
크롤링(crawling) 이란
웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다. 프로그래밍으로 자동화할 수 있다.
🤔 Puppeteer 란
Puppeteer는 Headless Chrome 혹은 Chromium를 제어하도록 도와주는 라이브러리이다.
Headless Brower
Headless Browser는 CLI (Command Line Interface) 에서 동작하는 브라우저이다. 일반적으로 사용자가 사용하는 GUI 에서 동작하는 브라우저가 아니다. 백그라운드에서 동작하며, 실제로 브라우저 창을 띄우지 않고 백그라운드에서 가상으로 진행되며 특정 페이지에 접속하고 렌더링한다.
Puppeteer 주요 기능
- 웹 페이지에서 자동화된 테스트를 실행. JavaScript 테스트를 최신 버전의 Chrome 에서 직접 수행할 수 있다.
- 사이트의 timeline trace 를 기록하여 성능 문제를 진단할 수 있다.
- Chrome Extensions을 테스트 할 수 있다.
- PDF 생성
- 스크린샷 찍기
- 지루한 작업 자동화. Form Submit, UI 테스트, 키보드 입력 등을 자동화 한다.
- 웹 사이트에서 데이터를 가져와 저장
SPA(Single-Page Application)를 크롤링하고 미리 렌더링된 컨텐츠 (SSR- Server Side Rendering)를 생성 할 수 있다.
예제 프로젝트 Setup
예제 프로젝트를 진행하기 위해선 사전 세팅이 필요하다.
코드 에디터 설치
node js 설치
yarn 설치
- 원하는 경로에 폴더를 하나 만든다.
- 터미널에서
yarn install명령어로 패키지를 생성한다. - 터미널에서
yarn add puppeteer명령어로 puppeteer를 설치한다. - 코드 에디터에서 폴더를 연다. (여기선 Visual Studio Code 를 이용한다)
- 코드 에디터에서
hotel.js파일을 생성한다. (예제 1)
Puppeteer를 이용한 예제 1
최근에 여기어때가 경쟁업체 야놀자 숙박정보 데이터베이스를 무단 크롤링한 행위가 위법하다는 법원 판단이 나왔다. 크롤링을 위법한 곳에 사용하면 이렇게 감옥에 갈 수 있으니 조심하자.
여기어때, 야놀자 DB 무단수집 위법 판결...심명섭 전 대표 1심 집유
그래서 우리는 여기어때의 홈페이지에서 호텔 숙박정보를 크롤링해보자. 여기어때 홈페이지에서 호텔 페이지에 들어가보면 다음과 같이 호텔 숙박정보가 리스트로 뜬다. 우리는 puppeteer를 이용해 여기어때 호텔 홈페이지에 접속해 모든 호텔 숙박정보 리스트를 크롤링할 것이다.
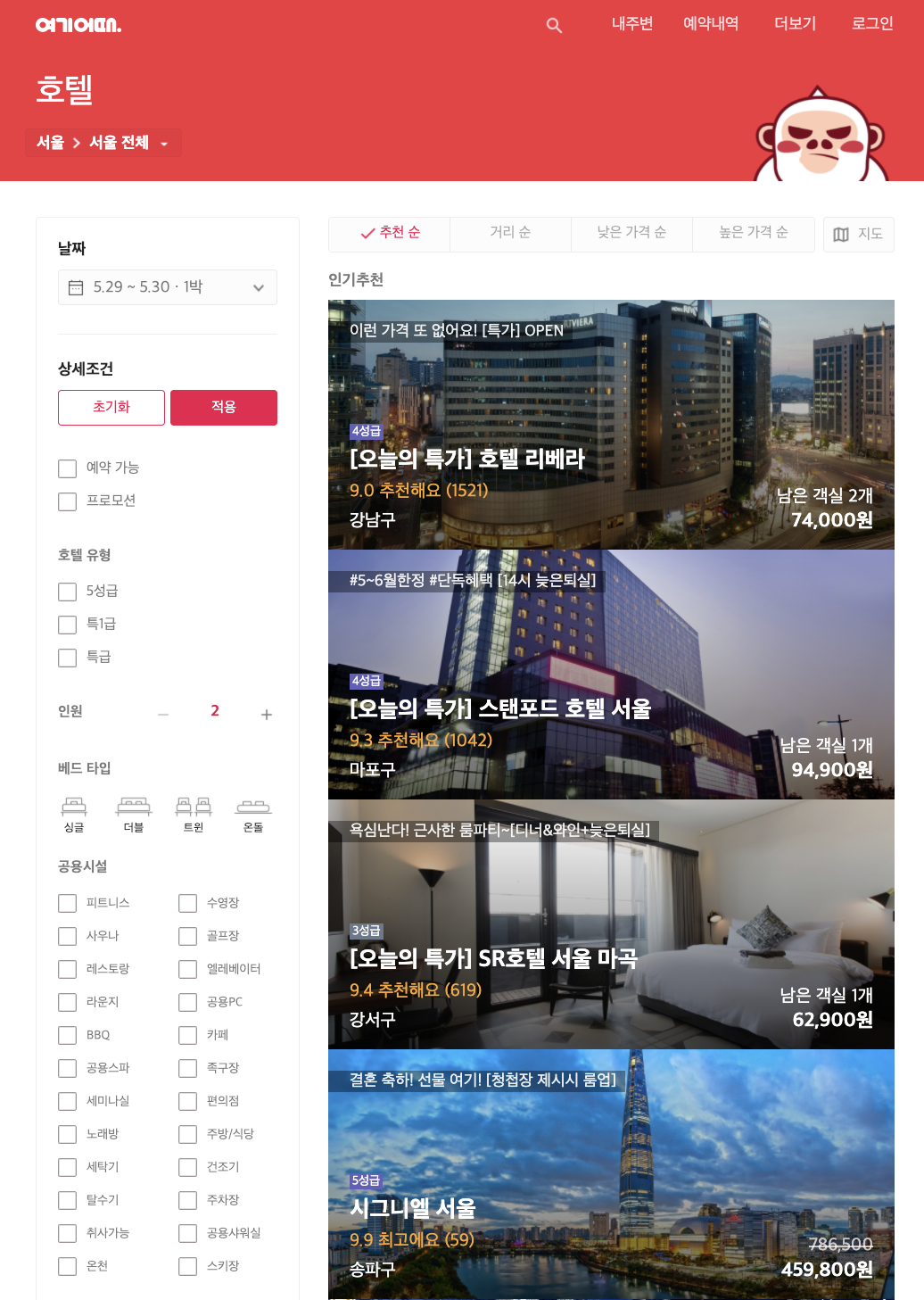
💁♂️ 우리가 만들 프로그램
- 여기어때 호텔 페이지에 접속한다.
- 가져올 호텔 리스트의 HTML 요소(element)를 Selector 로 모두 가져온다.
- 가져온 HTML 요소에서 정보들을 각각 프린트한다.
1. 여기어때 호텔 페이지에 접속한다.
스크립트를 다음과 같이 작성한다.
hotel.js
// puppeteer을 가져온다.
const puppeteer = require('puppeteer');
(async() => {
// 브라우저를 실행한다.
// 옵션으로 headless모드를 끌 수 있다.
const browser = await puppeteer.launch({
headless: false
});
// 새로운 페이지를 연다.
const page = await browser.newPage();
// 페이지의 크기를 설정한다.
await page.setViewport({
width: 1366,
height: 768
});
// "https://www.goodchoice.kr/product/search/2" URL에 접속한다. (여기어때 호텔 페이지)
await page.goto('https://www.goodchoice.kr/product/search/2');
})();터미널에 node hotel.js 명령어를 입력해 프로그램을 실행시켜보자. 그러면 다음과 같이 크롬창이 열리고 여기어때 호텔 페이지에 접속된다.
실행 결과
.png)
2. 가져올 호텔 리스트의 HTML 요소(element)를 Selector 로 가져온다.
가져올 호텔 리스트의 HTML 요소를 Selector로 가져오기 위해선 해당 요소의 Selector를 알아야한다. 구글 크롬 개발자 도구를 사용하면 원하는 HTML 요소의 Selector를 쉽게 가져올 수 있다.
여기어때 호텔 페이지에 접속한 후 F12 를 눌러 구글 크롬 개발자 도구를 열고 알고 싶은 요소위에 마우스를 올려놓고 오른쪽 마우스 클릭 > 검사 를 눌러보면 개발자도구에 해당 HTML 요소가 하이라이트되면서 표시된다.
.png)
가져오고자 하는 리스트 태그(<li>...</li>)의 바로위에 마우스를 올려놓고 오른쪽 마우스 클릭 > Copy > Copy selector 를 해서 해당 요소의 Selector를 쉽게 가져올 수 있다.
.png)
여기서 cheerio 모듈을 사용하면 jQuery 문법을 사용하여 요소의 자식 요소들을 쉽게 가져올 수 있다. cheerio 모듈이 설치되어 있지 않다면 yarn add cheerio 명령어로 cheerio를 설치한다.
hotel.js
//... 생략
// cheerio를 가져온다.
const cheerio = require('cheerio');
(async() => {
//... 생략
// 페이지의 HTML을 가져온다.
const content = await page.content();
// $에 cheerio를 로드한다.
const $ = cheerio.load(content);
// 복사한 리스트의 Selector로 리스트를 모두 가져온다.
const lists = $("#poduct_list_area > li");
// 모든 리스트를 순환한다.
lists.each((index, list) => {
console.log(index);
});
// 브라우저를 종료한다.
browser.close();
})();터미널에 node hotel.js 명령어를 입력해 프로그램을 실행시켜보자. 그러면 li 태그를 모두 가져와서 index를 기록한다. 여기어때의 호텔 페이지에는 총 268개의 호텔 리스트가 있는 것을 확인할 수 있다.
실행 결과
...
266
267
268
jinwook@LAPTOP-J1NEV3JO MINGW64 /d/jw/Study/bot/web-crawling-example
$3. 가져온 HTML 요소에서 정보들을 각각 프린트한다.
이제 호텔 리스트도 가져왔으니 각 호텔의 정보들을 출력해보자. cheerio를 사용하여 쉽게 하위 노드 요소를 가져올 수 있다. 각 호텔의 이름을 가지고와서 출력해보자.
호텔 이름 위에 마우스를 가져다 대고 오른쪽 마우스 클릭 > 검사 를 눌러 요소를 구글 크롬 개발자 도구에서 찾은 후 해당 요소 위에 다시 마우스를 가져다 대고 오른쪽 마우스 클릭 > Copy > Copy selector 를 눌러 호텔 이름 요소의 Selector를 가져온다.
그대로 복사하면 최상위 노드부터의 Selector가 복사되어 li 태그 까지의 노드는 중복되므로 지운다.
.png)
hotel.js
// ... 생략
(async() => {
// ... 생략
// 복사한 리스트의 Selector로 리스트를 모두 가져온다.
const lists = $("#poduct_list_area > li");
// 모든 리스트를 순환한다.
lists.each((index, list) => {
// 각 리스트의 하위 노드중 호텔 이름에 해당하는 요소를 Selector로 가져와 텍스트값을 가져온다.
const name = $(list).find("a > div > div.name > strong").text();
// 인덱스와 함께 로그를 찍는다.
console.log({
index, name
});
});
// 브라우저를 종료한다.
browser.close();
})();실행 결과
...
{ index: 233, name: '신트라 호텔' }
{ index: 234, name: '신림 어반호텔' }
{ index: 235, name: '호텔 디 아티스트 연신내점' }
{ index: 236, name: '은평 씨에스 에비뉴 호텔' }
{ index: 237, name: '불광 포레스타 호텔' }
{ index: 238, name: '천호 바고호텔' }
jinwook@LAPTOP-J1NEV3JO MINGW64 /d/jw/Study/bot/web-crawling-example
$hotel.js 전체 코드
// puppeteer을 가져온다.
const puppeteer = require('puppeteer');
// cheerio를 가져온다.
const cheerio = require('cheerio');
(async() => {
// 브라우저를 실행한다.
// 옵션으로 headless모드를 끌 수 있다.
const browser = await puppeteer.launch({
headless: false
});
// 새로운 페이지를 연다.
const page = await browser.newPage();
// 페이지의 크기를 설정한다.
await page.setViewport({
width: 1366,
height: 768
});
// "https://www.goodchoice.kr/product/search/2" URL에 접속한다. (여기어때 호텔 페이지)
await page.goto('https://www.goodchoice.kr/product/search/2');
// 페이지의 HTML을 가져온다.
const content = await page.content();
// $에 cheerio를 로드한다.
const $ = cheerio.load(content);
// 복사한 리스트의 Selector로 리스트를 모두 가져온다.
const lists = $("#poduct_list_area > li");
// 모든 리스트를 순환한다.
lists.each((index, list) => {
// 각 리스트의 하위 노드중 호텔 이름에 해당하는 요소를 Selector로 가져와 텍스트값을 가져온다.
const name = $(list).find("a > div > div.name > strong").text();
// 인덱스와 함께 로그를 찍는다.
console.log({
index, name
});
});
// 브라우저를 종료한다.
browser.close();
})();마치며
puppeteer 와 cheerio 모듈을 사용하여 여기어때 호텔 페이지에 있는 모든 호텔 리스트의 이름을 크롤링하는데 성공했다. 이제 이 데이터를 2차 가공해서 사용하는 것은 여러분의 몫이다. (물론 함부로 사용하면 감옥에 갈 수 있다) 크롤링이라는 것 자체가 어려워 보였지만 생각보다 단순한 원리로 가능했다.
크롤링을 적절히 잘 이용하면 우리에게 편리한 새로운 서비스를 만들어낼 수도 있고 사람이 해야할 일을 자동화 해줄 수도 있을 것 같다.
다음 시간에는 네이버 블로그에서 특정 검색어로 검색했을 때 내가 쓴 글이 몇 페이지에 나오는지 확인하는 크롤러를 만들어보자.
참고 자료

3개의 댓글

hotel.js 파일 터미널 실행시 cannot find module 'puppeteer' 라고 에러가 뜨는데 어떻게 해결해야할까요?
크롤링 한 데이터를 엑셀에 어떻게 저장하나요 ?