졸프 모델 개발과 빅데이터분석경진대회에 앞서 관련 개념들을 리마인드해보고자 그동안 배운 내용들을 정리해보려 한다!
Machine Learning
💡 기계학습(Machine learning)
스스로 경험을 통해 성능을 향상시키는 컴퓨터 알고리즘
The study of computer algorithms that improve automatically through experience (by Tom Mitchell)
- 딥러닝은 인공지능의 하위분야
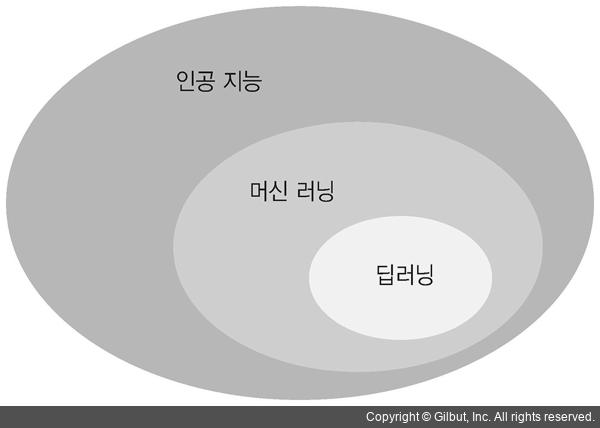
1. Supervised Learning (지도학습)
input-output pairs가 주어짐Classification: 이산적 (discrete)Regression: 연속적 (continuous)
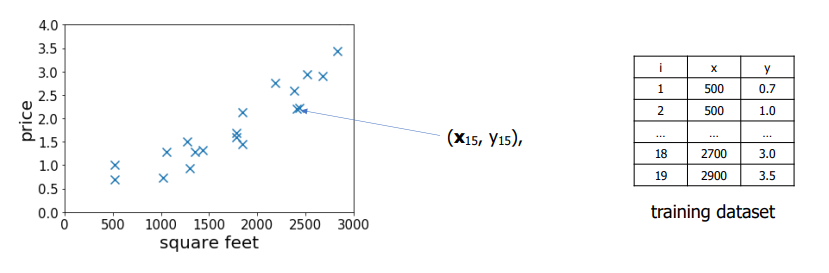
Housing price prediction
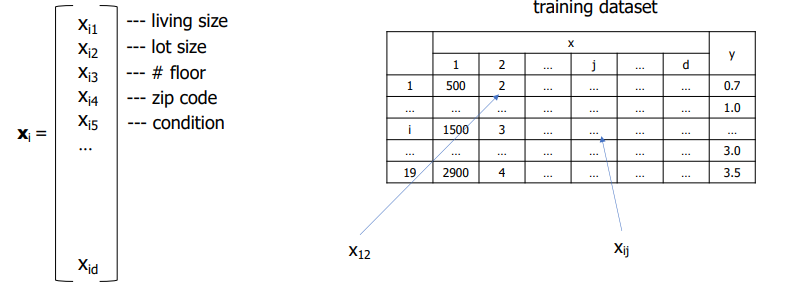
- : training dataset
- : feature
- : label / target
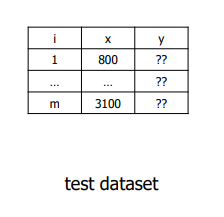
- x = 800이라면 y = ?
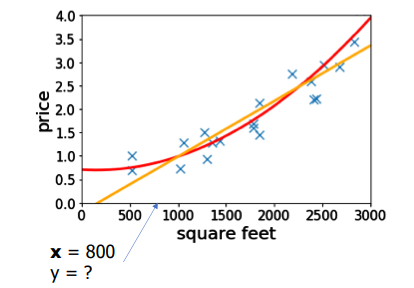
- 적합한
model기준으로 학습
-
feature가 더 늘어난다면?
- = (size, lot size)
-
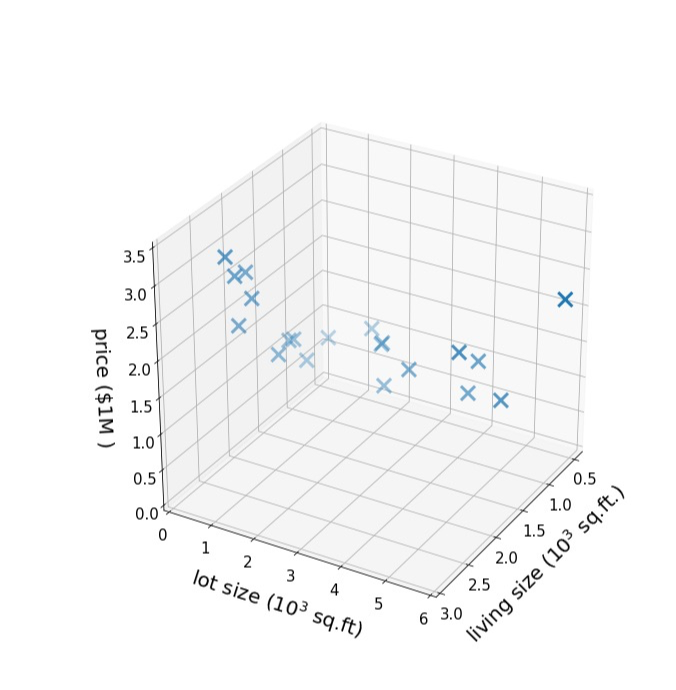
-
High-dimensional features (고차원)
d-dimensional vector
RegressionvsClassification
Regression 회귀는 label이 연속적!
Classification 분류는 label이 이산적!
Supervised Learning in Computer Vision
- Image classification
- x = raw pixels of the image
- y = the main object

- Object localization and detection
- x = raw pixels of the image
- y = the bounding boxes

- Machine translation

2. Unsupervised Learning (비지도 학습)
-
no labels!!! output 정보가 없음
-
정보만 주어짐
-
Clustering, Compression(압축), Density estimation, Dimension reduction
-
clustering- 그룹화, 군집화
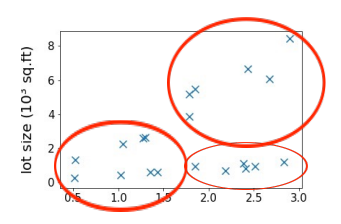
-
Dimension reduction (차원 축소)
차원이 높을수록 데이터의 양도 증가
⇒ 필요 없는 input 데이터 삭제
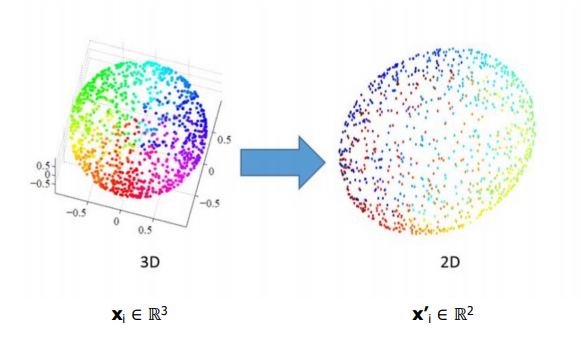
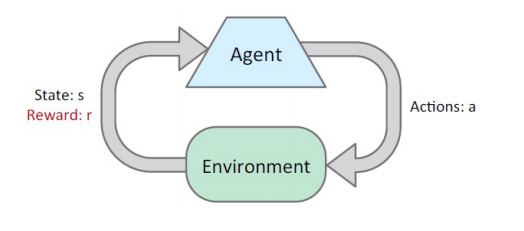
3. Reinforcement Learning (강화 학습)
- Input +
reward rewards의 형태로 피드백 받음- 예상되는 rewards를 최대화하기 위해 학습!
- 모든 학습은 결과의 sample에 기초
Example: Atari games
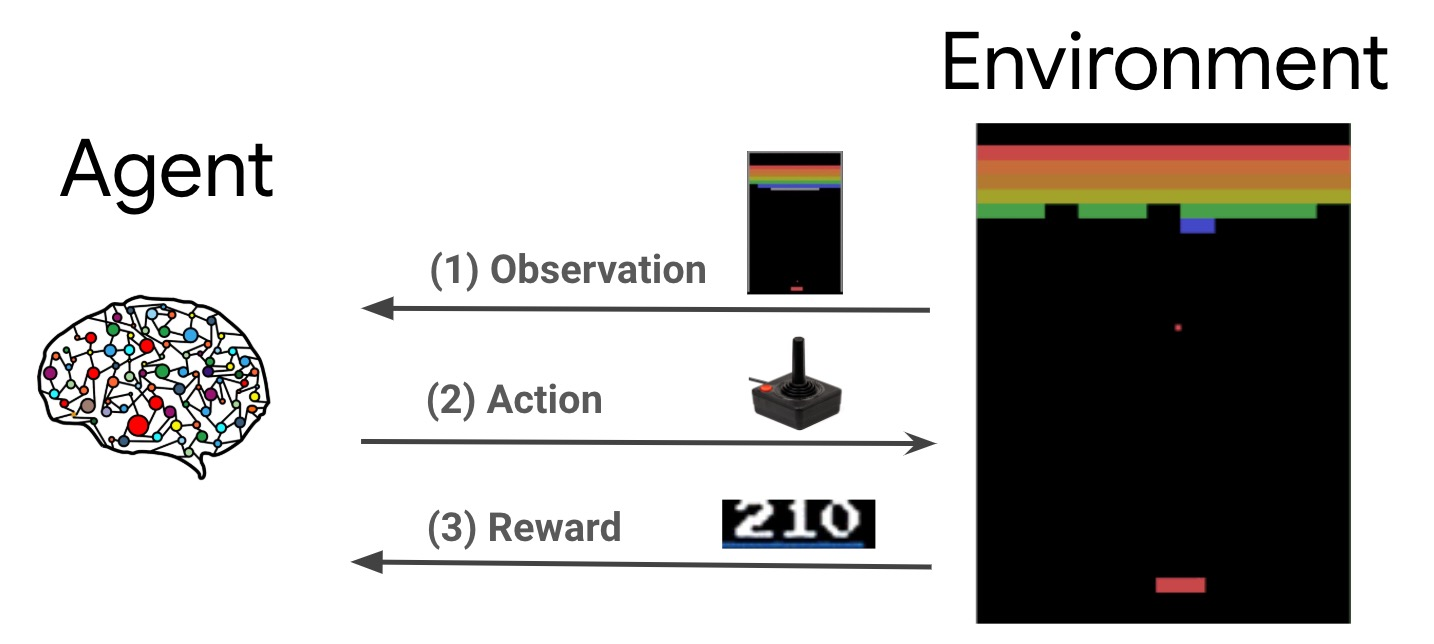
1. 목표 : 가장 높은 점수로 게임 완료
2. State : game state의 raw pixel inputs
3. Action : game control (e.g. Left, Right, Up, Down)
4. Reward : 각 단계별 점수 증가 / 감소
Example : Go

1. 목표 : 게임에서 이기기
2. State : 모든 pieces의 위치
3. Action : 다음 piece를 놓을 위치
4. Reward : 경기가 끝날 때 이기면 1, 그렇지 않으면 0
