paper review
1.Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
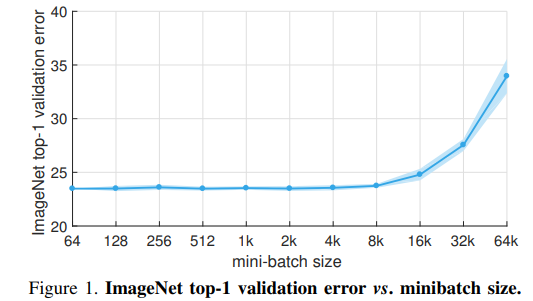
https://research.fb.com/wp-content/uploads/2017/06/imagenet1kin1h5.pdfOur goal is to use large minibatches in place of smallminibatches while mai
2020년 10월 20일
2.ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA
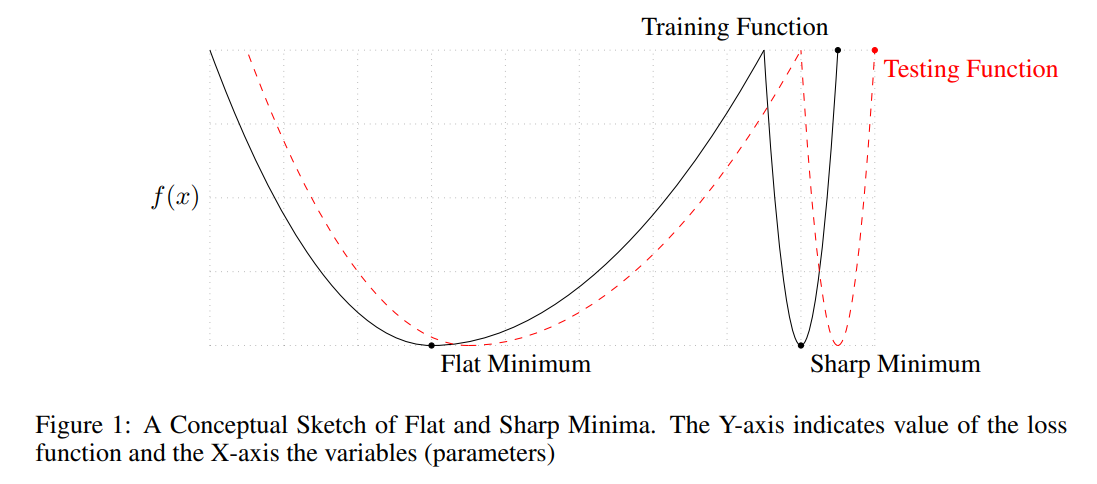
small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to theinherent noise i
2020년 10월 20일
3.GRAPH ATTENTION NETWORKS

논문 링크그래프 형태의 데이터에 attention 메커니즘을 적용하는 모델이다attention mechanism 트랜스포머처럼 내적으로 계산하지는 않고, feed-forward neural network 이라고 볼 수 있다. weight matrix 를 노드의 임베딩
2020년 12월 30일