Audio
1.[Audio] AST: Audio Spectrogram Transformer 리뷰

1. AST 제안 배경 (vs CNN) CNNs는 spatial locality 와 translation equivariance 에서 도움이 된다고 여겨지기 때문에, end-to-end 모델링을 위한 raw spectrogram에서 표현을 학습하는 데 널리 사용되었다.
2.[Audio] Deep Learning for Audio Signal Processing 리뷰
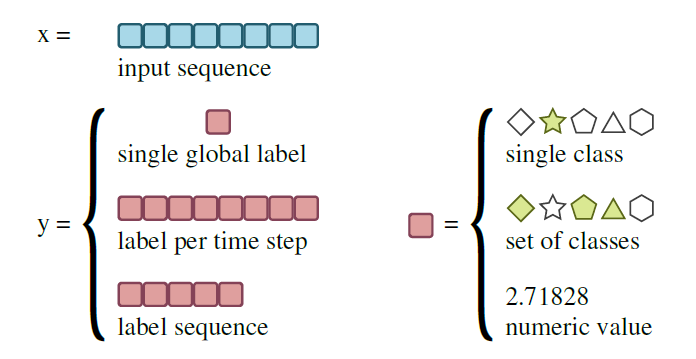
image vs audioaudio는 image 보다 데이터가 불충분함image는 보통 2차원인 반면 audio의 원시 파형은 1차원임image는 순서에 대한 제약이 덜 하지만 audio는 chronological order오디오의 시계열인 인풋으로부터 예측될 수 있는
3.[Audio] Conformer: Convolution-augmented Transformer for Speech Recognition 리뷰

0. Abstract 최근 Transformer와 Convolution Neural Networks (CNNs) 기반의 모델이 Automatic Speech Recognition (ASR)에서 Recurrent Neural Networks (RNNs)을 능가하는 결과를
4.[Audio] Wav2Vec 리뷰
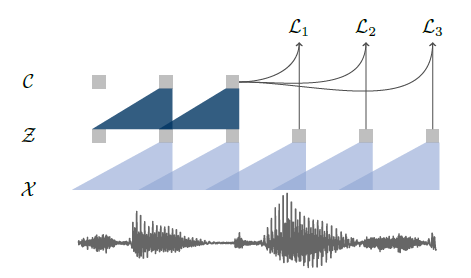
본 논문은 raw audio 표현으로부터 학습한 음성 인식의 비지도 사전 훈련을 탐구한다. wav2vec은 레이블이 지정되지 않은 대량의 오디오 데이터에서 훈련되며 최종적인 표현은 음향 모델의 향상을 위해 사용된다.모델이 좋은 성능을 얻기 위해선 많은 양의 데이터가 필
5.[Audio] SpecAugment 리뷰 및 구현

기존의 음성 신호 데이터 증강은 raw waveform에서의 변형이었으나, 인풋으로 주로 log-mel 스펙트로그램을 사용하기에 이 자체를 이미지로 인식하여 변형하는 SpecAugment라는 데이터 증강 방법을 제안한다. 인풋으로 log-mel 스펙트로그램을 사용하며
6.[Audio] Demucs의 계보
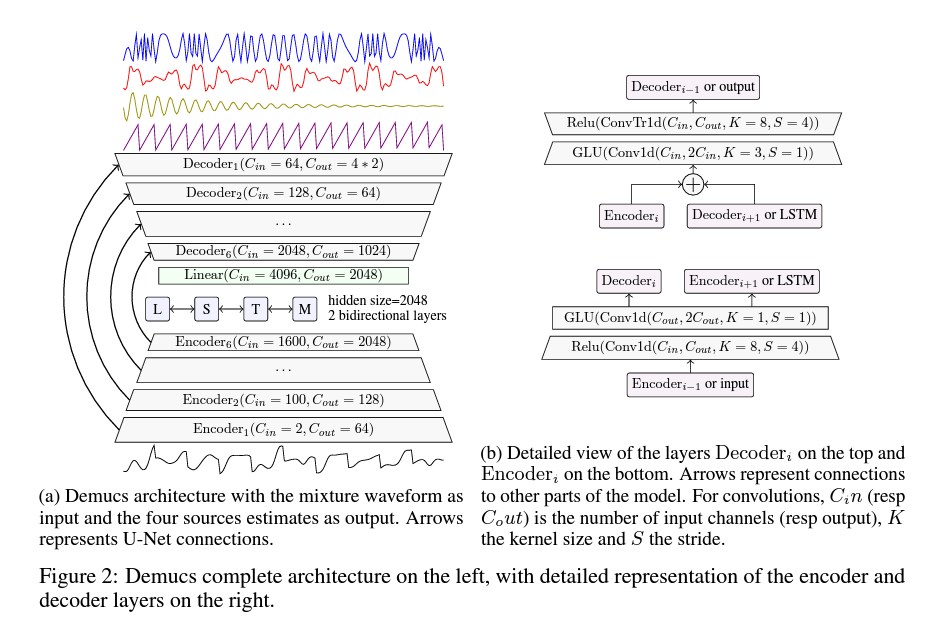
input : raw waveformoutput : 각 악기 소스 별 waveform 생성 (drum/bass/others/vocal)U-net 구조 : convolution encoder, wide transposed convolution 기반의 decoder enc
7.[Audio] Pop2Piano 리뷰
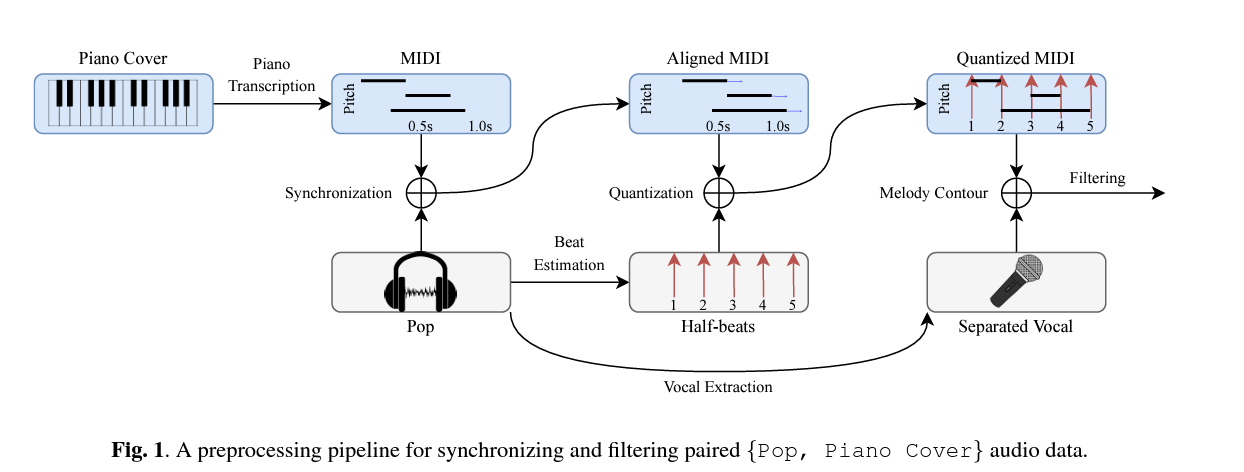
Transformer based paino cover 생성 모델인 Pop2Piano를 소개한다. 이는 팝 음악의 파형으로부터 piano performance (MIDI)를 만들어내는 모델이다. 피아노 커버 생성에 대한 새로운 접근 방식을 제안한다. P2P(Piano C
8.[Audio] TACOTRON: Toward End-To-End Speech Synthesis 리뷰
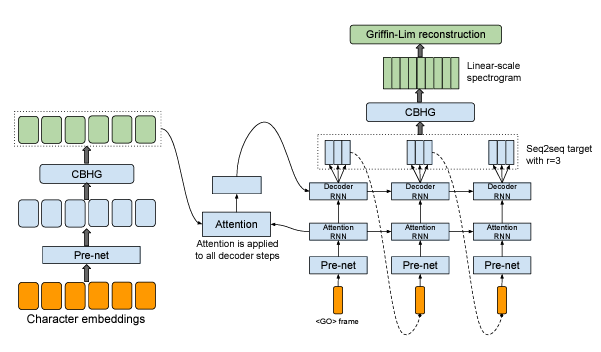
통계적 파라미터 TTS텍스트 프론트엔드가 다양한 언어적 특징을 추출하고, 지속 시간 모델, 음향 특징 예측 모델, 복잡한 신호 처리 기반 Vocoder가 있음. 이러한 구성 요소들은 광범위한 도메인 전문 지식을 기반으로 하며, 설계하기 어렵고, 독립적으로 훈련되어 각
9.[Audio] Self-Supervised Contrastive Learning for Singing Voices
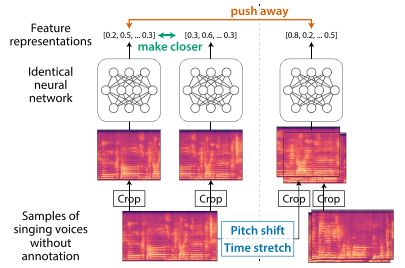
문제점 : 사람들의 음악 취향 중 주요한 요소 중 하나는 singing voice(노래하는 목소리)이지만 이에 대한 연구가 충분히 되지 않음. 그 이유는 대규모 데이터셋을 구하기 어렵기 때문임. 본 논문에서는 자기 지도 대조 학습을 통해 다중 음악(polyphonic
10.[Audio] Addressing the Confounds of Accompaniments in Singer Identification
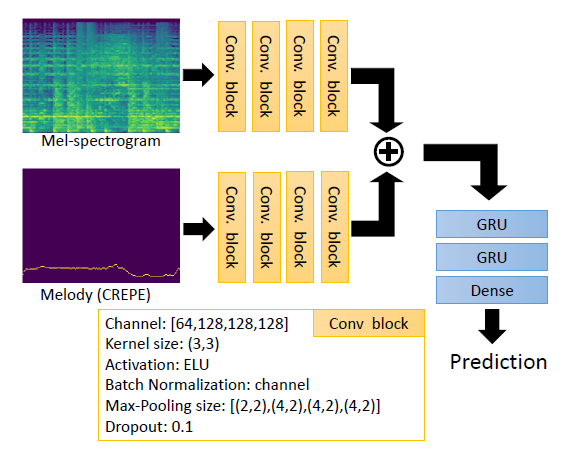
0. Abstract 문제점 : A singer identification(SID) model may learn to extract non-vocal related features from the instrumental part of the songs, if a sin