[Study] AI
1.[AI] ML Intro
졸프 모델 개발과 빅데이터분석경진대회에 앞서 관련 개념들을 리마인드해보고자 그동안 배운 내용들을 정리해보려 한다!💡 기계학습(Machine learning)스스로 경험을 통해 성능을 향상시키는 컴퓨터 알고리즘The study of computer algorithms
2.[AI] Linear regression / Logistic regression
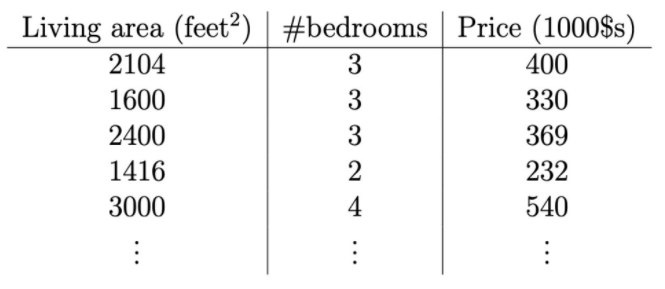
dataset : 47개의 집에 대한 living area, number of bedrooms, pricefeature : living area, number of bedroomstarget : price우리는 다른 집들에 대한 Price를 예측하도록 학습할 수 있을까
3.[AI] Overfitting, Regularization
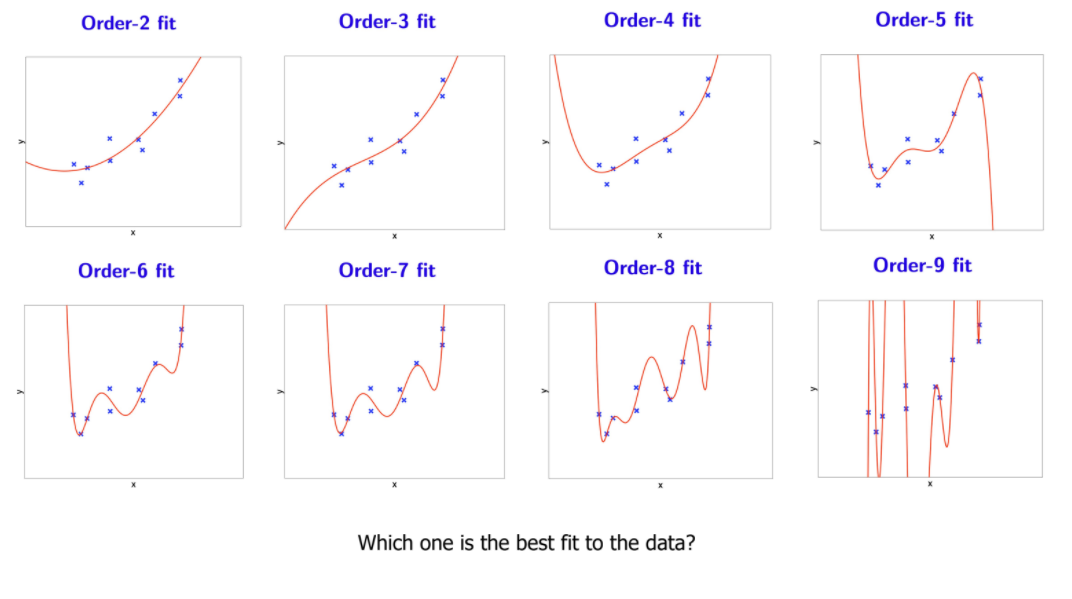
Linear regression을 통해 얻은 data 및 최적의 linear 가설 공간1.60, 1.05는 각각 $θ\_1, θ\_0$으로 1차원의 가설 공간!💡 그렇다면 linear regression으로 충분할까?Linear regression은 대부분의 현실 문
4.[AI] Decision Tree
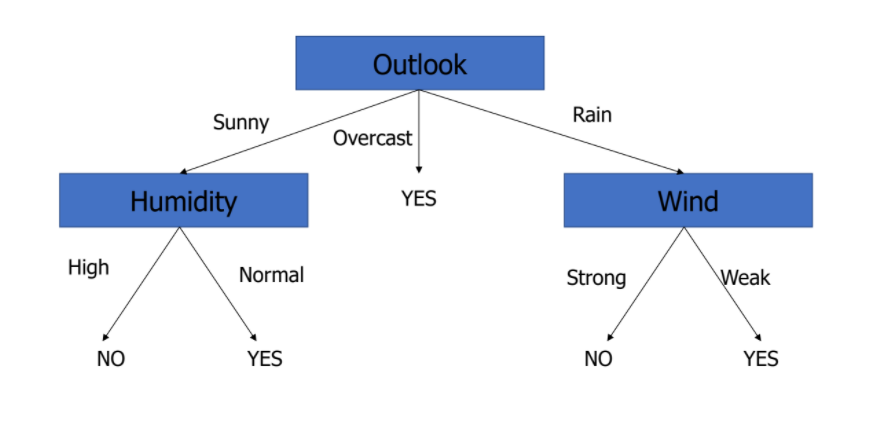
만약, Outlook: Overcast, Temperature: Hot, Humidity: Normal, Wind: Weak일 때,PlayTennis: Yes? No?Classification by Partitioning Example Space목표 : 이산적인 값을
5.[AI] kNN
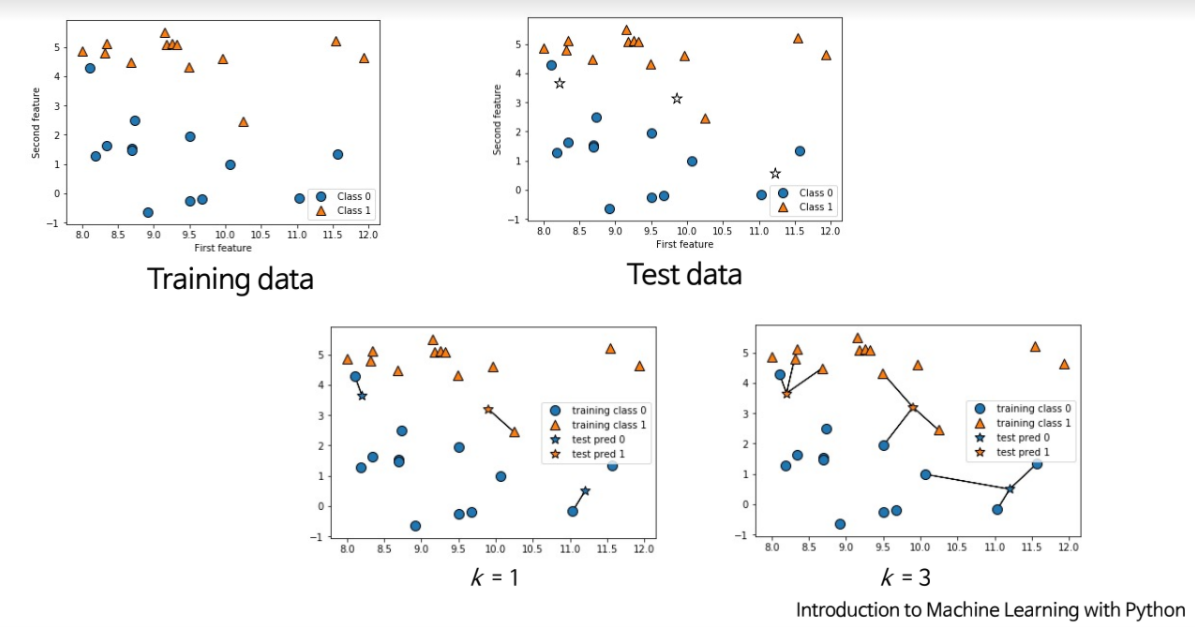
별다른 모델 없음key idea : just store!!!모든 training data를 그냥 저장 (Training)Nearest neighobr : (Test)주어진 query instance $x_q$와 가장 가까운 training example $x_n$을 먼
6.[AI] SVM (1)
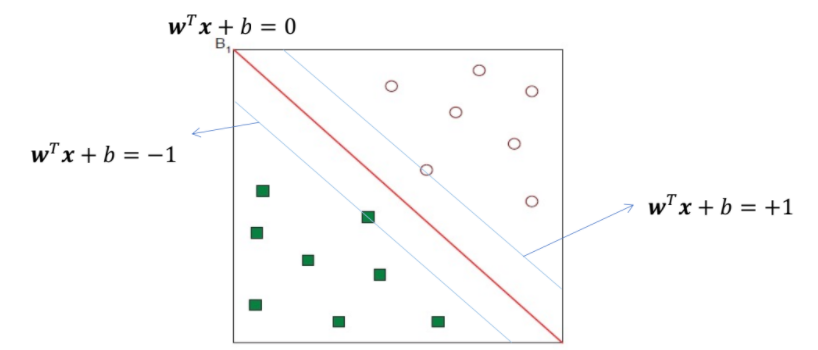
Linear Separators Data를 분리할 linear hyperplane 찾기 (decision boundary, 결정 경계) One Possible Solution $w^T$ : $\theta$ , $b : w_0$ Another Possible Sol
7.[AI] SVM (2)
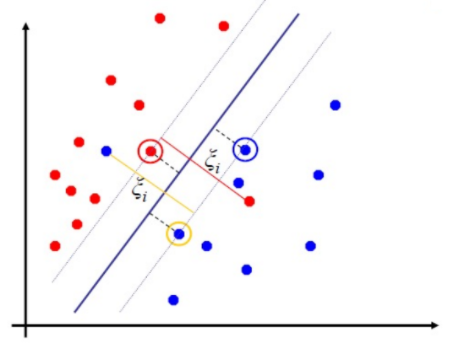
💡 만약에 training set이 not linearly separable 하다면?Hard Margin : 모든 data가 분류되어야 함!Soft Margin : 몇 개는 틀려도 된다고 허용!⇒ Slack variables (여유 변수)C : hyper parame