Abstract
Person Re-ID는 겹치지 않는 다중 카메라에서 person을 검색하는 것이다. 본 논문에서는 closed-world setting과 open-world setting으로 나누어 설명한다.
closed-world는 많은 연구가 되면서 여러 기술과 많은 데이터셋으로 성공을 거뒀다.
포괄적으로 3가지 측면으로 다룬다.
1) deep feature representation learning
2) deep metric learning
3) ranking optimization
open-world는 더 많은 도전 과제가 있는데 5가지 측면으로 요약한다.(본 논문에서 할것)
0) 존재하는 방법의 장점들을 분석한다.
1) powerful AGW baseline을 디자인하고
2) 12개의 datasets으로 4가지의 다른 Re-ID task를 달성한다.
3) person ReID에서 새로운 평가 metric인 mINP를 다룬다.
4) 중요한 미해결 문제들을 다룬다.
Introduction
Person Re-ID는 non-overlapping cameras에서 특정한 인물을 검색하는 문제롤 많이 연구됐다. 다른 장소, 다른 시간에 나타나는 지를 결정하는 것인데, 쿼리 인물은 이미지, 비디오 sequence, text 묘사로도 표현될 수 있다.
Re-ID의 도전 과제
different viewpoints, varying low-image resolution, illumination change, different poses, occlusions, heterogeneous modalities(이질적인 모달리티(정보 인코딩 방식)), complex camera environments, background clutter, unreliable bounding box generations, the dynamic updated camera network, large scale gallery with efficient retrieval, group uncertainty, significant domain shift, unseen testing scenarios, incremental model updating, changing cloths 등이 있다.
초기 연구
주로 신체 구조를 사용한 handcrafted feature construction이나 distance metric learning에 중점을 두었으나 연구 지향적인 시나리오와 실제는 여전히 큰 격차가 있었다. 그래서 본 논문에서는 포괄적인 조사를 하고, 다양한 Re-ID 작업에 대한 powerful baseline을 개발하고 여러 미래의 방향성에 대해 논의한다.
차별점
1) 현재 방법들을 분석해서 장점과 한계를 논의한다.
2) new powerful baseline (AGW: Attention Generalized mean pooling with Weighted triplet loss)를 제시한다.
3) new evaluation metric (mINP: mean Inverse Negative Penalty) 제시
4) closed-world application과 open-world application의 간극을 좁히기 위해서 미해결된 연구 방향을 논의한다.
일반적인 Re-ID system
1) Raw Data Collection: 카메라로 영상 수집
2) Bounding Box Generation: detection or tracking algorithms 이용
3) Training Data Annotation
4) Model Training: labeling이 안된 data로 training
5) Pedestrian Retrieval: query랑 gallery set을 주고 feature 추출, retrieved ranking도 작업에 포함되어 있다.
Closed vs Open
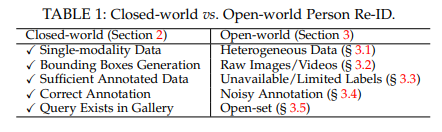
위 표는 두 개를 비교해서 요약해놓은 것이다.
1) Single-modality vs Heterogeneous Data: closed-world에서는 카메라 영상만 활용한다. open-world에서는 적외선 이미지, 스케치, depth image나 텍스트 묘사같은 hterogeneous data가 필요하다.
2) Bounding Box Generation vs Raw Images/Videos: closed-world에서는 생성된 바운딩 박스를 기반으로 훈련과 테스트를 하고, 박스는 인물의 외모 정보를 주로 담는다. open-world에서는 raw 이미지나 비디오에서 end-to-end person search를 필요로 한다.
3) Sufficient Annotated Data vs Unavailable/Limited Labels: closed-world에서는 충분한 annotated 데이터가 있다고 가정하지만, open-world에서는 라벨링된 데이터가 시간과 비용이 많이 든다. 그래서 라벨이 부족하거나 정보가 아예 없을 수 있다.
4) Correct Annotation vs Noisy Annotation: closed-world에서는 정확한 라벨을 가지고 있지만 보통 open-world에서는 detection/tracking의 결과가 불완전하더나 라벨에 오류가 있을 수 있다.
5) Query Exists in Gallery vs Open-set: pedestrian retrieval 단계에서 closed-world는 쿼리가 gallery set에 존재한다. 하지만 많은 open-world에서는 쿼리의 인물이 gallery set에 존재하지 않을 수 있고, retrieval이 아닌 검증을 해야할 수 있다.
Closed-world Person Re-Identification
Feature Representation Learning
탐지된 사람의 bounding box에 대해서 Feature를 어떻게 추출할 것인지? 사람의 포즈나 보는 각도, 방향, 카메라 등이 변해도 같은 Feature가 나오도록 하는 방법을 설명한다.
- Global Feature Representation Learning
각 인물에 대해 global feature vector 추출(전체 body 이미지로부터 feature를 뽑아낸다.)
이전 연구들에서 자주 쓰임
single-image representation과 cross-image representation으로 구성된 joint learning framework이 개발됐다. 이것은 특정 서브 네트워크를 사용한 triplet loss로 훈련되었다. IDE 모델은 각 신원을 별도의 클래스로 간주해서 학습 과정을 다중 클래스 분류 문제로 구성한다.
Attention Information는 feature 향상을 위해서(좀더 의미있는 정보추출) 사용된다.
Group 1: 인물 이미지 내의 attention
정렬 오류, 불완전한 탐지에 대한 견고함을 향상시킨다.
the pixel level attention, the channel-wise feature response re-weighting, background suppressing, the spatial information이 주된 전략으로 사용된다.
Group 2: 여러 인물 이미지 간의 attention
여러 이미지 간의 관계를 학습하여 feature learning을 개선한다.
a context-aware attentive feature learning method, an intra-sequence and inter-sequence attention, the attention consistency property, group similarity
-
Local Feature Representation Learning
크게 human parsing/pose detection(Group 1)을 이용하는 프레임워크, horizontal-divided region features(Group 2)를 사용하는 것이 있다. 첫번째는 잘 정렬된 부분 feature를 얻을 수 있지만(성능이 좋다) pose detection을 위한 추가적인 리소스가 필요하고 이 detector도 완벽하지 않아서 노이즈가 있는 포즈 탐지에 취약하다. 후자는 더 flexible하지만 occlusion, background clutter의 variation에 취약하다. -
Auxiliary Feature Representation Learning = 추가 데이터를 활용한 Feature Learning = 아래의 방법으로 모두 좀 더 좋은 성능의 the feature representation를 추출할 수 있었다.
- Semantic Attributes
[정리]