데이터 분리(Train-Test Split)와 모델 평가(오차행렬)
1. Train-Test Split (훈련/테스트 데이터 분할)
필요성
모델을 학습시킬 때, 가지고 있는 모든 데이터를 공부(학습)하는 데 써버리게 되면 모델이 이미 답을 외워버렸기 때문에 항상 정답을 말한다.
but 처음 보는 새로운 데이터를 만나면 엉망이 됨.
- 목적: 모델이 보지 못한 데이터에 대해 얼마나 잘 작동하는지(일반화 성능) 평가하기 위함
- 핵심: 과적합(Overfitting) 방지
사용 방법 (train_test_split)
- Scikit-learn의
model_selection모듈 사용
from sklearn.model_selection import train_test_split
# 기본 사용법
X_train, X_test, y_train, y_test = train_test_split(
X, # 특성 데이터 (Feature)
y, # 정답 데이터 (Label)
test_size=0.3, # 테스트 데이터 비율 (30%)
random_state=42, # 난수 시드 (매번 똑같이 섞이도록)
stratify=y # ⭐ 분류 문제 필수 옵션!
)중요:
stratify옵션
의미: 층화 추출. 정답 데이터()의 클래스 비율(정답 비율)을 유지하며 나눈다.
Why?
만약 암 환자 데이터가 전체의 5%밖에 없는데, 막 나누다가 학습 데이터에 암 환자가 한 명도 안 들어간다면? 모델은 학습을 제대로 할 수 없다. 분류 문제에서는 stratify=y를 꼭 써주는 것이 좋다.
2. 실습: Pima Indians Diabetes 데이터 분할
1) 데이터 준비 및 분할
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 데이터 로드
df = pd.read_csv('data/pima-indians-diabetes.data.csv')
# 특성(X)과 라벨(y) 분리
# .values를 써서 Numpy Array 형태로 변환
x_data = df.iloc[:, :-1].values
y_data = df.iloc[:, -1].values
# 데이터 분할 (7:3 비율)
# 반환되는 4개의 배열을 언패킹(Unpacking)으로 받음
x_train, x_test, y_train, y_test = train_test_split(
x_data, y_data,
test_size=0.3,
stratify=y_data # 정답 비율 유지
)
# 차원(Shape) 확인
print(f"학습 데이터: {x_train.shape}")
# (537, 8)
print(f"테스트 데이터: {y_test.shape}")
# (231,) -> 전체 768개의 약 30%2) 모델 학습 및 평가 (Accuracy)
로지스틱 회귀 모델을 학습시키고 점수를 확인해자.
- 회귀 모델의 score: 결정계수()
- 분류 모델의 score: 정확도(Accuracy)
# 모델 생성 및 학습
model = LogisticRegression(max_iter=500, verbose=True)
model.fit(x_train, y_train)
# 1. 학습 데이터 점수 (Train Score)
train_score = model.score(x_train, y_train)
print(f"Train Accuracy: {train_score}")
# 결과: 0.782... (약 78.2%)
# 2. 테스트 데이터 점수 (Test Score)
test_score = model.score(x_test, y_test)
print(f"Test Accuracy: {test_score}")
# 결과: 0.774... (약 77.4%)과적합(Overfitting) vs 과소적합(Underfitting) 판별
- 학습 점수와 테스트 점수의 차이를 보고 모델 상태를 진단
| 상태 | 점수 비교 | 설명 | 해결 방안 |
|---|---|---|---|
| 과적합 (Overfitting) | Train ≫ Test | 공부만 너무 잘하고 응용을 못함 | 데이터 추가, 규제(Regularization), 학습량 줄이기 |
| 과소적합 (Underfitting) | Test > Train | 공부를 덜 해서 둘 다 못 맞춤 | 학습 반복(Epoch) 늘리기, 모델 복잡도 높이기 |
| 이상적 | Train ≈ Test | 둘 다 적절히 높음 | Good! |
위 실습 결과는 78.2% vs 77.4%로 차이가 크지 않아 일반화가 잘 된 상태라고 볼 수 있다.
3. 혼동 행렬 (Confusion Matrix)
- 정확도(Accuracy)만으로는 '어떻게' 틀렸는지 알 수 없다. 암 환자를 정상으로 예측한 건지(위험!), 정상을 암 환자로 예측한 건지(해프닝) 구별해야한다.
1) 구조 이해
- TN (True Negative): 아닌 것을 아니라고 잘 맞춤 (정탐)
- FP (False Positive): 아닌데 맞다고 잘못 예측 (오탐)
- FN (False Negative): 맞는데 아니라고 잘못 예측 (미탐 - 가장 위험할 수 있음)
- TP (True Positive): 맞는 것을 맞다고 잘 맞춤 (정탐)
2) Scikit-learn 실습
from sklearn.metrics import confusion_matrix
# 학습 데이터에 대한 예측값 생성
pred_train = model.predict(x_train)
# confusion_matrix(실제값, 예측값)
cm = confusion_matrix(y_train, pred_train)
print(cm)
# 결과
# [[312, 38], -> 실제 0(정상)인 데이터: 312개 맞춤 / 38개 틀림
# [ 79, 108]] -> 실제 1(당뇨)인 데이터: 79개 틀림 / 108개 맞춤4. 시각화: 히트맵 (Heatmap)
- 숫자로 보는 것보다 Seaborn 라이브러리의 히트맵을 그리면 훨씬 직관적으로 확인할 수 있다.
Train 데이터 히트맵
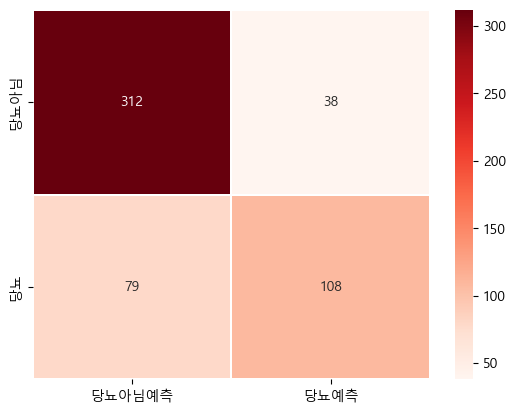
import seaborn as sb
import matplotlib.pyplot as plt
# 한글 폰트 설정
matplotlib.rcParams['font.family']='Malgun Gothic'
sb.heatmap(
cm,
annot=True, # 숫자 표시 여부
fmt='d', # 정수(decimal)로 표시 (안 쓰면 지수 형태 3.1e+2 로 나옴)
linewidths=0.2, # 칸 사이 간격
cmap='Reds', # 색상 테마
xticklabels=['당뇨아님(예측)', '당뇨(예측)'],
yticklabels=['당뇨아님(실제)', '당뇨(실제)']
)
plt.title("Train Confusion Matrix")
plt.show()Test 데이터 히트맵
- 테스트 데이터
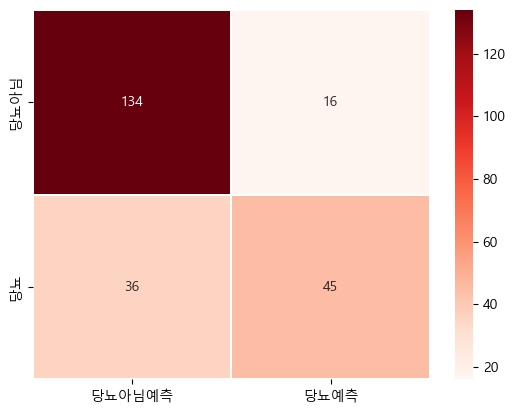
pred_test = model.predict(x_test)
cm_test = confusion_matrix(y_test, pred_test)
sb.heatmap(
cm_test,
annot=True,
fmt='d',
linewidths=0.2,
cmap='Reds',
xticklabels=['당뇨아님(예측)', '당뇨(예측)'],
yticklabels=['당뇨아님(실제)', '당뇨(실제)']
)
plt.title("Test Confusion Matrix")
plt.show()상관관계 확인
- 데이터의 품질이나 특성 간의 관계를 볼 때 유용하다.
# df.corr(): 컬럼 간의 상관계수를 반환 (-1 ~ 1)
print(df.corr())- 상관관계가 낮게 나온다면?
데이터 전처리가 더 필요하거나, 데이터 품질이 낮아 모델 성능을 올리기 어려울 수 있음을 시사.
요약
- Train-Test Split: 데이터를 쪼개서 과적합을 방지하고 성능을 객관적으로 평가한다.
- Stratify: 분류 문제에서는 정답 비율을 맞춰서 나누는 것이 필수다.
- Confusion Matrix: 정확도 너머, 모델이 어떤 유형의 오류를 범하는지(FP, FN) 파악할 수 있다.
- Heatmap: 혼동 행렬을 시각화하여 분석하기 좋게 만든다.
소금에 절인 생선, 몸을 뒤척이다 🐟