분류 알고리즘 (Classification)
설명변수를 바탕으로 목표 변수가 가질 수 있는 여러 범주 중 하나를 예측하는 지도학습의 대표적인 방법
- KNN (K-Nearest Neighbors)
핵심 개념: 주변의 '가까운' 데이터를 기준으로 분류
방식:
- 새로운 데이터 포인트가 들어왔을 때, 학습 데이터 중에서 가장 가까운 K개의 데이터를 찾음
- 이 K개 중 다수의 클래스가 새로운 데이터의 클래스가 됨 -> 다수결 튜표 방식
특징
- 장점: 구현이 간단, 이상치에 비교적 강함, 이상치가 있어도 그 값에 크게 영향을 받지 않음
- 단점: 데이터가 많거나 차원이 높아지면 성능 저하
# 속성 변수 선택
X = ndf[['pclass','age','sibsp','parch','female','male','town_C','town_Q','town_S']] # 설명변수 X
y = ndf[['survived']] # 예측 변수 y
# 데이터 전처리 도구들을 모아둔 모듈 preprocessing을 불러옴
# StandardScaler: 표준화(standardization)를 수행하는 도구
# 왜 표준화를 할까? K-Means, SVM, KNN, PCA 같은 알고리즘은 거리 기반 계산을 하기 때문에, 특성들의 스케일이 다르면 성능이 나빠질 수 있음
# fit(X): X의 평균과 표준편차를 계산
# transform(X): 위 통계를 사용해서 실제로 데이터를 변환
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# train data와 test data를 7:3으로 구분
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
print('train data 개수:', X_train.shape)
print('test data 개수:', X_test.shape)
# sklearn 라이브러리에서 KNN 분류 모형 가져오기
from sklearn.neighbors import KNeighborsClassifier
# 모형 객체 생성 (k=5로 설정)
# 가장 가까운 이웃 5개를 사용하겠다. 보통 k는 홀수로 지정. 짝수로 지정할 경우 동점이 될 수 있음
knn = KNeighborsClassifier(n_neighbors=5)
# train data를 가지고 모형 학습
knn.fit(X_train, y_train)
# test data를 가지고 y_hat 예측(분류)
y_hat = knn.predict(X_test) # y_hat: 예측된 값
print(y_hat[0:10]) # 예측된 값 10개
print(y_test.values[0:10]) # 실제 정답 10개
# 모형 성능 평가 - Confusion Matrix 계산
from sklearn import metrics
knn_matrix = metrics.confusion_matrix(y_test, y_hat)
print(knn_matrix)
# Confusion Matrix 시각화
# annot=True: 각 셀에 숫자값(정수)을 표시
# fmt='d': 포맷 정수로 입력
plt.figure(figsize=(8, 6))
sns.heatmap(knn_matrix, annot=True, fmt='d', cmap='Blues',
xticklabels=['Negative', 'Positive'],
yticklabels=['Negative', 'Positive'])
plt.title('Confusion Matrix')
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.show()
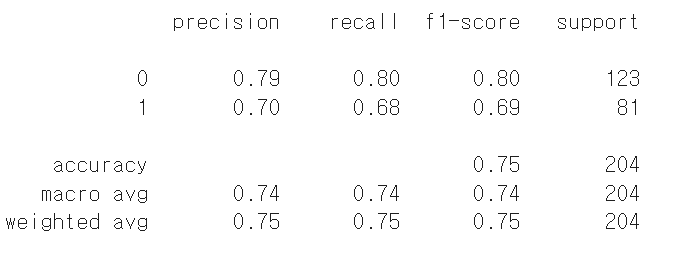
# 모형 성능 평가 - 평가지표 계산
knn_report = metrics.classification_report(y_test,y_hat)
print(knn_report)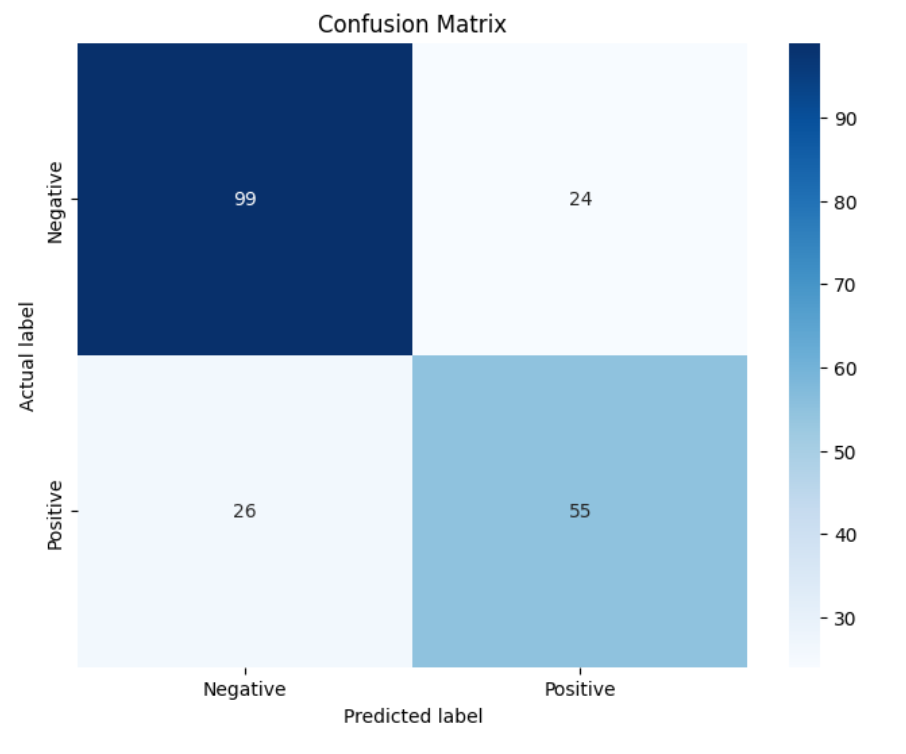
- SVM (Support Vector Machine)
핵심 개념: 클래스 간 최대한 margin을 가능한 한 넓게 벌려서 데이터를 나누는 방법 -> Test data가 그 경계선의 어느 쪽에 있는지 분류하는 알고리즘
방식
- 데이터를 선형 또는 비선형적으로 분리할 수 있는 초평면 찾음
- 가장 가까운 데이터 포인트와의 거리를 최대화하도록 설계
특징
- 장점: 고차원 데이터에 강함 -> 텍스트 분류 (뉴스, 이메일) 등에 강함
- 단점: 대용량 데이터에 느림
- Decision Tree (의사결정나무)
핵심 개념: 데이터 특징을 기준으로 질문을 반복하며 나무 구조로 분기
방식
- 각 노드에서 특정 feature을 기준으로 데이터 분할
- 잎 노드에 최종 클래스 값이 위치
특징
- 장점: 비정형 데이터에서 사용 가능, 전처리 적음
- 단점: 분할을 너무 세세하게 하기 때문에 과적합 우려
# 특성 중요도 계산
features = pd.DataFrame(tree_model.feature_importances_,
index=train_features,
columns=['Importance'])
features = features.sort_values(by='Importance', ascending=False)
features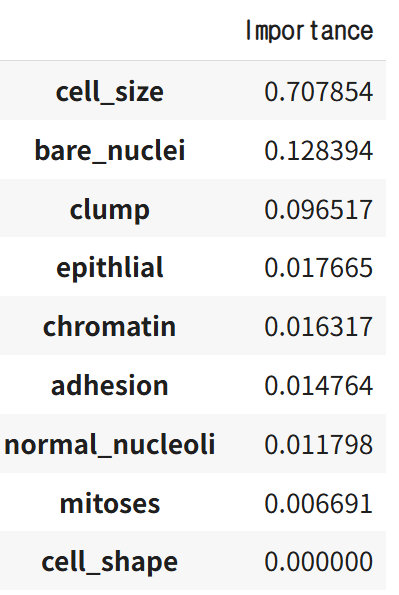
Confusion Matrix와 모델 성능 평가
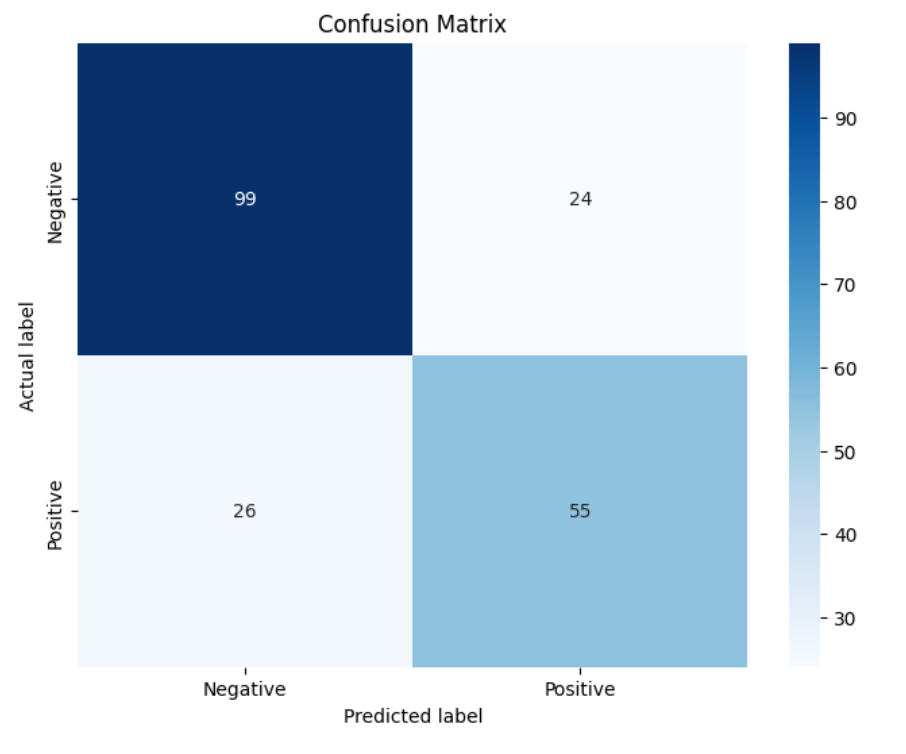
False Positive (FP) = 24: 실제로는 Negative인데 Positive로 잘못 예측 -> 잘못된 경고/오탐
False Negative (FN) = 26: 실제로는 Positive인데 Negative로 잘못 예측 -> 놓친 탐지/누락
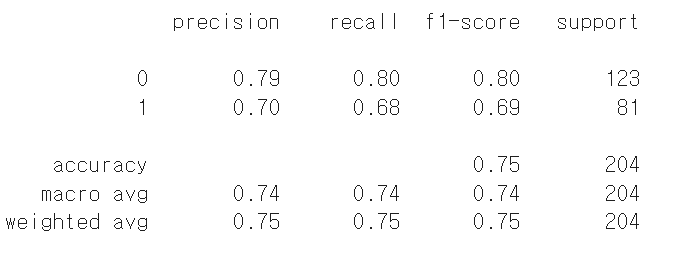
📌 Precision (정밀도)
양성이라고 예측한 것 중 실제로 양성인 비율
클래스 0: 0.79 → 예측한 Negative 중 79%가 실제로 Negative
클래스 1: 0.70 → 예측한 Positive 중 70%가 실제로 Positive
📌 Recall (재현율)
실제 양성 중에서 모델이 양성으로 잘 맞춘 비율
클래스 0: 0.80 → 실제 Negative 중 80%를 정확히 Negative로 예측
클래스 1: 0.68 → 실제 Positive 중 68%만을 Positive로 예측 (False Negative 존재)
따라서,
FN 비용이 큰 문제라면 → Recall 향상 필요
FP 비용이 큰 문제라면 → Precision 향상 필요
