1. Introduction
문제점 : 사람들의 음악 취향 중 주요한 요소 중 하나는 singing voice(노래하는 목소리)이지만 이에 대한 연구가 충분히 되지 않음. 그 이유는 대규모 데이터셋을 구하기 어렵기 때문임.
본 논문에서는 자기 지도 대조 학습을 통해 다중 음악(polyphonic music)에서 분리된 목소리에 특화된 방식으로 특성 표현 학습을 실현하고자 함. 신경망을 훈련시켜 원본 샘플과 해당 샘플의 변형 버전의 특성 표현을 서로 다르게 만들도록 한 후 네트워크는 특정 변형에 민감한 표현을 습득함. 여기서 2개의 변형을 고려함.
- 음정 이동(pitch shifing)
- 음정과 포먼트 모두 변경 가능
- 보컬 음색에 중점을 둔 표현 산출 가능
- 시간 스트레칭(time stretching)
- 노래의 표현을 변형시켜 영향을 줌
- ex. 비브라토 비율 및 음계 전환에서의 기본 주파수(F0) 윤곽을 수정함
포먼트(formant) : 목소리의 스펙트럼에는 특정 부분에 peak가 있으며 이를 특정 인물의 특징인 포먼트라 부름. (고정/이동 포먼트 존재)
2. Related Work
2-1. Representation Learning for Singing Voices
- 가수 식별(Singing Identification)
주로 MFCCs와 같은 피처를 사용하여 보컬 음색을 포착했으며, handcrafted 피처를 설계하여 목소리의 비브라토(vibrato)를 포착하거나 스펙트로그램에서 보컬을 분류하고자 딥러닝 기술을 사용했음. 그러나 유사성 계산을 가정하지 않아 다른 MIR 에서 제한됨.
본 논문은 자기 지도 방식을 통해 특성 표현을 학습하여 가수 식별에 의존하지 않고 유사성 계산에 사용될 수 있는 특성 표현을 획득할 수 있음.
- 유사성 계산
초기에는 비지도 학습인 Gaussian mixture models/latent Dirichlet allocation을 MFCCs나 LPCs에 적용함. 그러나 MFCCs나 LPCs에 의존하면 계산된 유사성이 주로 보컬 음색만을 반영함.
최근에는 본 논문과 유사한 방식으로 특성 표현 학습을 사용하여 유사성 계산을 함. 그러나 이는 동일한 가수의 노래 목소리에 대한 특성 표현을 서로 가깝게 만들고 다른 가수의 것은 멀리 밀어내기 위해 지도 학습을 사용함.
반면, 본 논문은 자기 지도 방식으로 계산적으로 변형하여 유사성 계산에 사용할 수 있는 특성 표현을 획득함.
2-2. Self-Supervised Contrastive Learning
자기 지도 대조 학습은 신경망을 훈련시켜 샘플의 특성 표현을 해당 샘플의 positive anchor/negative anchor의 특성 표현과 각각 유사하게/다르게 만들도록 함. 이때, positive anchor는 데이터셋의 샘플에 계산적인 변형을 적용하여 생성되며, negative anchor 데이터셋 내의 다른 샘플을 나타냄. 손실 함수를 최소화함.
3. Self-Supervised Contrastive Learning for Singing Voices
3-1. Proposed Approach
- 수정된 MoCo
기존의 MoCo : 네트워크를 훈련시켜 샘플의 특성 표현을 샘플의 positive anchor(=변형된 버전)과 코사인 유사성을 기준으로 유사하게 함.
본 논문에서는 수정된 MoCo를 사용하여, 제안된 변형을 사용하여 negative anchor를 생성하고 이를 원본 샘플과 다르게 만들도록 함. 이를 통해 변형에 의한 변화에 민감한 특성 표현을 얻음.
-
positive anchor : 데이터셋 내의 다른 샘플로 노래하는 목소리의 지속 시간은 다양할 수 있으므로, 인풋으로 사용하기 전 지속 시간으로 자름. 동일한 샘플에서 나온 컷은 동일한 가수가 노래를 부른 것으로 간주되므로 이들의 특성 표현은 서로 가까워야 함.
-
negative anchor : 음정 이동/시간 스트레칭으로 변형된 버전
❓ Moco를 수정한 이유?
노래하는 목소리를 시간적으로 섞어 negative anchor를 생성하고 획득된 표현을 조사했음. 그 결과 시간적 섞기(temporal shuffling)은 오디오 신호에서 부자연스러운 아티팩트를 생성하고 (ex. 비연속적인 변화) 이러한 아티팩트에 민감한 표현을 생성함. 따라서 자연스러운 노래 목소리로 나타날 가능성이 있지만 다른 가수가 부른 것처럼 느껴지도록 하는 negative anchor를 생성해야 함.
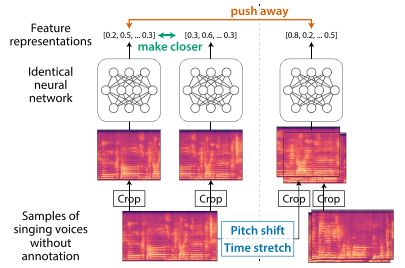
- 변형
음정 이동과 시간 스트레칭 변형은 훈련된 신경망이 각각 보컬 음색과 노래 표현을 구별하도록 함.
보컬 음색은 주로 스펙트럼 포락선(스펙트럼의 최대값을 저주파부터 고주파까지 연결한 선)과 포먼트에 의존하는데, 이는 단순한 음정 이동(타임 스트레칭 x) 이후에 크게 변경되므로 음정 이동된 노래 목소리는 서로 다른 보컬 음색을 갖는 것처럼 인식되기 쉬움. 따라서 음정 이동된 버전을 구별하도록 네트워크를 훈련시키면(=negative anchor로 음정 이동된 노래하는 목소리를 추가함), 보컬 음색의 스펙트럼 변화에 민감한 특성 표현을 얻을 수 있음.
시간 스트레칭은 다른 가수들에 의해 만들어진 노래 표현처럼 들릴 수 있는 노래 목소리를 생성함. 이때, 짧은 기간 동안의 articulations에 관련된 노래 표현에 중점을 둠. (ex. vibrato rate, 노트 전환에서의 F0 윤곽) 비브라토는 목소리에서 명확한 표현적인 특징 중 하나이며, 그 속도는 노래의 템포에 상관없이 상당히 일정함. 노트 전환에서 F0 윤곽의 급격한 변화도 노래 표현을 나타내는 신호임. 이러한 시간적인 표현은 시간 스트레칭(음정 이동 x) 이후에 크게 변경됨. 따라서 시간 스트레칭된 버전을 구별하도록 네트워크를 훈련시키면(=negative anchor로 시간 스트레칭된 노래하는 목소리를 추가함), 노래 표현의 시간적인 변화에 민감한 특성 표현을 얻을 수 있음.
3-2. Data
Million Song Dataset(240,000 곡의 30초 오디오 프리뷰)를 기반으로 더 큰 데이터셋을 구축함. 데이터셋에서 50개 이상의 노래를 가진 아티스트 중 무작위로 500명을 추출하여 데이터셋에서 제거함. 최종적으로 500명의 샘플된 아티스트의 모든 노래가 제외된 328,418곡의 노래를, 아티스트 이름 없이 자기 지도 학습에 사용함. 그 후 Spleeter를 모든 노래에 적용하여 노래하는 목소리를 분리함. 그 후 노래 목소리 탐지를 적용하고 지속 시간이 0.5초 이상의 silence section을 제거함.
3-3. Implementation and Training Procedure
CRNN 구조 채택함. PyTorch를 사용하였으며 인풋은 5초의 오디오 단편의 스펙트로그램, 아웃풋은 256차원의 특성 표현 벡터임. 인풋의 다양성을 위해 데이터셋의 노래 목소리를 사전에 5초로 자르지 않고 훈련 중에 랜덤으로 자르도록 구현함.
- 사용한 변형
-
음정 세 반음 올리기
-
음정 세 반음 내리기
-
속도 ×1.70으로 높이기
-
속도 ×0.65로 낮추기
변형을 구현하기 위해 SoX 유틸리티4(버전 14.4.2)를 torchaudio5를 통해 사용함. 음정 이동을 위해 옵션 pitch +300 or -300, 시간 스트레칭을 위해 tempo 1.70 or 0.65의 옵션을 사용하여 SoX를 호출함.
-
노래의 일부를 자르고 negative anchor를 생성하기 위해 넷 중 하나의 변형이 동일한 확률로 적용됨. 또한, 동일한 샘플에서 자른 다른 부분은 어떠한 변형도 적용하지 않고 positive anchor로 사용됨.
훈련은 네 개의 NVIDIA Tesla V100 GPU에서 약 2.5일 소요됨. 또한 변형의 조합을 변경하여 사용하는 경우(즉, 양쪽 또는 어느 것도 포함하지 않는 네 가지 조합)를 비교하기 위해 동일한 네트워크를 훈련함. Adam을 사용하여 네트워크 매개변수를 최적화하였으며, 학습률은 0.01이었고, 25, 50, 75 및 100 epoch에서 0.2로 제곱됨. 또한 momentum encoder 크기는 4096. 자기 지도 학습 이후에는 네트워크가 특성 표현을 추출하는 데만 사용되도록 동결됨.
4. Singer Indentificaton
제안한 방법으로 얻은 특성 표현의 효과를 평가하기 위해 가수 식별 작업을 수행함. 여기서 획득한 특성 표현을 기반으로 아티스트 이름을 식별하기 위한 분류기를 훈련하고, 전통적인 특성을 사용하여 훈련된 동일한 분류기와 정확도를 비교함.
4-1. Data
사전에 필터링한 500명의 아티스트들의 목소리를 사용함(각 아티스트당 50곡을 샘플링하여 총 25,000곡). 이는 3-2와 동일한 방법으로 전처리한 후 train/valid/test를 각 아티스트 별로 40곡/5곡/5곡로 split함.
4-3. Results
음정을 이동하고 시간을 늘리거나 줄인 샘플을 함께 negative anchor로 사용한 경우가 가장 우수한 성능을 보임.
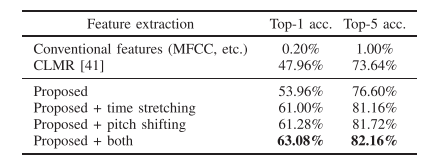
5. Vocal Timbre-or Singing Expression-Oriented Representations
위에서 음정 이동과 시간 스트레칭을 같이 사용하여 negative anchor를 생성하는 경우가 최고의 성능을 달성했으나 positive anchor를 생성할 때는 둘 중 하나를 사용할 수 있음. 다시 말해, negative anchor를 증강하는 대신 positive anchor를 보완할 수 있다. 그렇게 얻은 특성 표현은 음성 팀버 또는 노래 표현 중 하나에 주의를 기울일 것으로 예상됨.
본 논문에서는 시간을 늘린 positive anchor와 음정을 변경한 negative anchor로 훈련된 네트워크와 음정을 변경한 positive anchor와 시간을 늘린 negative anchor로 훈련된 다른 네트워크를 준비하여 동일한 데이터셋으로 CRNN을 훈련시키고 네트워크를 사용하여 데이터셋의 노래 목소리의 표현을 추출함. 전자의 표현을 vocal timbre-oriented이라고 하고, 후자의 표현을 singing expression-oriented이라고 함.
5-1. Song Genre
수집한 데이터셋의 노래 장르 label을 사용하여 각 장르에서 노래하는 목소리의 특성 표현의 차이를 조사함. 이때 각 장르의 노래 표현의 분산(해당 장르의 평균 표현에서 각 표현의 L2 거리의 제곱 평균)을 계산하고 분산순으로 주요 장르를 나열함.

- Results
- Hip-Hop/Rap이 두 경우에서 모두 최하위에 랭크되어 있습니다. 이는 Hip-Hop/Rap 노래가 음성 팀버 및 노래 표현 측면에서 일관된 노래 목소리를 가지고 있다고 판단되었음을 의미합니다.
- 이에 반해 일반적으로 다양한 종류의 노래를 다루는 Alternative, Rock, Pop 및 J-Pop은 상위에 랭크되어 있습니다. 이는 이러한 장르가 다양한 음성 팀버 및 노래 표현을 갖춘 것으로 판단되었음을 의미합니다.
- 마찬가지로, Country 노래는 음성 팀버 및 노래 표현 지향적 표현에 대해 각각 큰 분산과 작은 분산을 나타냈습니다.
- Anime 노래는 반대로 평가되어 음성 팀버는 유사하고 노래 표현은 다양하다고 판단되었습니다. 음성 팀버의 다양성을 줄이기 위한 편향이 존재할 수 있습니다. Anime 노래는 종종 애니메이션 캐릭터의 목소리를 내는 성우들에 의해 부르기 때문이며, 배우들은 주어진 애니메이션 캐릭터에 따라 표현을 변경할 수 있습니다. 그러나 그들은 체구의 물리적 제약 때문에 음성을 급격하게 변화시키는 것이 어려울 것입니다.
5-2. Singer Gender
Vocal timbre-oriented 표현의 플롯은 singing expression-oriented 표현의 플롯보다 남성과 여성 가수 간에 더 명확한 차이를 보여줌. 이러한 결과는 두 표현이 노래 목소리의 음색 및 노래 표현과 관련된 서로 다른 특성을 가지고 있을 수 있다는 것을 보임.
5-3. Exploration With VocalSet
- 데이터셋
VocalSet다양한 음성 기술(ex.비브라토, 트릴)이 있는 20명의 가수의 노래 목소리임.
- 방법
- 데이터셋의 각 노래 목소리를 쿼리로 사용하여 특성 표현으로부터 계산된 유사성을 기반으로 다른 노래 목소리를 순위 매김.
- 높은 순위의 노래 목소리가 쿼리와 가수 or 음성 기술을 공유하는지를 확인함. 이때 MRR(mean reciprocal ranking) [65]을 계산함.
- 쿼리의 상위 k 결과 중 가수 또는 음성 기술을 공유하는 노래 목소리의 비율인 Precision at k (Prec@k)를 계산함.
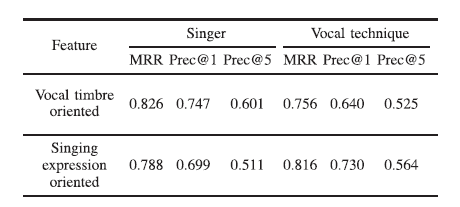
- 결과
vocal timbre-oriented은 쿼리로 사용된 동일한 가수의 노래 목소리를 검색하는 측면에서 우수한 성능을 나타냄. 반대로, singing expression-oriented은 동일한 음성 기술을 가진 노래 목소리를 검색하는 경우에 더 좋은 성능을 나타냄. Student의 t-검정을 수행했을 때 MRR, Prec@1 및 Prec@5의 모든 지표가 가수 및 음성 기술에 대해 p < 0.001임. 즉, 둘 다 유의미하게 다른 성능을 나타냄.
이러한 결과는 긍정적인 앵커와 부정적인 앵커를 생성하기 위해 시간 스트레칭과 음높이 변경을 각각 사용하는 제안된 접근 방식이 획득된 특성 표현을 음성 팀버 또는 노래 표현에 주의 깊게 만들었다는 것을 보임.
6. Conclusions
본 논문에서는 자기 지도 대조 학습을 노래하는 목소리에 특화된 방식으로 소개함.
- 음색과 노래 표현에 주의를 기울인 특성 표현을 획득할 수 있도록 신경망을 훈련시킴. 음정 변경 및 시간 스트레칭을 구별하게 함으로써 자체 지도 대조 학습을 활용함.
- 획득된 표현이 가수 식별의 정확도를 향상시키는 데 도움이되는 것을 실험적으로 확인함.
- 제안된 접근 방식이 음성 팀버 또는 노래 표현과 관련하여 유사한 노래 목소리를 검색할 때 사용할 특성 표현을 획득하는 데 확장될 수 있음.
✔ ref
Self-Supervised Contrastive Learning for Singing Voices
