0. Abstract
문제점 : A singer identification(SID) model may learn to extract non-vocal related features from the instrumental part of the songs, if a singer only sings in certain musical contexts (e.g., genres). The model cannot therefore generalize well when the singer sings in unseen contexts.
이를 해결하기 위한 방법으로, 음악에서 Open-Unmix를 사용하여 보컬(singing voice) 추출함. 그 후 2가지 방법으로 가수 식별 모델을 훈련함.
- 분리된 보컬만 학습
- 서로 다른 노래에서 분리된 보컬과 악기 트랙 “shuffle-and-remix”
- 인위적으로 만든 증강 데이터셋 학습을 통해 가수가 서로 다른 context에서 노래를 부르게 하기 위함
또한 보컬 멜로디 윤곽(vocal melody contour)에서 학습한 멜로디 특징을 통합하여 성능을 향상하고자 함.
1. Introduction
가수들은 보통 자신만의 음악 장르나 스타일을 가지고 있다. train 데이터셋의 가수 label을 가장 정확하게 재현하려고 할 때(ex. classification error와 관련된 손실 함수를 최소화), SID 모델은 실제 작업 내용이 아닌 non-보컬 관련 피처(=보컬 추출)를 활용한다.
- source separation 중 open-unmix 사용함
- CRNN의 구현을 기반으로 SID 모델을 구축.
- 훈련 셋에서 분리된 보컬 트랙과 악기 트랙을 사용하여 "데이터 증강"
- 서로 다른 노래의 분리된 트랙을 무작위로 shuffle한 다음 remix
- 한 명의 가수가 부른 노래의 보컬 부분을 다른 가수가 부른 다른 노래의 악기 부분과 remix.
- 이를 통해 가수들이 다양한 반주 트랙 위에서 노래하도록 인위적으로 만듦 → 보컬과 반주 트랙 사이의 "bonds(결속)"을 느슨하게 함, 방해되는 요소를 완화함.
- SID 모델 인풋으로 가수의 멜로디 윤곽에서 추출된 특징을 추가함
- 멜로디 추출의 SOTA인 CREPE 사용하여 멜로디 윤곽 추출
- 멜-스펙트로그램뿐만 아니라 멜로디 윤곽에서도 특징을 학습하기 위해 convolution layer와 GRU의 stack을 사용
2. Methodology
2-1. Singer Identification models
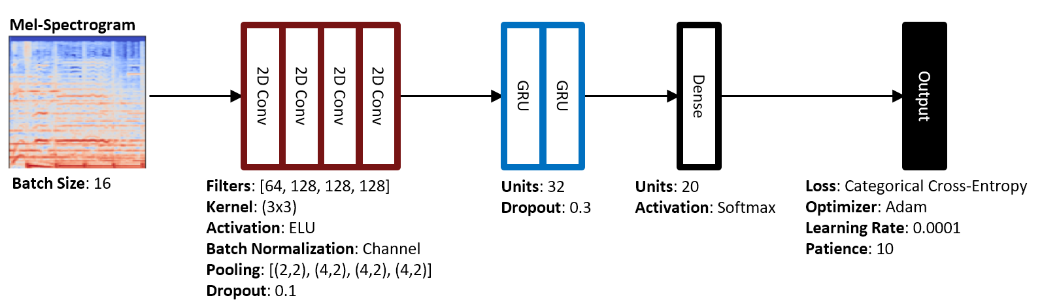
CRNN(Convolution Recurrent Neural Network)
이 모델은 4개의 convolution layer, 2개의 GRU layer, 1개의 dense layer로 구성되어 있음. artist20 데이터셋에서 SOTA를 달성함. 이 모델은 artist20 데이터셋의 앨범별 분할에서 가장 높은 song-level F1 score = 0.67임.
github
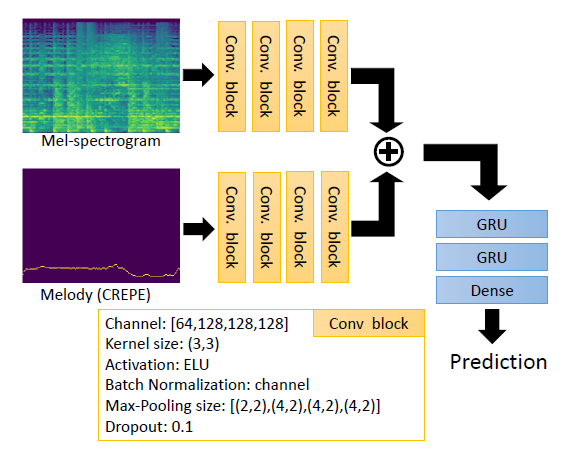
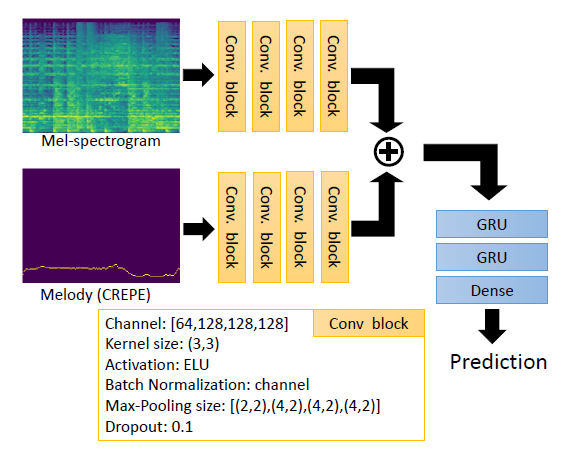
본 논문의 CRNNM 모델은 상단의 CRNN의 구조를 따르고(필터 수, 커널 크기, 활성화 함수, 손실 함수, optimizer, 학습률 등), 두 개의 측면에서 확장됨.
- CREPE를 사용하여 혼합 오디오 녹음에서 멜로디 윤곽을 추출하고 멜로디 특징을 학습하기 위한 추가적인 convolutional branch를 구축함. 간편함을 위해 멜-스펙트로그램 branch와 멜로디 윤곽 branch는 동일한 디자인임.
- 혼합 오디오 녹음이 아니라 open-unmix를 사용하여 보컬만 추출한 멜-스펙트로그램을 사용하고, 제안된 데이터 증강 기술을 사용하여 훈련 데이터셋 크기를 늘림.
CRNNM은 CRNN보다 많은 파라미터를 가지고 있기 때문에 실험에서는 CRNNM과 유사한 파라미터 수를 가진 CRNN의 변형인 CRNNy를 구현함.
CREPE
시간 도메인 오디오 신호에 직접 작용함(waveform 인풋). 피치 추정을 생성하는 convolutional 신경망으로 구성됨. 인풋은 16 kHz sr을 사용하여 시간 도메인 오디오 신호에서 추출한 1024개의 샘플임. 6개의 convolution layer를 거쳐 2048차원의 잠재 표현을 생성하며, 이는 시그모이드 활성화를 가진 아웃풋 layer에 밀집적으로 연결되어 360차원의 아웃풋 벡터 yˆ와 일치함(?). 아웃풋의 360개 노드 각각은 피치를 나타내며 센트 단위로 정의함.
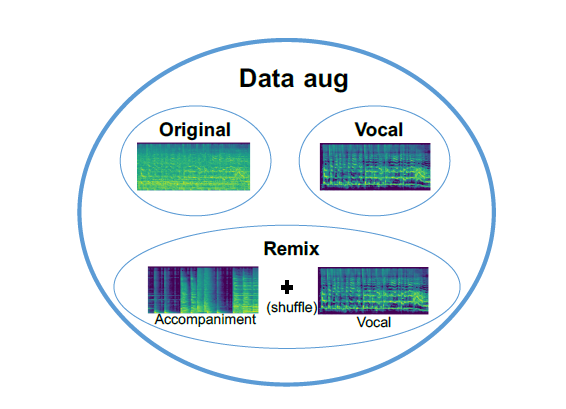
2-2. Data Augmentation: Separate, Shuffle, and Remix
데이터 증강을 사용하는 이유는 잘 일반화시키고, 데이터 불변성을 capture하기 위함임. 노래의 보컬 부분이 다른 노래의 악기 부분과 섞일 때, 해당 가수의 레이블은 동일해야 함. 이러한 관점을 따라 모델을 평가하기 위해 세 개의 데이터 세트, Vocals, Remix 및 Data aug를 생성함.
| 데이터셋 이름 | 설명 |
|---|---|
| Origin | artist20 데이터셋의 원본 오디오임. 20명의 아티스트 당 6개의 앨범이 포함된 데이터로, 총 1413개의 사운드 트랙이 있음. 보컬과 반주가 섞여있음. |
| Vocal-only | Open-Unmix를 사용하여 보컬만 추출한 트랙. |
| Remix | artist20의 분리된 보컬과 악기 트랙을 무작위로 섞어 생성된 데이터셋임. 크기는 Origin과 Vocal-only와 동일. |
| Data aug | 위의 세 세트를 결합한 데이터셋임. |
2-3. Implementation Details
song-split
데이터셋을 무작위로 세 하위 집합으로 나누어 노래를 할당하는 것임. 앨범과 관련된 제작 세부 사항을 훈련 및 테스트 세트에 노출시킬 수 있어 SID 모델에게 분류를 위한 추가적인 단서를 제공함. 따라서 song-split의 정확도는 지나치게 optimistic함(album-split보다 높음) 따라서 본 논문에서는 album-split에 중점에 둠.
album-split
동일한 앨범에 속한 노래가 훈련, 검증 또는 테스트 집합 중 하나에 속하도록 하는 방식임. 2.2에서 언급한 4개의 데이터셋을 사용하여 훈련된 모델의 결과를 고려하고 비교함. 동일한 테스트 세트(Origin)을 사용함. 20-class 분류 모델을 훈련하기 위해 노래를 5초의 segment로 자름. 노래의 최종 예측 결과는 segment별 결과로부터 다수결 투표로 정함. "5초 단위 segment"와 "노래 단위" F1 score 모두 고려하여 평가함. 두 개의 값이 높을수록 성능이 좋음. CRNNM의 경우 멜로디 윤곽의 주파수 축을 다음 layer로 전달하기 전에 128개의 bin으로 양자화함.
4. Conclusions
본 논문에서는 CREPE를 활용하여 멜로디 정보를 이용하고, CRNN에서 확장된 새로운 SID 모델을 제안함. 또한 Source Separation을 사용하여 “shuffle-and-remix”라는 데이터 증강 방법을 도입하여 반주로 인한 혼란을 피하고자 함. 평가 결과는 멜로디 정보와 데이터 증강이 결과를 향상시키는데 (특히 후자가) 큰 영향을 미침.
Future work..
- Singer Identification의 사전 필터로 vocal detector를 사용
- 멜로디 branch에서 convolution을 GRU로 대체하는 것을 조사하는 것
- 음조와 템포를 고려하여 리믹싱할 때, “shuffle-and-remix”의 변형과 같은 다른 데이터 증강법을 시도하는 것
✔ ref
Addressing the confounds of accompaniments in singer identification
