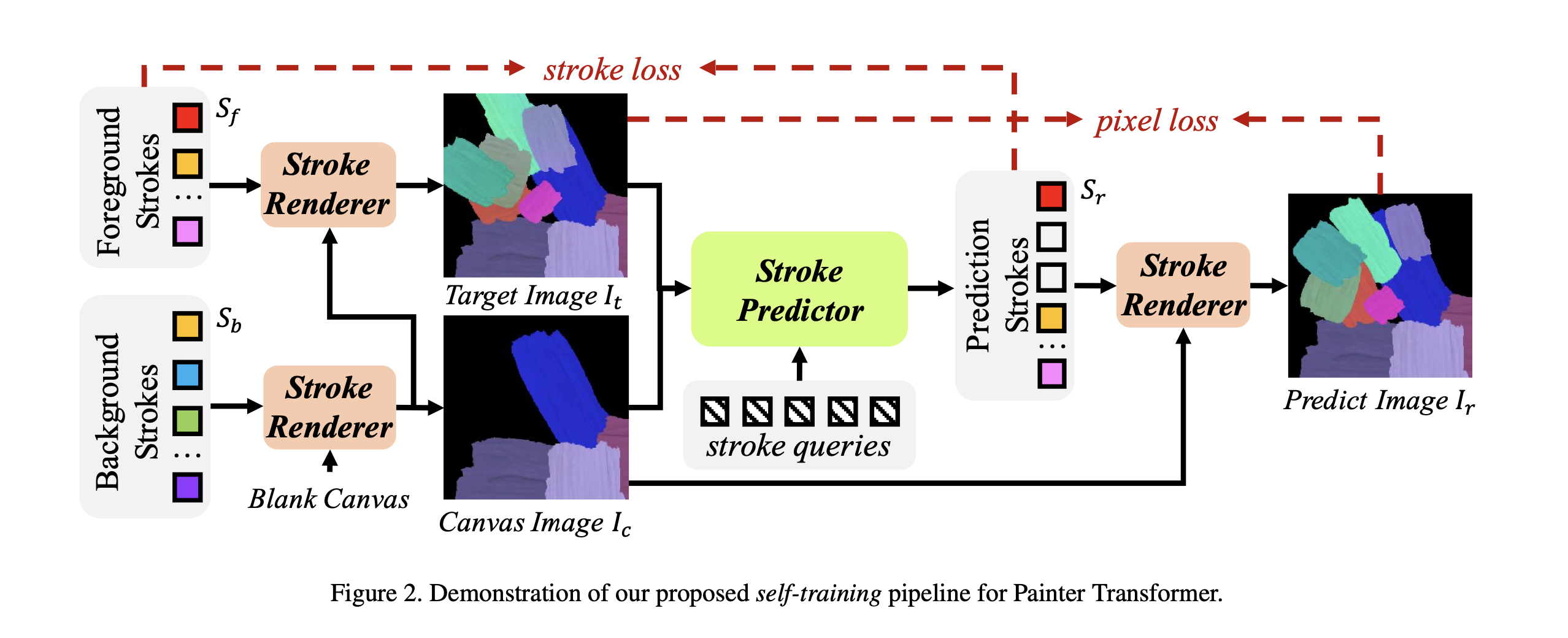
The authors propose a novel self-training pipeline of following steps which utilizes synthesized stroke image.
1. Synthesize a background canvas image with some randomly sampled strokes.
2. Randomly sample a foreground stroke set, and render them on canvas image to derive a target image.
This way, the predictor predicts the foreground stroke set, and the training objective becoms minimizing the difference between synthesized canvas image and the target image.
The optimization is conducted on both stroke and pixel level.
Related Works
Stroke Based Painting
RNN and RL in sequential manner
Object Detection
Recent paper of DETR, performs set prediction w/o post-processing (as non-max suppression)
Methods
Overall Framework
Paint Transformer consists of two modules: Stroke Predictor and Stroke Renderer.
Their relation can be expressed like:
Stroke Predictor
Input: (target image) & (intermediate canvas image)
Generate: Set of parameters to determine current stroke set
Trainablity?: Contains trainable parameters
Stroke Renderer
Input: &
Output: Resulting image ( drawn onto ).
Trainablity: Parameter free, differentiable module.
Self-training pipeline (stroke-image-stroke-image)
It uses randomly synthesized strokes, so that we can generate infinite data for training and do not rely on any off-the-shelf dataset.
The training iterations is as following.
1. Ramdomly Sample (foreground stroke set) and (background stroke set)
2. Generate with
3. Produce (target image) by rendering onto .
4.
5.
Training objective
is stroke loss, and is pixel loss.
Stroke definition and Renderer
A stroke can be denoted as {} and we consider only straight stroke.
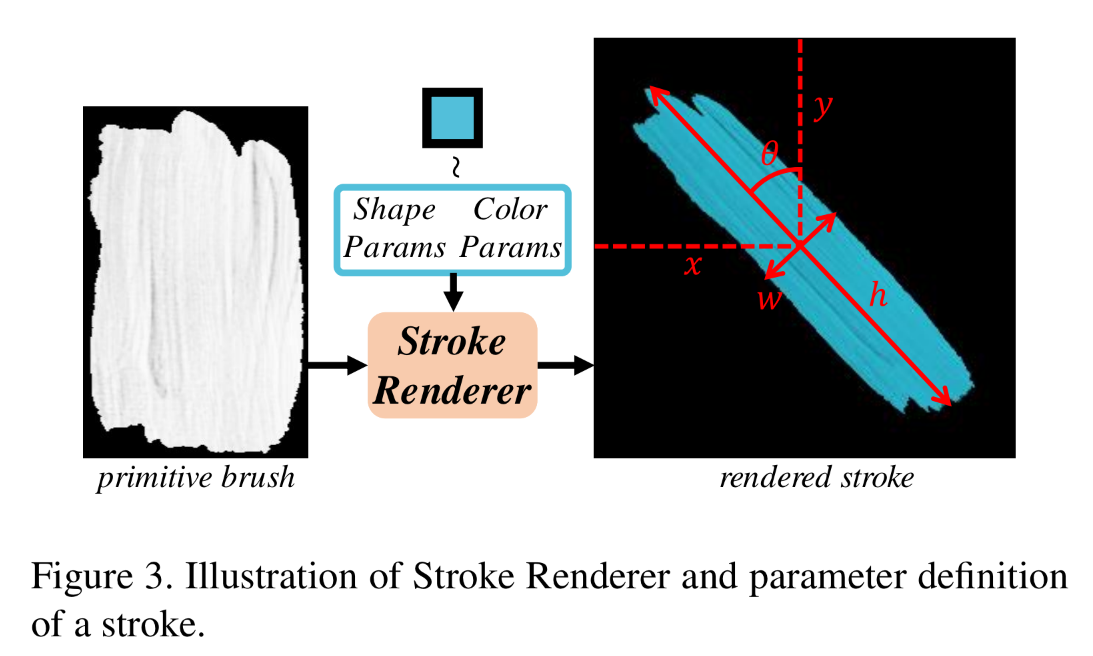
Stroke Renderer
- Geometric transformation based (no NN)
- differentiable (enabling end-to-end learning of Stroke Predictor)
- whole process can be achieved by linear transformationWith a primitive brush and a stroke , we can draw the stroke like Fig.3, obtaining .
is defined as - binary mask of
- generated single-channel alpha map
- same shape with
Denoting ,
The stroke rendering process is like this:Output of the stroke renderer is .
Stroke Predictor
The goal of stroke predictor is to predict a set of strokes that can cover the difference between and .
The authors hoped for few strokes prediction while covering most of the differences.
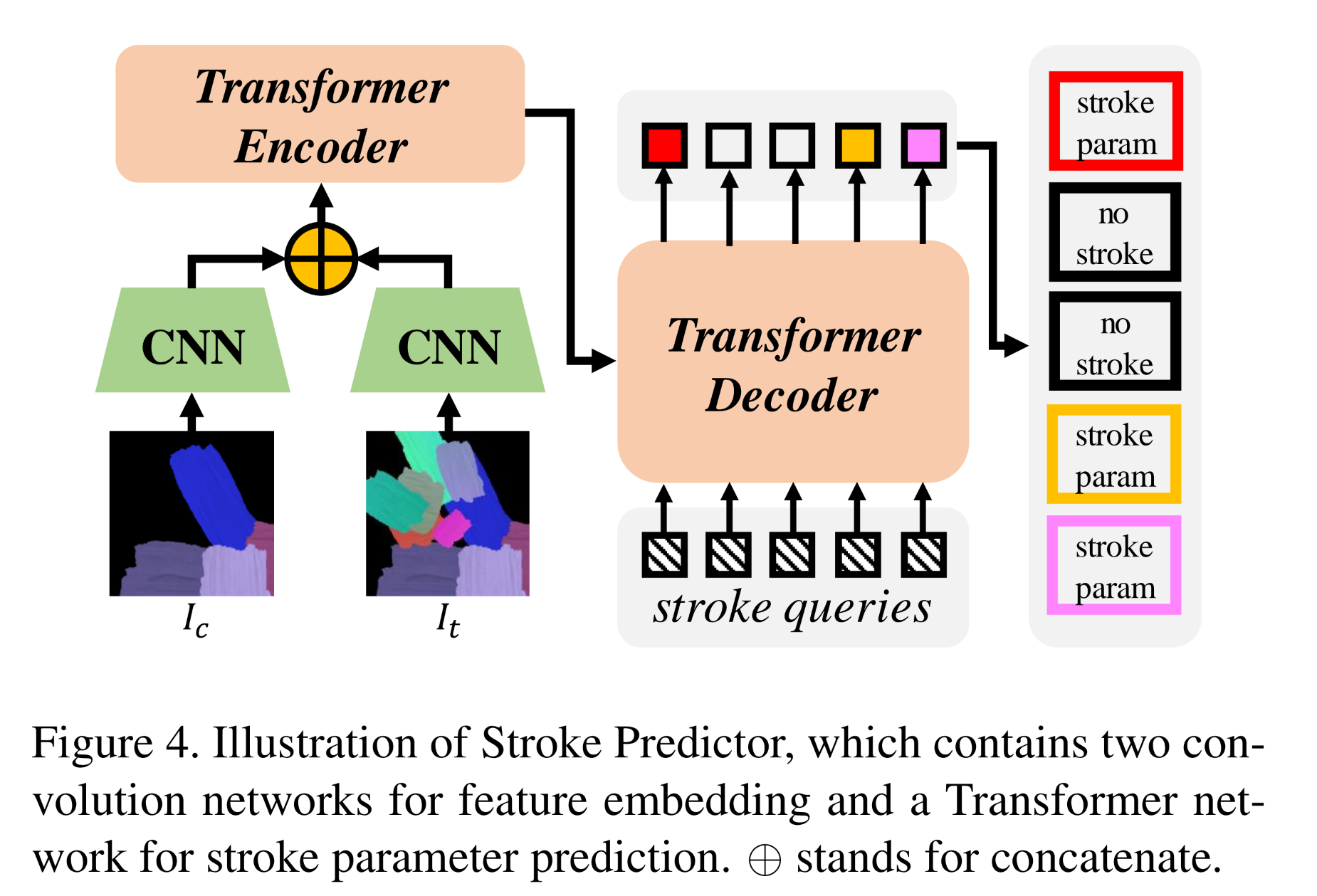
- Input:
- 2 CNNs: Extract feature maps as
- Encoder: and a learnable positional encodings are concatenated and flattened as the input of Transformer Encoder.
- Decoder: Use N learnable stroke query vectors as input.
- 2 branches of Fully-connected layers to predict
- (initial stroke params)
- (stroke confidence)
- convert to a decision .
- is used to determine whether a stroke should be plotted in canvas.
- Special form in backward phase due to back propagation.
Loss Function
Loss consists of pixel loss and stroke loss.
Pixel Loss
Stroke Loss
metric: dismisses different scales for big and small strokes
metric: Wasserstein distance (related to rotation)
metric: BCE of decisions.
: optimal permutations for predicted strokes.

Inference

Experiments
Implementation details
- Size
- CNNs: 3X[Conv-BatchNorm-ReLU]
- Transformer: , 3 layers for encoder and decoder each.
- Training time: 4 hours on 2080Ti.
Comparison