[Deep Learning Specialization]Neural Networks and Deep Learning-Shallow neural networks

1st course: Neural Networks and Deep Learning
🗂 목차
1장: Introduction to Deep Learning
2장: Neural Networks Basics
3장: Shallow neural networks
4장: Deep Neural Networks
3. Shallow neural networks
Shallow neural network란 보통 input layer와 hidden layer, output layer로 구성되어 있는 말 그대로 깊지(deep)않은 얕은(shallow) 인공신경망을 의미한다.
이번 주차에서는 3개의 얕은 층으로 구성되어 있는 neural network에서 층과 층, 그리고 노드와 노드를 통해 데이터가 전달되어 학습되는 과정에 대해서 직접 다루게 되며 각 노드에서 적용되 activation function에 대해서도 살펴본다.
1. Neural Networks Overview
-
앞서, 2주차 강의였던 Neural Networks Basics에서는 Logistic regression에 대해서 자세하게 다루어 봤음
-
Logistic regression이 계산되는 과정은 각각의 노드에서 적용되는 과정으로, 노드에서 계산되는 과정의 중첩이 neural network의 계산 그래프가 진행되는 과정임
-
본격적으로 neural network의 계산 과정을 알아보기 전에 자세한 표기법을 해당 강의에서 deep-learning-notation 제공해줌
2. Neural Network Representation
-
neural network의 명칭 및 구조는 다음과 같음
-
가장 좌측의 x1, x2, x3로 이루어져 있는 부분은 neural network의 입력값으로 Input layer라고 함
-
가작 우측의 하나의 노드로 구성되어 있는 부분은 Output layer로, 결과인 y값을 생성하는 역할을 함
-
중앙에 위치해 있는 부분은 Hidden layer라고 하며, 지도학습 과정 중, 입력값과 출력값이 명시적으로 존재하는 상황과 입력값으로 출력값을 학습하는 과정에서 값들이 명시적으로 보이지 않는 층(hidden)을 의미함
-
-
neural network의 구조에 대한 새로운 표기법은 다음과 같음
-
보통 input layer를 제외한 나머지 layer를 바탕으로 신경망을 정의하며, 다음같은 경우는 2-layer nerual network임
-
각 노드와 층에서는 logistic regression의 계산 과정이 적용되는데, parameter인 w, b의 차원이 hidden layer와 노드의 수의 의해 결정됨
-
첫번째 layer에서 w, b는 각각 (4, 3), (4, 1)의 차원을 가지고 있고, 두번째 layer에서 w, b는 (1, 4), (1, 1)의 차원을 가지고 있음
-

3. Computing a Neural Network's Output
- input layer에 존재하는 입력값 중 하나인 x(i) 데이터가 2개의 layer를 거쳐 output layer에서 결과를 가지는 과정을 다음과 같은 계산 그래프로 정리할 수 있음

-
이는 데이터 x(i) 하나에 대한 계산 그래프를 보여주는 것으로 데이터가 hidden layer의 노드를 거쳐 결과값이 산출되려면 위와 같은 과정이 노드별로 반복 및 중첩된다고 할 수 있음
-
hidden layer의 모든 노드들에서 logistic regression의 계산 과정을 적용하게 되면 각 노드별로 z값을 가지고, 모든 z값에 activation function을 적용하게 되면 4개의 a가 첫번째 hidden layer의 결과로 나오게 됨
-
하지만 위와 같은 하나의 데이터에 대한 모든 노드들에 대한 계산 과정을 4줄의 코드로 간단하게 줄일 수 있음


4. Vectorizing across multiple examples
-
앞서 살펴본 계산 과정은 여전히 x(i), 하나의 데이터에 해당함으로 수많은 데이터에 계산 과정을 벡터화를 통해 보다 빠르게 적용할 수 있음
-
m개의 입력 데이터가 존재할 때, x(1) 부터 x(m)까지 iteration을 통해 각 데이터에 대한 결과값을 구할 수 있음
-
하지만 벡터화를 하게 되면 한번에 계산이 가능함으로 훨씬 빠르게 결과를 구할 수 있음, 이 때 차원을 잘 맞춰주는 것이 중요함

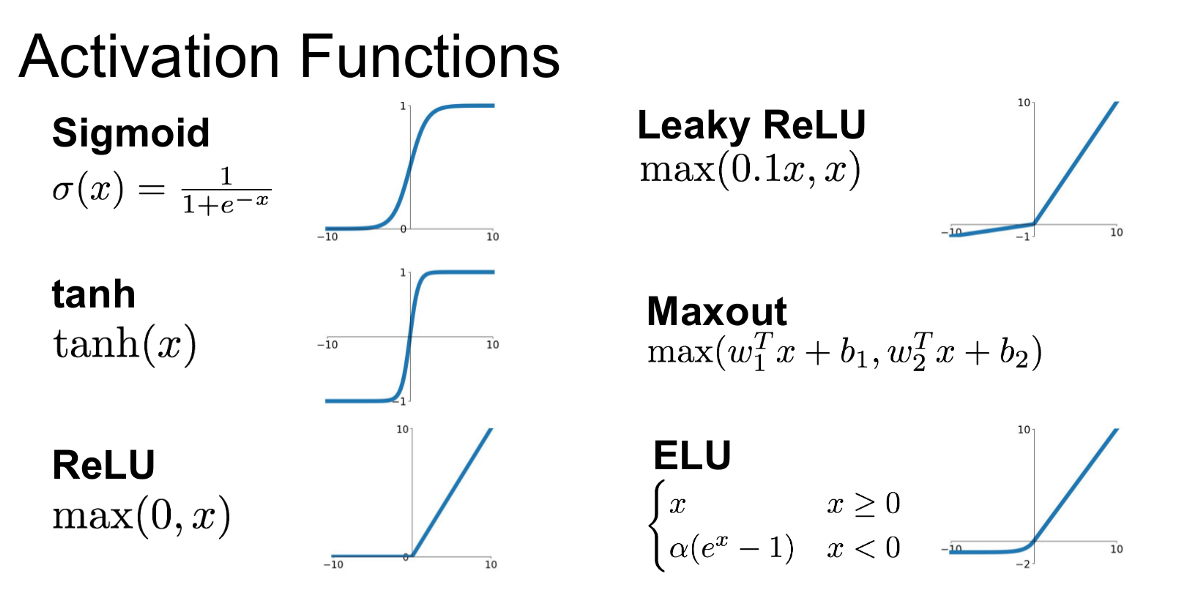
6. Activation functions
-
데이터가 학습되는 과정인 계산 그래프를 보게되면 layer의 결과인 z에 activation function을 적용한 a를 볼 수 있음
-
다양한 종류의 activation function이 존재하며 각 함수마다 다른 특징을 가지고 있음
-
sigmoid: {0 <= a <= 1}, z값이 너무 작거나 크게 되면, 기울기(slope)가 0에 가까워짐으로 gradient descent가 매우 천천히 진행되어 성능이 좋지 않아, output layer에서 주로 사용되는 함수임
-
tanh: {-1 <= a <= 1}, 대부분의 경우에 sigmoid보다 좋은 성능을 보이며 값의 범위가 -1과 +1 사이에 위치하게 되면서, 데이터 평균값이 0에 가깝게 유지되어 다음 층에서의 학습이 보다 수월함
-
Relu: max(0, z), z가 0보다 클 때, 본래의 기울기를 가지는 특징으로 빠르게 gradient descent로 학습해 나갈 수 있기에, 가장 보편적으로 사용되는 함수임
-
Leaky Relu: Relu가 0의 값을 가질 때, 성능이 저하되는 것을 방지하기 위해 개선한 함수임
-
-
activation function이 중요한 이유는, 기울기(slope)를 통해 global optimum을 찾아가는 gradient descent가 반복되는 과정에서, 기울기를 반환해주는 activation function의 종류에 따라, 그리고 데이터 특징에 따라 결과가 달라지기 때문에 최적의 결과를 얻기 위해서는 다양한 접근이 필요함
7. Why do you need non-linear activation functions?
-
그렇다면 비선형의 activation function을 각 층마다 적용하는 이유는 바로 input layer에서 output layer로 학습하는 과정에서 비선형의 특징을 뽑아내기 위해서임
- 비선형 activation function을 적용하지 않거나, 선형 activation function을 적용하게 되면, 층의 깊이에 상관없이 선형 함수의 중첩은 결국 선형 관계에 불과하게 됨

8. Derivatives of activation functions
-
nerual network의 학습을 위해서 backpropagation을 적용하기 위해서는 activation function의 derivative를 구해야함
-
각 activation function의 그래프에서 특정 지점에서의 slope가 activation function의 derivative라고 이해할 수 있음
-
sigmoid: g’(z) = a(1 - a) 이며, 0과 1에 가까워질수록 기울기값이 작아짐을 알 수 있음
-
tanh: g’(z) = 1 - a^2 이며, -1과 1에 가까워질수록 기울기값이 작아짐을 알 수 있음
-
Relu: g’(z) = 0 if z < 0, 1 if z >= 0 이며, leaky relu일 때는 0이 아닌 0.01을 반환해줌
-
9. Gradient descent for Neural Networks
-
이제 2-layer neural network의 gradient descent가 반복적으로 적용되면서 parameter w와 b가 업데이트되는 과정에 대해서 알아볼 수 있음
- 우측의 backpropagation의 과정은 forward propagation를 통해 얻은 결과와 실제 결과와의 차이를 시작으로 각 층의 변화량을 기반으로 loss를 줄여나가는 과정임

- 해당 과정을 조금 더 보기 좋게 코드로 표현하게 되면, 다음과 같음
- forward propagation
Z1 = np.dot(W1, X) + b1 A1 = np.tanh(Z1) Z2 = np.dot(W2, A1) + b2 A2 = sigmoid(Z2)
- backpropagation
dZ2 = A2 - Y dW2 = np.dot(dZ2, A1.T) / m db2 = np.sum(dZ2, axis = 1, keepdims = True) / m dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2)) dW1 = np.dot(dZ1, X.T) / m db1 = np.sum(dZ1, axis = 1, keepdims = True) / m
10. Random Initialization
-
neural network를 설계할 때, 적절한 parameter를 찾기 위한 반복적인 과정을 거치는데, 초기 parameter를 임의로 설정하는 것이 굉장히 중요함
-
neural network에서 초기 weight를 0으로 설정하게 되면 한 layer의 모든 노드에서 같은 결과를 반환하기 때문에 모두 같은 방식으로 update가 진행되어 의미없는 결과가 나오게 됨
-
이렇게 모든 노드에서 같은 연산을 수행하게 되어 똑같은 결과를 가지게 되는 것을 '대칭(symmetry)'이라고 하는데, weight를 랜덤으로 설정함으로써 symmetry breaking 할 수 있게 됨
-
이 때, 랜덤으로 설정하는 weight 값이 매우 크게 되면 기울기가 0으로 소실되어 버리기 때문에 통상 매우 작은 값으로 설정해줌
-
