선형 회귀
-
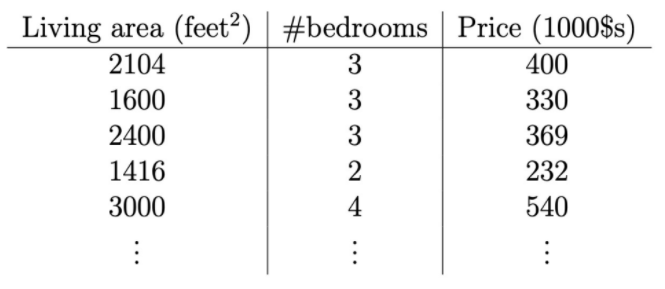
dataset : 47개의 집에 대한
living area,number of bedrooms,price -
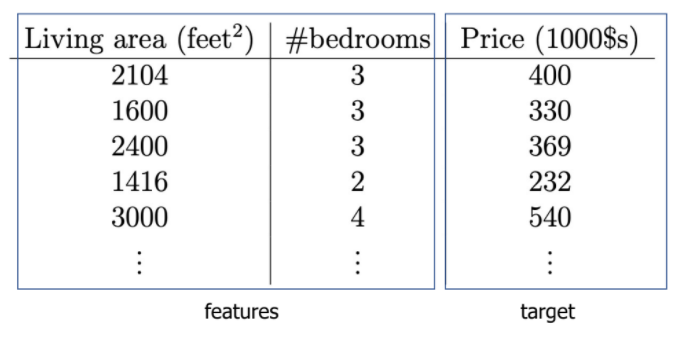
feature :
living area,number of bedrooms -
target :
price -
우리는 다른 집들에 대한
Price를 예측하도록 학습할 수 있을까?
living area: 3500,number of bedrooms: 5, Price: ??
-
: training dataset(학습 데이터)가 주어지면 이걸로 function 찾기
-
scatter plot(산점도)
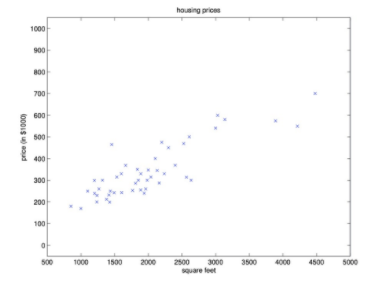
상관관계를 직관적으로 볼 수 있음
Linear function
-
y를x의 linear function으로 근사 -
x가 2차원 벡터일 때,
-
: parameters (weights),
w로 표현하기도 함 -
파라미터에 따라 값이 달라지므로
θ를 잘 찾아야 함 -
θ,x: vector -
d: input 수 -
Learning, 학습한다 = 주어진 data로부터 가장 적합한 θ를 찾는 것 ❗
💡 그럼 training dataset이 주어졌을 때, 우리는 parameters θ를 어떻게 정해야할까?
- 적어도 우리가 가진 dataset에서,
y와 비슷한 를 만들어야 함
📌 Loss function (손실 함수)
-
예측 값과 실제 값이 얼마나 차이나는지 알려줌
-
는 계산(미분)의 편의성을 위해 있는 것으로, 없어도 됨
-
절댓값을 안 쓰고 제곱을 하는 이유는?
⇒ 최적화 과정에서 절댓값은 적절하지 않음
+) 최적화 과정에서 미분 사용
📌 Cost function
-
Loss를 모두 더한 값
-
1부터 N까지 Loss를 전부 합한 것
Optimization (최적화)
-
를 최소화하는
θ를 찾아야 함! -
Optimization: θ를 찾는 과정 -
Gradient descent algorithm,Stochastic gradient descent algorithm(SGD), ... -
데이터가 많아지면 matrix 연산하는 게 어려워짐
⇒ θ를 랜덤 값으로 초기화 → 갱신
Classification and Logistic regression
Binary classification
-
Classification:y는 적은 수의 이산적인 값을 가짐 (descrete values) -
Binary classification
-y가 0과 1의 값만 가짐
-0: Negative,1: Positive -
Multiple classification:y가 2개보다 더 많은 값을 가짐
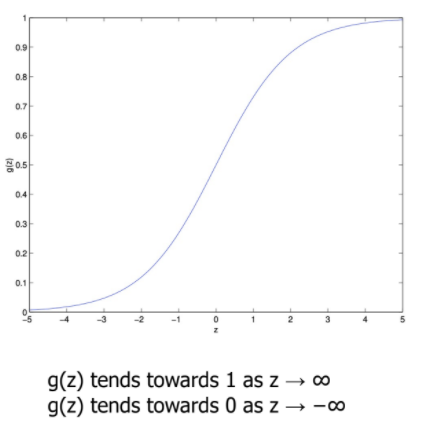
Logistic regression
- 0과 1 사이의 값으로 bound
Logistic (sigmoid) function
g'
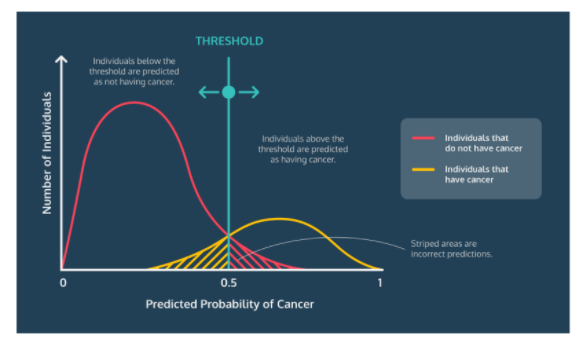
💡 어떻게 학습?
- set classification threshold
Positive: score > thresholdNegative: otherwise
💡 threshold는 어떻게 설정?
- 일반적으로 0.5