로지스틱 회귀 (Logistic Regression)와 시그모이드
만약 우리가 예측해야 하는 것이 숫자가 아니라 "합격/불합격" 같은 범주일 때도 선형 회귀를 쓸 수 있을까? 대답은 No 그럼 어떻게 해야할까?
1. 왜 선형 회귀로는 안 될까?
공부 시간()에 따른 합격 여부()를 예측한다고 가정해 보자.
- 합격 = 1
- 불합격 = 0
선형 회귀(Linear Regression)로 직선을 그으면 문제가 발생한다.
- 범위 초과: 직선은 끝없이 뻗어나가므로 0보다 작거나 1보다 큰 값이 나옴.
(확률은 0~1 사이여야 함) - 기준 모호: 를 기준으로 나눈다 해도, 데이터에 민감하게 반응하여 기준이 쉽게 흔들린다.
"직선 대신 S자 곡선으로 0과 1 사이의 확률을 예측하자!"
로지스틱 회귀
2. 핵심 함수: 시그모이드 (Sigmoid)
선형 회귀의 예측값()을 0과 1 사이의 확률값으로 변환해주는 함수
시그모이드 함수 정의
-
-
(선형회귀 값)가 아무리 커져도 1에 수렴.
-
가 아무리 작아져도 0에 수렴.
-
일 때 정확히 0.5
시그모이드 시각화 실습
import numpy as np
import math
import matplotlib.pyplot as plt
# 시그모이드 함수 정의
def sigmoid(z):
return 1 / (1 + math.e ** -z)
# z값 준비 (-10 ~ 10 사이)
z = np.linspace(-10, 10, 50)
s = sigmoid(z)
# 시각화
plt.plot(z, s, 'r-')
plt.axvline(0, color='k', linestyle=':') # x=0 기준선
plt.grid(True)
plt.title("Sigmoid Function")
plt.xlabel("z (wx + b)")
plt.ylabel("Probability")
plt.show()
# 주요 값 확인
print(f"z=-10 : {sigmoid(-10)}") # 0에 근접
print(f"z= 0 : {sigmoid(0)}") # 0.5
print(f"z= 10 : {sigmoid(10)}") # 1에 근접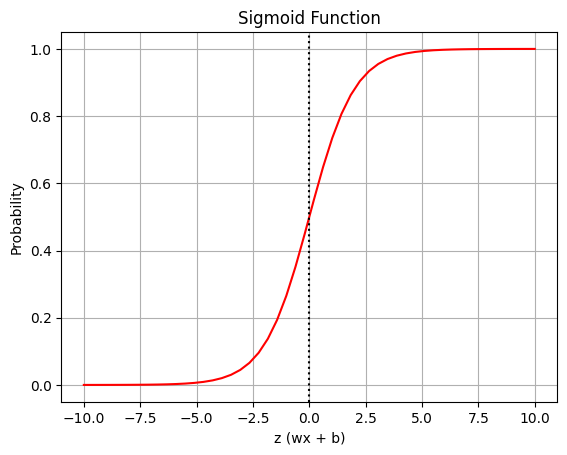
3. 로지스틱 회귀의 수학적 배경 (Odds & Logit)
1) Odds (승산) (통계적 개념)
성공 확률()이 실패 확률()보다 몇 배 더 높은가?
2) Logit (로짓)
Odds에 자연로그()를 취한 값입니다.
- 확률 는 0~1 사이지만, Logit 값은 (음수, 양수 모두 가능) 범위를 가진다.
- 즉, 우리가 아는 선형 회귀()의 결과값()을 Logit이라고 볼 수 있다.
3) 역함수 관계 (Logit Sigmoid)
-
Logit 식을 다시 에 대해 정리하면 우리가 본 시그모이드 함수가 나온다.
-
-
결국 로지스틱 회귀는 "선형 회귀 값을 시그모이드에 넣어 확률을 구하는 것"
4. 예제: 피마 인디언 당뇨병 예측 (Scikit-learn)
Scikit-learn에서는
LogisticRegression클래스를 사용한다.
이름은 'Regression(회귀)'이지만 실제로는 'Classification(분류)' 모델
1) 데이터 준비 및 학습
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
# 데이터 로드
df = pd.read_csv('data/pima-indians-diabetes.data.csv')
# 독립변수(X)와 종속변수(y) 분리
# 마지막 열이 당뇨병 발병 여부(0 또는 1)
x_data = df.iloc[:, :-1]
y_data = df.iloc[:, -1]
# 모델 생성 및 학습
# max_iter: 계산 반복 횟수 (수렴하지 않으면 늘려줘야 함)
model = LogisticRegression(max_iter=500, verbose=True)
model.fit(x_data, y_data)2) 학습 결과 확인 (가중치와 절편)
print("가중치(w):", model.coef_)
# 특성이 8개이므로 w도 8개가 나옴 (8x1 행렬)
print("절편(b):", model.intercept_)
# 편향값 (1개)3) 예측하기: predict vs predict_proba
분류 모델은 두 가지 예측 메서드를 제공한다
predict(X): 0 또는 1 (최종 클래스) 예측
predict_proba(X):[0일 확률, 1일 확률]예측
# 예제 데이터 2건
# (임신횟수, 포도당, 혈압, 피부두께, 인슐린, BMI, 당뇨내력, 나이)
sample_data = [
[6, 148, 72, 35, 0, 33.6, 0.627, 50],
[1, 93, 70, 31, 0, 30.4, 0.315, 23]
]
# 1. 최종 결과 예측 (0 or 1)
print(model.predict(sample_data))
# 결과: array([1, 0]) -> 첫 번째는 당뇨(1), 두 번째는 정상(0)
# 2. 확률 예측
print(model.predict_proba(sample_data))
# 결과 예시:
# [[0.28, 0.72], -> 1일 확률이 0.72라 1로 예측
# [0.85, 0.15]] -> 0일 확률이 0.85라 0으로 예측5. 검증: 직접 계산해보기 (Logic Check)
predict_proba가 내부적으로 어떻게 작동하는지, 앞서 배운 수식( 후 시그모이드)으로 직접 검증하기
import math
# 시그모이드 함수
def sigmoid(z):
return 1 / (1 + math.e ** -z)
# 첫 번째 샘플 데이터 가져오기 (2차원 배열 유지)
xn = np.array([sample_data[0]])
# 1단계: 선형 회귀 값 (z) 계산
# z = X @ W.T + b (행렬 곱)
# model.coef_는 (1, 8) 형태이므로 Transpose(.T) 해주거나 맞춰서 곱해야 함
z = np.matmul(xn, model.coef_.T) + model.intercept_
# 2단계: 시그모이드 통과 (확률 p 계산)
prob = sigmoid(z)
print(f"직접 계산한 확률: {prob}")
print(f"라이브러리 결과: {model.predict_proba(xn)[0][1]}")
# 3단계: 0.5 기준으로 분류
prediction = 1 if prob > 0.5 else 0
print(f"최종 예측 클래스: {prediction}")- 결론 : 직접 계산한 값과 사이킷런의 결과가 정확히 일치함을 볼 수 있다.
요약
-
로지스틱 회귀는 이진 분류(0 or 1)를 위한 모델이다.
-
선형 회귀의 결과()를 시그모이드 함수에 넣어 0~1 사이의 확률()로 변환한다.
-
Odds(승산)와 Logit(로짓) 개념이 바탕이 된다.
-
Scikit-learn의 predict_proba를 통해 확률을 확인할 수 있다.
소금에 절인 생선, 몸을 뒤척이다 🐟