https://research.fb.com/wp-content/uploads/2017/06/imagenet1kin1h5.pdf
Our goal is to use large minibatches in place of small
minibatches while maintaining training and generalization
accuracy.
배치사이즈를 크게 해서 학습속도를 줄이려고 할 때, learning rate를 어떻게 조절해야 하는지 알아보자
-
Linear Scaling Rule
- batchsize가 k배 커지면 learning rate (lr)을 k배 크게 하고
- k*lr 도달 시점까지 warmup을 적용하면
- 기존과 동일한 수준의 generalization accuracy (test accuracy) 를 유지할 수 있음
- batchsize가 커지므로 학습시간은 단축됨 -
Batch Normalization Rule
-
Initializing γ = 0 in the last BN layer of each residual block improves results for both small and largeminibatches
-
residual block 의 마지막 파트의 BN γ 를 0으로 셋팅하면 large minibatch에서 성능 향상에 도움이 된다
-
-
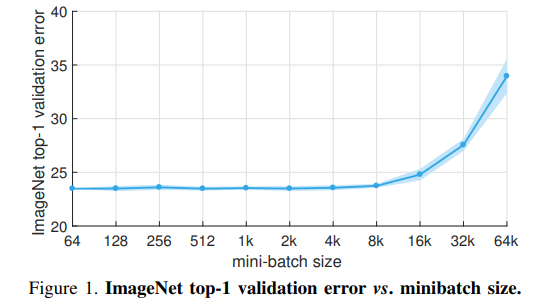
linear scaling rule 에 따라 학습한 결과, 8k 수준의 batchsize에서 동일한 성능을 얻음
