Day 1
Count-based Representation
자연어 처리 관련 용어
- 말뭉치(corpus) : 특정한 목적을 가지고 수집한 텍스트 데이터
- 문서(Document) : 문장들의 집합
- 문장(Sentence) : 여러 개의 토큰(단어, 형태소 등)으로 구성된 문자열, 마침표/ 느낌표 등의 기호로 구분
- 어휘집합(Vocabulary) : 코퍼스에 있는 모든 문서, 문장을 토큰화한 후 중복을 제거한 토큰의 집합
전처리
- 토큰화(Tokenization)
- 차원의 저주(Curse of Dimensionality)
- 불용어(Stop words)
- 어간 추출(Stemming)
- 표제어 추출(Lemmatization)
What is NLP?
-
자연어를 컴퓨터로 처리하는 기술
-
자연어 처리(NLP)에는 자연어 이해(NLU) 와 자연어 생성(NLG) 의 세부 분야가 있음
- 자연어 이해(NLU)
- 분류(Classification) : 뉴스 기사 분류, 감정 분석(Positive/Negative)
- 자연어 추론(NLI, Natural Language Inference)
- 기계 독해(MRC, Machine Reading Comprehension), 질의 응답
- 품사 태깅(POS tagging), 개체명 인식(Named Entity Recognition) 등
- 자연어 생성(NLG, Natural Language Generation)
- 텍스트 생성(특정 도메인의 텍스트 생성) : 뉴스 기사 생성, 가사 생성
- NLU & NLG
- 기계 번역
- 요약
- 추출 요약(NLU에 가까움) : 문서 내에서 해당 문서를 잘 요약하는 부분을 찾아 내는 것
- 생성 요약(NLG에 가까움) : 해당 문서를 요약하는 요약문 생성
- 챗봇
- 특정 태스크를 처리하기 위한 챗봇(TOD)
- 정해지지 않은 주제를 다루는 일반대화 챗봇(ODD)
- 기타
- TTS(Text to Speech) : 텍스트 음성으로 읽기
- STT(Speech to Text) : 음성 텍스트로 읽기
- Image Captioning : 이미지를 설명하는 문장 생성
- 자연어 이해(NLU)
-
벡터화(Vectorize)
- 컴퓨터가 이해할 수 있도록 자연어를 벡터로 만들어 주는 것
- 자연어를 어떻게 벡터로 표현하는 지는 자연어 처리 모델의 성능을 결정하는 중요한 역할을 함
- 자연어 벡터화하는 방법
- 등장 횟수 기반 단어 표현(Count-based Representation)
- Bag-of-words(
CounterVectorize) - TF-IDF(
TfidVectorizer)
- Bag-of-words(
- 분포 기반의 단어 표현(Distributed Representation) : 타겟 단어 주변에 있는 단어를 기반으로 벡터화하는 방법
- Word2Vec
- GloVe
- fastText
- 등장 횟수 기반 단어 표현(Count-based Representation)
텍스트 전처리(Text Preprocessing)
- 내장 메소드 사용(
lower,replace...) - 정규 표현식(Regular expression, Regex)
-
문자열에서 특정한 규칙을 가지는 문자열의 집합을 찾아내기 위한 검색 방법
-
a-z(소문자),A-Z(대문자),0-9(숫자) 를^제외한 나머지 문자를regex에 할당한 후.sub메소드를 통해 공백 문자열 ""로 치환import re # ^ : not 을 의미 regex = r"[^a-zA-Z0-9]" # 정규식 test_str = ("(Natural Language Processing) is easy!, AI!#n") subst = "" # 치환할 문자 result = re.sub(regex, subst, test_str) #'Natural Language Processing is easy AI' -
SpaCy 라이브러리
import spacy from spacy.tokenizer import Tokenizer nlp = spacy.load("en_core_web_sm") tokenizer = Tokenizer(nlp.vocab) tokens = [] for doc in tokenizer.pipe(df['column_name']): doc_tokens = [re.sub(r"[^a-z0-9]", "", token.text.lower()) for token in doc] tokens.append(doc_tokens)
-
- 불용어(Stop words) 처리
-
불용어 : 분석에 도움이 되지 않는 단어
-
대부분의 NLP 라이브러리는 일반적인 불용어를 내장하고 있음
- ex. spacy 제공 불용어 :
nlp.Defaults.stop_words
# 불용어 제외하고 토크나이징 진행 tokens = [] for doc in tockenizer.pipe(df['column_name']): doc_tokens = [] for token in doc: # 토큰이 불용어와 구두점이 아니면 저장 if (token.is_stop == False) & (token.is_punct == False): tokens.append(doc_tokens) - ex. spacy 제공 불용어 :
-
불용어 커스터마이징
STOP_WORDS = nlp.Defaults.stop_words.union(['smt_you_want_to except']) token = [] for doc in tokenizer.pipe(df['column_name']): doc_tokens = [] for token in doc: if token.text.lower() not in STOP_WORDS: doc_tokens.append(token.text.lower()) tokens.append(doc_tokens)
-
- 통계적 트리밍(Trimming)
- 통계적인 방법을 통해 말뭉치 내에서 너무 많거나 너무 적은 토큰을 제거하는 방법
- 어간 추출(Stemming) 혹은 표제어 추출(Lemmatization)
- 어간 : 단어의 의미가 포함된 부분으로 접사 등이 제거된 형태
-
Poter,Snowball,Dawson등 알고리즘 有 -
Spacy는 stemming 제공하지 않음 -
nltkfrom nltk.stem import PorterStemmer ps = PoterStemmer() words = ['wolf', 'wolves'] for word in words: print(ps.stem(word)) # wolf # wolv ## 어근이나 단어의 원형이 같지 않을 수 있음 -
Porter알고리즘은 단어의 끝부분을 자르는 역할- 간단하고 속도가 빨라 속도가 중요한 검색 분야에서 많이 사용
-
- 표제어 : 기본 사전형 단어, 단어의 가장 기본 형태
- 어간 추출보다 체계적
- 기본 사전형 단어형태 Lemma(표제어)로 변환
-
복수형 → 단수형, 동사 → 타동사
lem = 'The social wolf. Wolves are complex.' nlp = spacy.load?("en_core_web_sm") doc = nlp(lem) # The → the # social → social # wolf → wolf # . → . # Wolves → wolf # are → be # complex → complex # . → .def get_lemmas(text): lemmas = [] doc = nlp(text) for token in doc: if ((token.is_stop == False) and (token.is_punct == False)) and (token.pos_ != 'PRON'): lemmas.append(token.lemma_) return lemmas
-
- 어간 : 단어의 의미가 포함된 부분으로 접사 등이 제거된 형태
시각화
Squarify라이브러리
등장 횟수 기반의 단어 표현(Count-based Representation)
- Bag-of-Words(BOW)
-
문서-단어 행렬(DTM)
- 행에는 문서, 열에는 단어
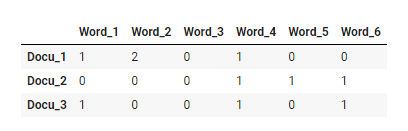
- 행에는 문서, 열에는 단어
-
TF
-
단어 빈도만 고려
-
Sklearn
CounterVectorizerfrom sklearn.feature_extraction.text import CountVectorizer # 문장으로 이루어진 리스트 저장 sentences_lst = text.split('\n') # CountVectorizer 를 변수에 저장 vect = CountVectorizer() # 어휘 사전을 생성 vect.fit(sentences_lst) # text 를 DTM으로 변환 dtm_count = vect.transform(sentences_lst) #.vocabulary_ 메소드로 모든 토큰과 맵핑된 인덱스 정보 확인 vect.vocabulary_
-
-
TF-IDF
- 단어마다 가중치를 두는 방법
- 로그를 하는 이유는 단순히 값이 너무 커지는 것을 방지하기 위함
- 실제 계산에서 0으로 나누어 주는 것을 방지하기 위해 분모에 +1
- Sklearn
TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english', max_features=15) #fit 후 dtm dtm_tfidf = tfidf.fit_transform(sentences_lst) # dateframe으로 만들기 pd.DataFrame(dtm_tfidf.todense(), columns=tfidf.get_feature_names())
-
- 파라미터 튜닝
def tokenize(document):
doc = nlp(document)
return [token.lemma_.strip() for token in doc if (token.is_stop != True) and (token.is_punct != True) and (token.is_alpha == True)]
tfidf_tuned = TfidfVectorizer(stop_words='english',
tokenizer=tokenize,
ngram_range=(1,2), # (min_n, max_n) : min_n 개 ~ max_n 개를 갖는 n-gram(n개의 연속적인 토큰)을 토큰으로 사용
max_df=.7, # float(0~1), max_df*100% 이상 문서에 나타나는 토큰은 제거
min_df=3 # int, 최소 n개의 문서에 나타나는 토큰만 사용
)- 코사인 유사도
- 두 벡터(문서)가 완전히 같으면 1, 90도 각을 이루면 0, 완전히 반대방향이면 -1
- K-NN, K-최근접 이웃(Nearest Neighbor)
-
쿼리와 가장 가까운 상위 K개의 근접한 데이터를 찾아서 K개 데이터의 유사성을 기반으로 점을 추정하거나 분류하는 예측 분석
-
Sklearn
NearestNeighborsfrom sklearn.neighbors import NearestNeighbors # dtm을 사용해 NN모델 학습, 디폴트 최근접 5 nn = NearestNeighbors(n_neighbors=5, algorithm='kd_tree') nn.fit(dtm_tfidt_amazon) # 해당 문서와 가장 가까운 문서(0포함) 5개 거리(값이 작을수록 유사)와 인덱스 확인할 수 있음
-
token.pos_ != 'PRON'
대명사가 아닌 것
token.is_punct == False
구두점이 없는 곳
한국어 데이터는 자연어 처리에서 처리하기 어려운 데이터
- KoNLPy 라이브러리 사용 -- 형태소 분석기
- Py-hanspell -- 네이버 맞춤법 검사기를 이용한 파이썬 라이브러리
- Py-(ko)spacing, kss -- 띄어쓰기 기준
- Khaiii -- 카카오 오픈 소스 라이브러리(형태소 분석기)
- soynlp -- 반복되는 이모티콘이나 단어들을 정규화하기 위해 만들어짐(ex. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ, ㅎㅎㅎㅎㅎㅎㅎ 같은 거)
Day 2
Distributed Representation
분산 기반의 표현(Distributed representation)
등장 횟수 기반 단어 표현
단점 : 순서를 고려하지 않고 빈도수만 고려, 차원이 많아짐
-
분포 가설
- 비슷한 의미를 가진 단어는 주변 분포도 비슷할 것이다
-
원-핫 인코딩
- 범주형 변수를 0과 1로 벡터화 하는 방법
- 직관적인 방법이지만 단어 간 유사도를 구할 수 없고 차원이 너무 커짐
- 원-핫 인코딩 후 코사인 유사도를 구하게 되면 모두 0이 나옴
- 두 벡터의 내적이 항상 0이기 때문
임베딩(Embedding)
- 원-핫 인코딩의 단점 해결
- 단어를 고정 길이의 벡터(= 차원이 일정한 벡터)로 나타냄
- 벡터 내의 각 요소가 연속적인 값을 가짐
↓ 가장 널리 알려진 임베딩 방법
Word2Vec
-
단어를 벡터로 나타내는 방법
-
특정 단어 양 옆에 있는 두 단어(window size = 2)의 관계를 활용하기 때문에 분포 가설을 잘 반영
-
CBoW 와 Skip-gram 차이
- CBoW(Continuous Bag-of-Words)
- 주변 단어에 대한 정보를 기반으로 중심 단어의 정보를 예측하는 모델
- Skip-gram
- 중심 단어의 정보를 기반으로 주변 단어의 정보를 예측하는 모델
- 역전파 관점에서 CBoW에 비해 학습이 많이 일어나 성능이 더 좋음
- 학습 시간이 오래 걸리고 리소스 양이 많음

- CBoW(Continuous Bag-of-Words)
-
Word2Vec 모델 구조(Skip-gram 기준)
- 입력층 : 원-핫 인코딩 된 단어의 벡터(노드 수 = 단어 수)
- 은닉층 : 1개 (노드 수 = 임베딩 벡터의 차원 수)
- 활성화 함수 사용 X -> linear 이기 때문
- 출력층 : 소프트맥스 함수 사용(노드 수 = 입력층 노드 수)
Word2Vec 은 딥러닝일까?
NO! 딥러닝 = 은닉층이 2개 이상
- Word2Vec 학습을 위한 학습 데이터 디자인
- 중심 단어 옆에 있는 2개 단어에 대해 단어쌍 구성
- 중심 단어(입력), 주변 단어(레이블)ex. The tortoise jumped into the lake
- 중심 단어: The, 주변 문맥 단어 : tortoise, jumped
- 학습 샘플 : (the, tortoise), (the, jumped)

- 학습 샘플 : (the, tortoise), (the, jumped)
- 중심 단어: The, 주변 문맥 단어 : tortoise, jumped
- 중심 단어 옆에 있는 2개 단어에 대해 단어쌍 구성
- Word2Vec의 임베딩 벡터를 시각화한 결과의 특징
- 말뭉치에 등장하지 않는 단어(Unknown token)을 임베딩 벡터화 하면
KeyError발생 → OOV 문제
- 말뭉치에 등장하지 않는 단어(Unknown token)을 임베딩 벡터화 하면
Word2Vec을 더 적은 계산으로 하는 방법
- Sub-sampling
- 텍스트 자체가 가진 문제를 해결
- 'a', 'the' 처럼 얻을 정보가 없는 단어 제거
- Negative-sampling
- 불필요한 계산량 감소
- 무관한 단어들에 대해서는 weight 를 업데이트 하지 않아도 됨
- 무관한 단어는 target 값이 0 인 "negative" 값이고, 관련된 단어는 target 값이 1인 "positive" 한 값
fastText
-
Word2Vec방식에 철자기반의 임베딩 방식을 더해준 새로운 임베딩 방식 -
OOV(Out of Vocabulary) 문제 해결
-
철자 단위 임베딩 방법
- 모델이 학습하지 못한 단어이더라도 잘 쪼개고 보면 말뭉치에서 등장했던 단어를 통해 유추해 볼 수 있음
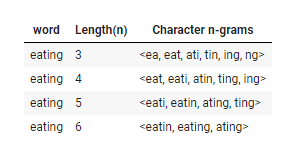
Character n-gram
-
fastText방식은 3-6개로 묶은 character정보(3-6 grams) 단위 사용-
3-6개 단위로 묶기 이전에 모델이 접두사와 접미사를 인식할 수 있도록 해당 단어 앞뒤로 "<",">"를 붙여줌
ex. <eating> 를 3-gram 하면
→ <ea eat ati tin ing ng>
이 방식을 3개부터 6개까지 진행하면 18개의 character-level n-gram을 얻을 수 있음
-
철자 단위 임베딩 적용
- eating 이라는 단어가 말뭉치 내에 있다면 skip-gram으로부터 학습한 임베딩 벡터에 18개 character-level n-gram들의 벡터를 더해줌
- 없다면 18개 character-level n-gram들의 벡터만으로 구성
-
-
Word2Vec은 두 단어 중 하나라도 말뭉치 내에 없다면 에러를 발생시키지만fastText는 높은 정확도로 두 단어의 임베딩 벡터를 구하고 유사도를 나타낼 수 있음 -
fastText임베딩 벡터는 단어의 의미보다는 결과 쪽에 더 비중을 두고 있음
pad_sequences(padding='post', maxlen=n)
- 자연어 처리를 하다보면 각 문장(또는 문서)의 길이가 다른 경우가 있음
→ 기계는 길이가 전부 동일한 문서들에 대해서는 하나의 행렬로 보고 한꺼번에 묶어서 처리할 수 있음
→ 병렬 연산을 위해 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업 필요- 데이터에 특정 값을 채워서 데이터의 크기를 조정하는 것을 패딩(padding) 이라고 함
- 케라스에서는
pad_sequence제공pad_sequences는 기본적으로 문서의 앞을 '0'으로 채우기 때문에 뒤를 '0'으로 채우려면padding='post'maxlen의 인자를 정수로 주게되면 해당 정수로 모든 문서의 길이가 동일해짐
model.add(Embedding(vacab_size, 300, weights=[embedding_matrix], input_length=max_len, trainable=False))
- trainable = False
- 훈련과정에서 embedding layer 제외
- 사전 학습된 데이터를 다시 학습하지 않음
Day 3
Language Modeling with RNN
연속형 데이터 : 데이터가 배치되는 순서, 즉 특정 데이터 앞 뒤로 어떤 데이터가 오는 지에 따라 각각의 의미가 변경되는 데이터
- 자연어, 시계열 데이터 등
RNN(Recurrent Neural Network, 순환 신경망) : 연속형 데이터를 처리하기 위한 신경망
- 단점 : 기울기 소실(gradient vanishing)로 인한 장기 의존성(long-term dependency) 문제 발생
↓ 개선
LSTM(Long Short Term Memory, 장단기 기억망), GRU(Gated Recurrent Unit)
언어 모델(Language Model)
- 문장과 같은 단어 시퀀스에서 각 단어의 확률을 계산하는 모델
- Word2Vec
- 통계기반 언어 모델
- 단어의 등장 횟수를 바탕으로 조건부 확률 계산
- 한계점
- 희소성 문제
- 말뭉치에 없는 표현은 절대 만들어 낼 수 없음
→ 해결하기 위해N-gram,스무딩(smoothing),백오프(back-off)방법 고안
- 말뭉치에 없는 표현은 절대 만들어 낼 수 없음
- 희소성 문제
↓ 극복
- 신경망 언어 모델
- 횟수기반 대신
Word2Vec이나fastText등의 출력값인 임베딩 벡터 사용 → 말뭉치에 등장하지 않더라도 의미/문법적으로 유사하면 선택
- 횟수기반 대신
신경망 언어 모델
- RNN(Recurrent Neural Network, 순환 신경망)
- 구조
- 연속형 데이터를 처리하기 위해 고안된 신경망
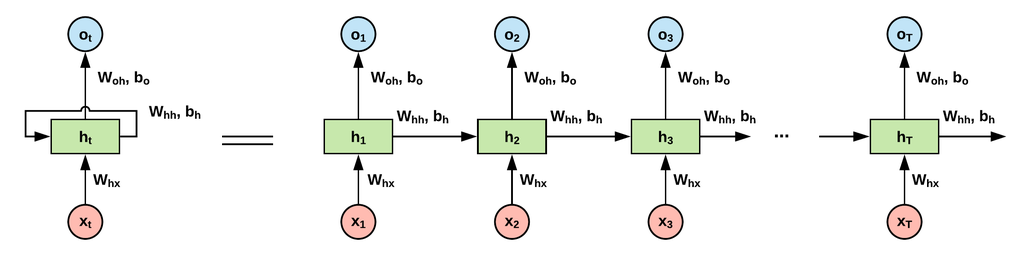
- 입력 벡터가 은닉층에 들어가는 것을 나타내는 화살표()
- 은닉층으로부터 출력벡터가 생성되는 것을 나타내는 화살표()
- 은닉층에서 나와 다시 은닉층으로 입력되는 화살표()
- 연속형 데이터를 처리하기 위해 고안된 신경망
- 작동 방식
- 시점에서는 와 가 입력되고 이 출력 → 모든 토큰이 입력될 때까지 반복
- 가중치 : ,
- 편향 :
- 코드
class RNN: def __init__(self, Wx, Wh, b): # Wx : 입력벡터(x)에 곱해지는 가중치, Wh: 은닉 상태 벡터(h_prev: 이전 시점의 은닉상태 벡터)에 곱해지는 가중치, b: 편향 self.params = [Wx, Wh, b] self.grads = [np.zeros_like(Wx), no.zeors_like(Wh), np.zeros_like(b)] # 가중치 초기화 self.cache = None def forward(self, x, h_prev): Wx, Wh, b = self.params t = np.matnul(h_prev, Wh_ + np.matmul(x, Wx), b h_next = np.tanh(t) self.cache = (x, h_prev, h_next) return h_next - 장점 : 간단한 모델, 어떤 길이의 sequential 데이터라도 처리할 수 있음
- 단점
- 병렬화(parallelization) 불가능
- RNN 구조는 벡터가 순차적으로 입력됨
→ GPU 연산의 장점인 병렬화 불가능
→ RNN 기반의 모델은 GPU 연산을 했을 때 이점이 거의 없음
- RNN 구조는 벡터가 순차적으로 입력됨
- 역전파 과정에서의 문제점
- 기울기 폭발(Exploding gradient)
- 역전파 정보가 hidden-state 벡터에 과하게 전달
- 기울기 소실(vanishing gradient)
- hidden-state 벡터에 역전파 정보가 거의 전달되지 않음
- 기울기 폭발(Exploding gradient)
- 병렬화(parallelization) 불가능
- 구조
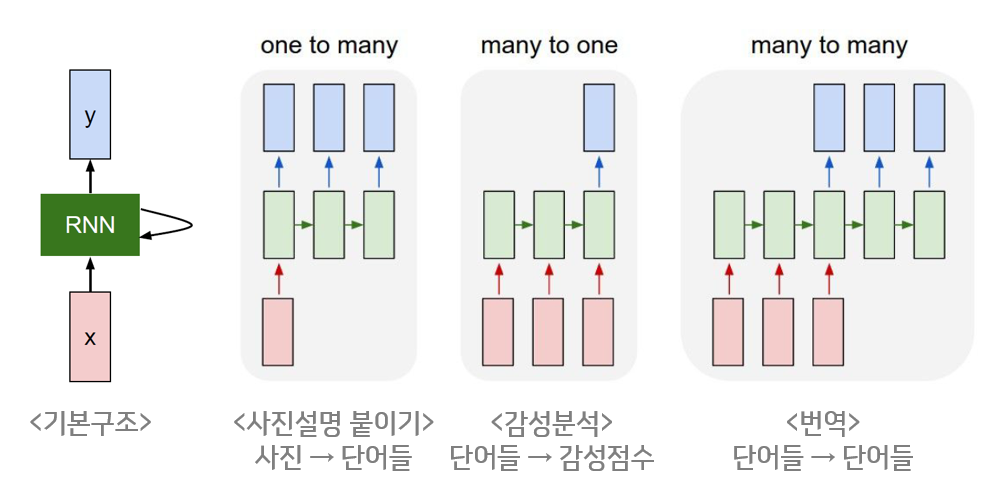
다양한 형태의 RNN
- one-to-many
- 1개의 벡터를 받아 Sequential한 벡터를 반환
- image captioning(이미지를 입력받아 이를 설명하는 문장 생성) 에 사용
- many-to-one
- Sequential 벡터를 받아 1개의 벡터를 반환
- 감성분석
- many-to-many(1)
- Sequential 벡터를 모두 입력받은 뒤 Sequential 벡터 출력
- seq2seq 구조, 기계번역
- many-to-many(2)
- Sequential 벡터를 입력받는 즉시 Sequential 벡터 출력
- 비디오를 프레임별로 분류
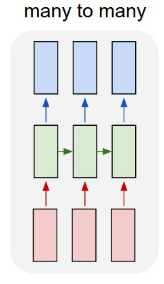
-
LSTM(Long Short Term Memory, 장단기 기억망)
-
고안된 배경
- RNN에 기울기 정보 크기를 조절하기 위한 Gate 추가한 모델
- 기울기 소실문제를 해결하기 위해 고안
-
구조
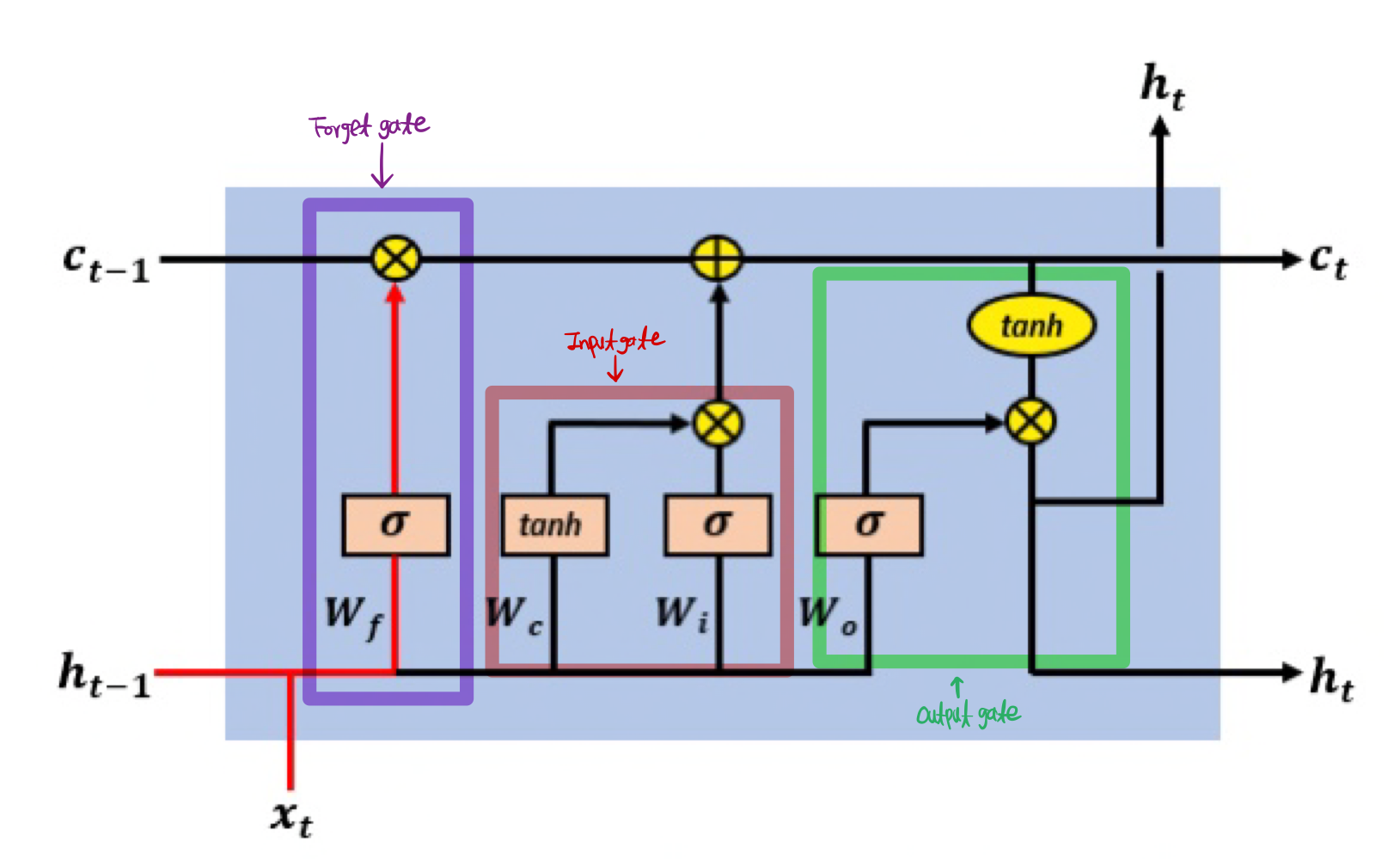
- Forget Gate: 과거의 정보를 얼마나 유지할 것인지
- Input Gate: 새로 입력된 정보는 얼마만큼 활용할 건인지
- Output Gate: 두 정보를 계산하여 나온 출력 정보를 얼마만큼 넘겨줄 것인지
- cell-state: 활성화 함수를 거치지 않아 정보 손실 無
# Keras 제공 Embedding 층 적용, LSTM 에 dropout 과 recurrent_dropout 적용 model = tf.keras.models.Sequential([ tf.keras.layers.Embedding(max_features, 128), tf.keras.layers.LSTM(128, dropout=0.2, recurrent_dropout=0.2), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
-
dropoutvsrecurrent_dropout
dropout: 입력층의 노드 수를 제한recurrent_dropout: 순환 드롭아웃, 순환층에서 과대적합을 방지하기 위함- RNN 모델 밖에서 dropout을 하면 정보손실이 발생할 수 있어 모델 안에서 인풋 데이터에 대한 노드를 끊어내어 정보손실을 방지함
model.summary()에서 LSTM의 param 개수
Embedding에서의 max_features(input_dim, 단어 갯수) * output_dim
→ 임베딩은 편향이 없기 때문에 더해주지 않음
LSTM의 units 인수
Embedding 레이어 차원수와 꼭 같을 필요는 없음
중소형 모델의 경우 128, 256, 512, 1024 를 주로 사용
- GRU(Gated Recurrent Unit)
- LSTM 의 간소한 버전
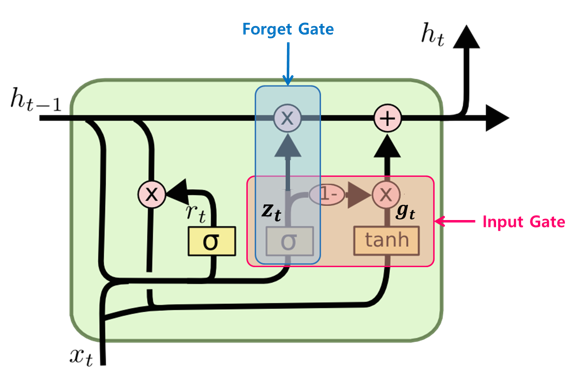
- cell-state 벡터와 hidden-state 벡터가 하나의 벡터 로 통일
- 하나의 Gate 가 forget, input gate를 모두 제어
- 가 1이면 forget 게이트가 열리고 가 0이면 input 게이트가 열림
- 전체 상태 벡터 가 각 time-step 에서 출력
- 가 이전 상태의 의 어느 부분이 출력될 지 제어
- LSTM 의 간소한 버전
어텐션(Attention)
-
배경
- 기존 RNN 기반 모델의 단점
- 기울기 소실로부터 나타나는 장기 의존성 문제
- Hidden-state를 하나만 넘겨줄 수 있음
→ 입력되는 모든 단어 정보를 하나의 Hidden-state 벡터에만 담아야 함
- 기존 RNN 기반 모델의 단점
-
모델 구조

- 각 인코더의 Time-step 마다 Hidden-state 벡터 생성
- 입력 단어가 N개라면 Hidden-state벡터도 N개
- 모든 단어가 입력되면 생성된 Hidden-state 벡터가 모두 디코더에 넘어감
-
디코더에서 전달받은 Hidden-state 벡터를 어떻게 사용하여 단어를 생성할까
- 쿼리(Query)로는 디코더의 Hidden-state 벡터, 키(Key)와 밸류(Value)로는 인코더에서 넘어온 Hidden-state 벡터를 준비
- 쿼리와 키의 연관성을 구하기 위해서 각 벡터를 내적한 값을 계산
- 이 값에 소프트맥스(Softmax) 함수를 취함
- 소프트맥스의 결과값에 밸류(Value)인 인코더에서 넘어온 Hidden-state 벡터를 곱함
- 결과로 나오는 벡터를 모두 합
→ 이 벡터의 성분 중에는 쿼리-키 연관성이 높은 밸류 벡터의 성분이 더 많이 들어있음 - 최종적으로 5에서 생성된 벡터와 디코더의 Hidden-state 벡터를 사용하여 출력 단어를 결정
-
병렬화의 문제가 여전히 존재하지만 transfomer 가 해결해줌
어순은 어떻게 결정될까?
관사가 생성되는 과정은?
Day 4
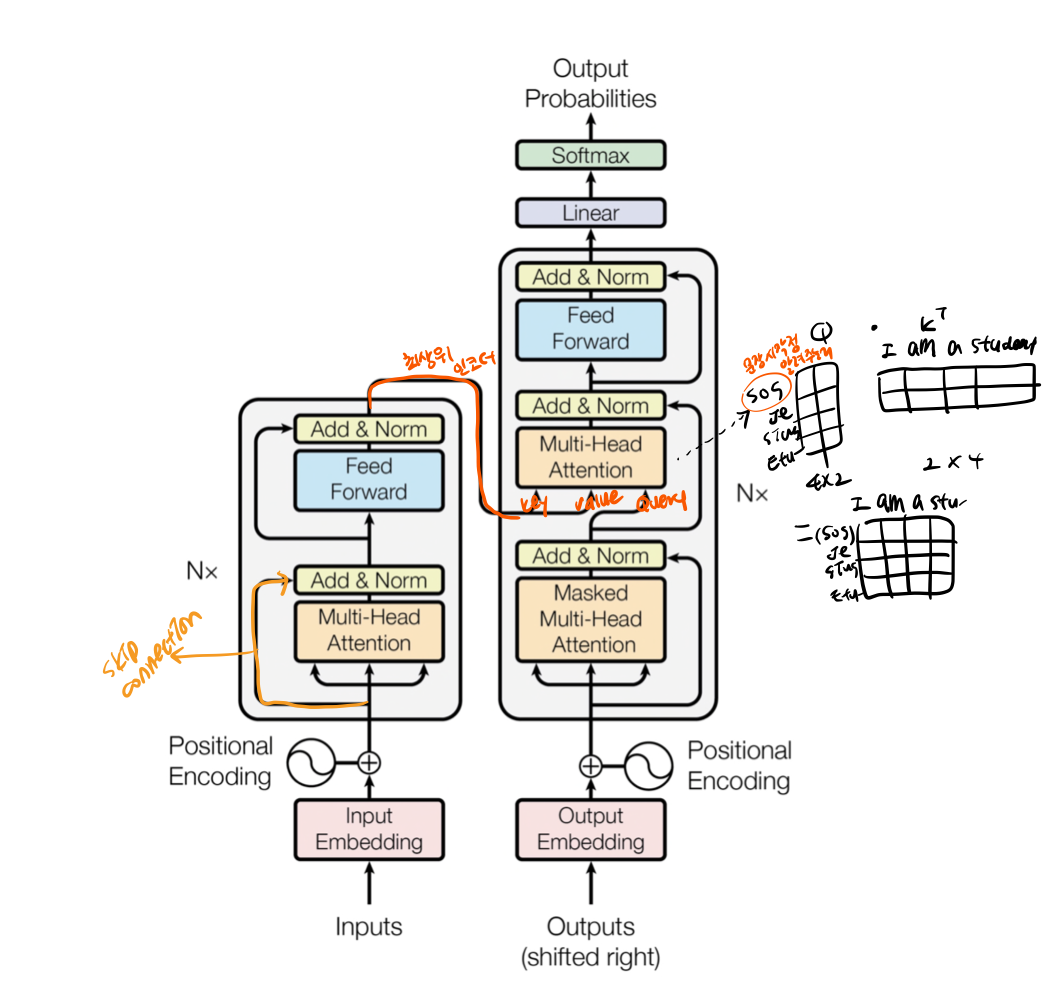
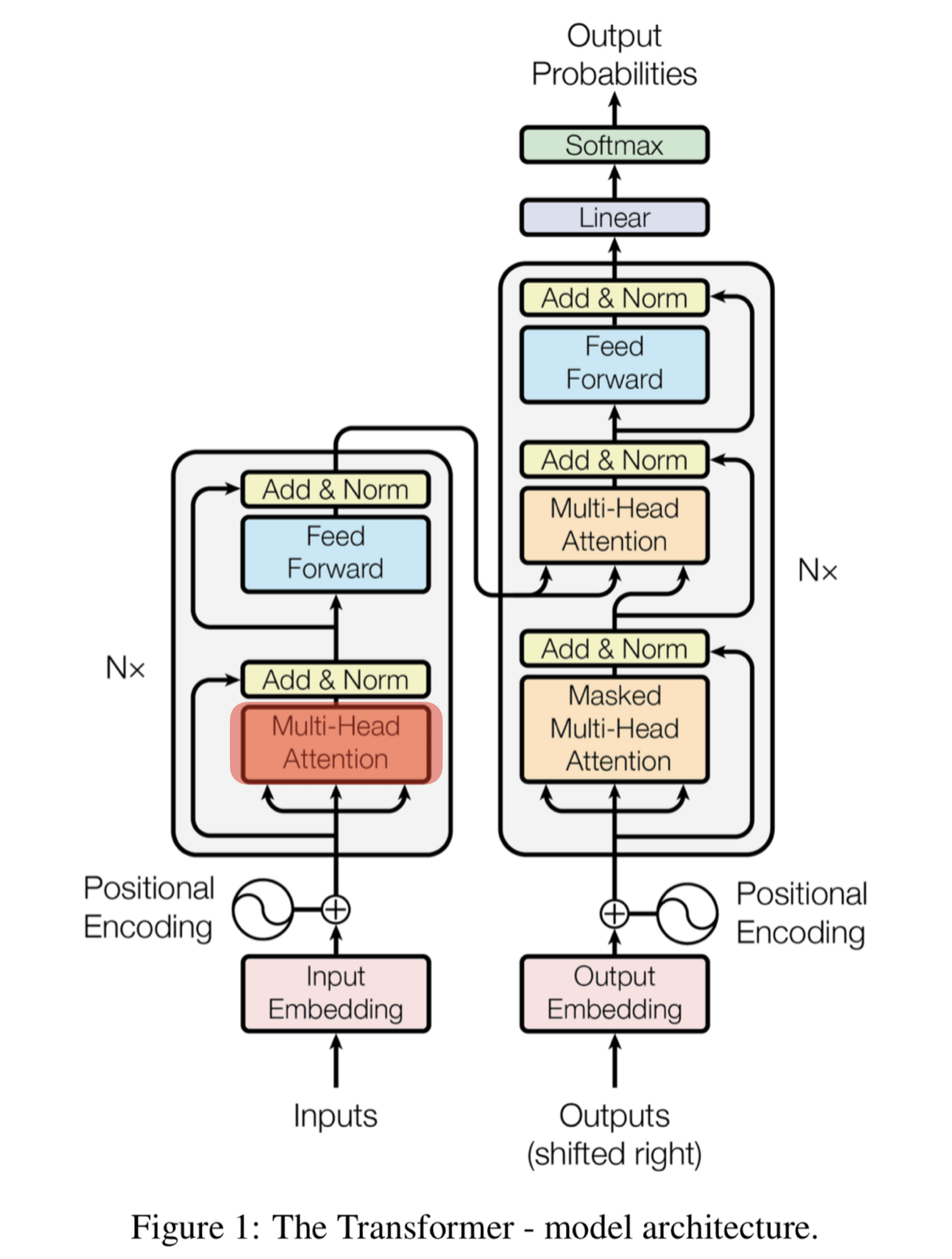
Transformer
- Transformer
- RNN 을 사용하지 않음 → 성능도 속도도 더 좋아짐
- 병렬화 가능
- 모든 토큰을 동시에 입력받아 병렬 연산하여 GPU 연산에 최적화
- 6개의 인코더 블록과 디코더 블록이 모여있는 구조
- 인코더 블록은 2개의 sub-layer
- Multi-Head (self) Attention, Feed Forward
- 디코더 블록은 3개의 sub-layer
- Masked Multi-Head (self) Attention, Multi-Head (encoder-decoder) Attention, Feed Forward
- 인코더 블록은 2개의 sub-layer
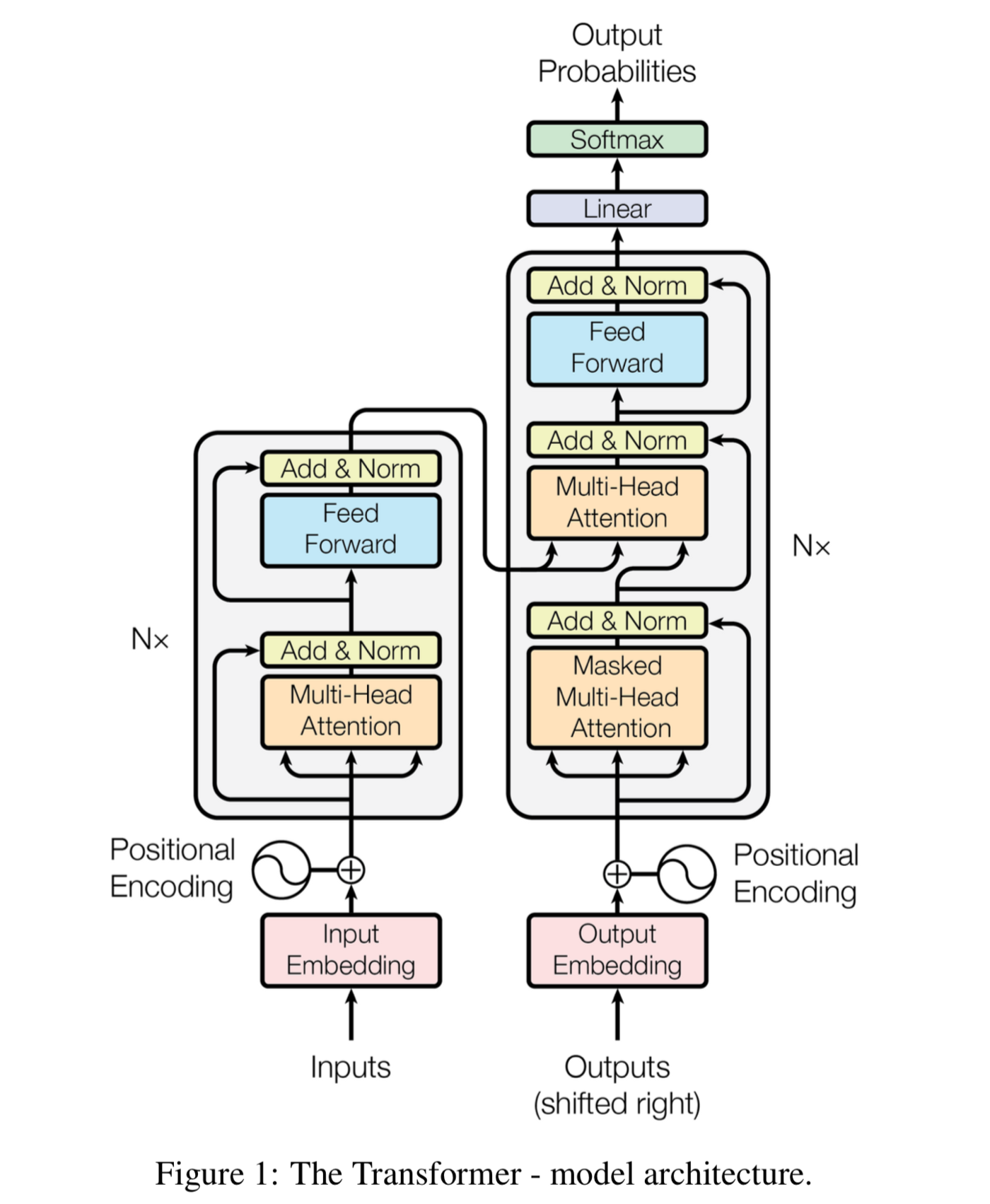
→ 입력 받는 값이 벡터가 아닌 행렬
-
Positional encoding(위치 인코딩)
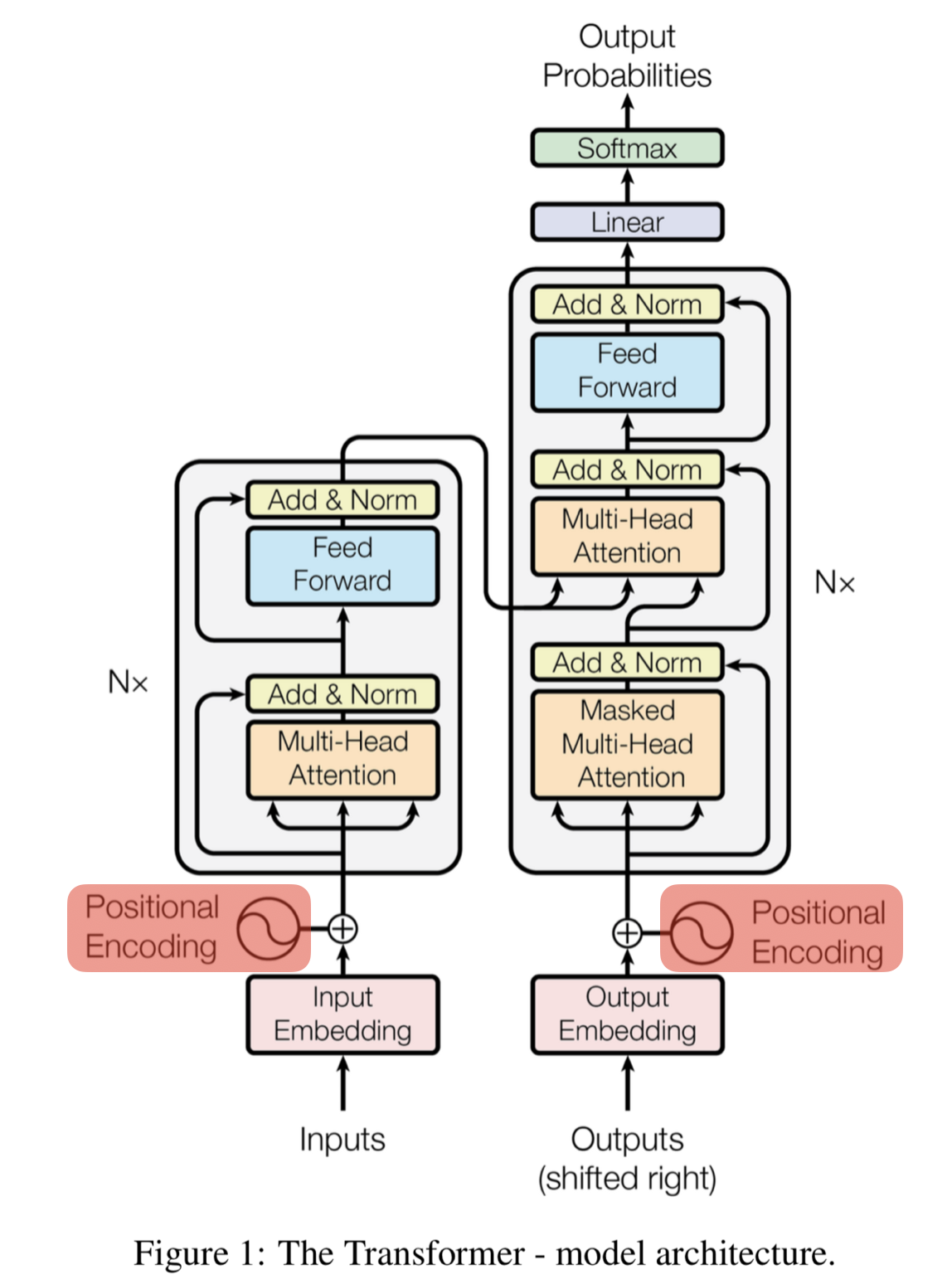
-
단어의 상대적인 위치 정보를 제공하기 위한 벡터를 만드는 과정
수식
2i : 짝수, 2i+1 : 홀수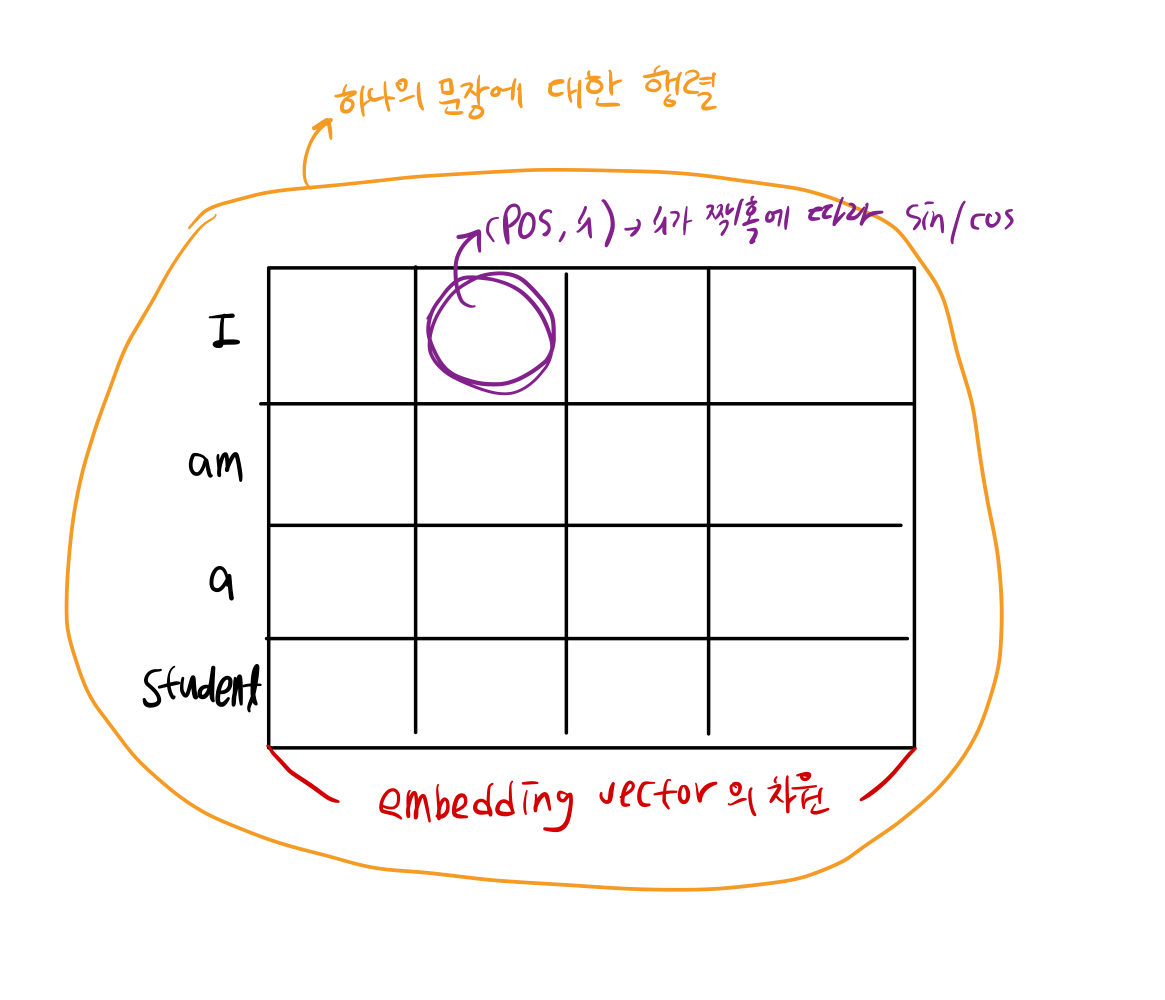
→ 계산하면 위치 인코딩 행렬이 생성 → positional encoding 행렬 + Embedding vector 행렬
def get_angles(pos, i, d_model): # sin, cos 안에 들어갈 수치 구하는 함수 angle_rates = 1 / np.power(10000, (2*(i//2)) / np.float32(d_model)) return pos * angle_ratesdef positional_encoding(position, d_model): # positional encoding 구하는 함수 angle_rads = get_angles(np.arange(position)[:, np.newaxis], np.arrange(d_model)[np.newaxis, :], d_model) # apply sin to even indices in the array; 2i angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2]) #apply cos to odd indices in the array; 2i+1 angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2]) pos_encoding = angle_rads[np.newaxis, ...] return tf.cast(pos_encoding, dtype=tf.float32)
-
-
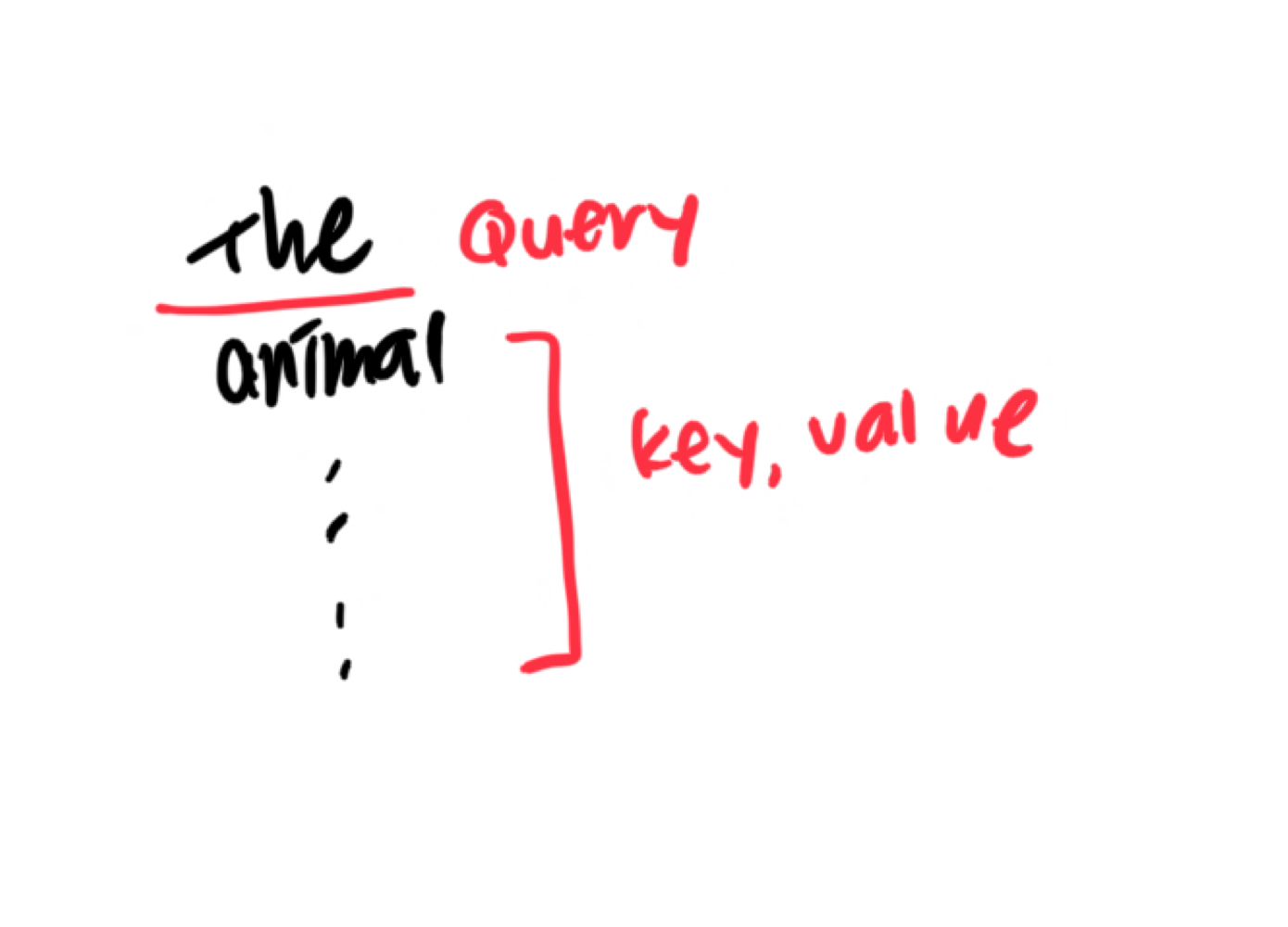
Self-Attention
-
번역하려는 문장 내부 요소의 관계를 잘 파악하기 위해서 문장 자신에 대한 어텐션 메커니즘을 적용하는데 이를 의미
→ 지시대명사 "it" 이 어떤 대상을 가리키는지 -
기존 Attention 과는 달리 쿼리, 키, 밸류 모두 가중치 벡터
- Query : 분석하고자 하는 단어데 대한 가중치 벡터
- Key : 각 단어가 쿼리에 해당하는 단어와 얼마나 연관이 있는 지를 비교하기 위한 가중치 벡터
- Value : 각 단어의 의미를 살려주기 위한 가중치 벡터
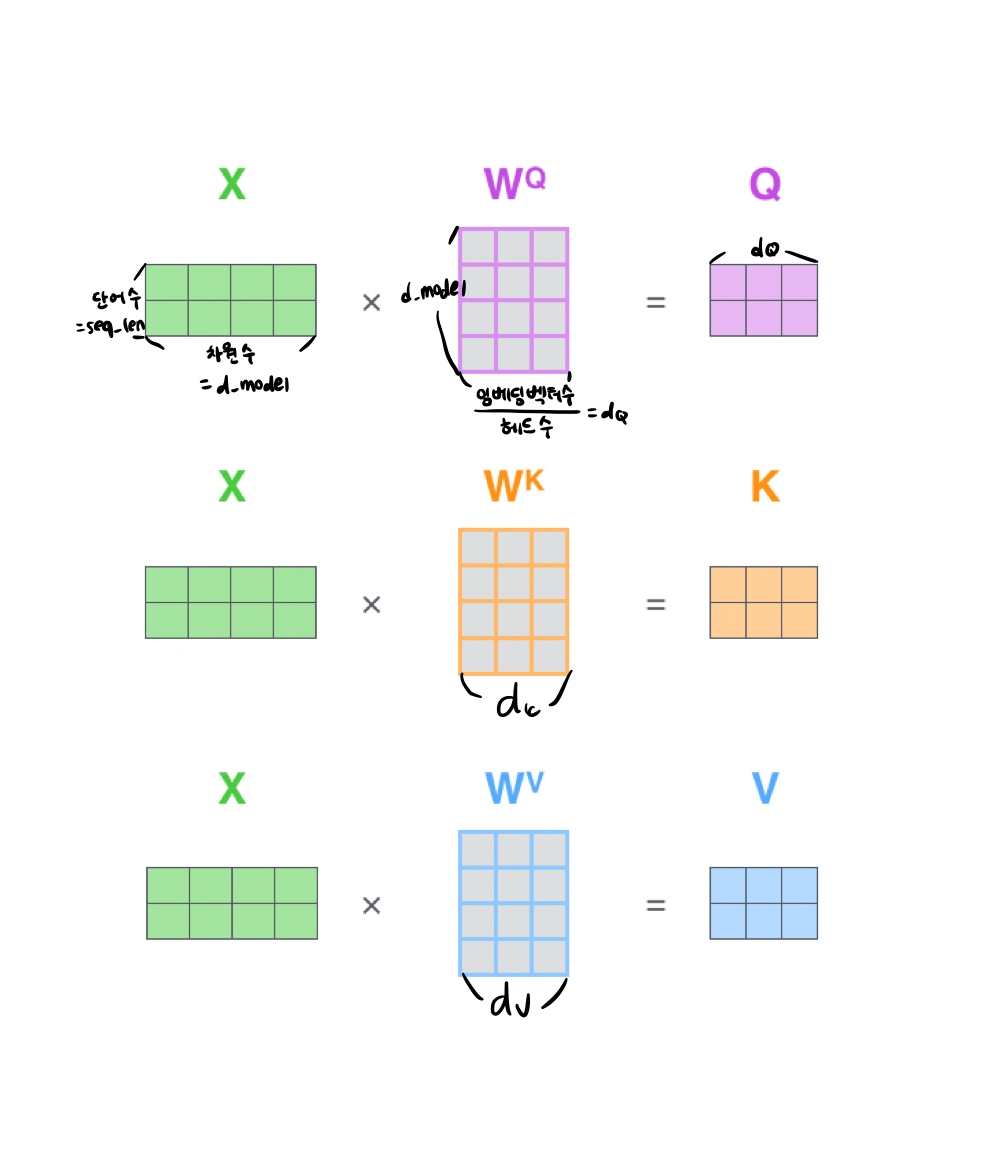
-
세가지 가중치 벡터를 대상으로 어텐션 적용
- 이전까진 Dot-product를 사용했지만 기울기 소실을 줄이기 위해 Scaled Dot Product 사용
- 특정 단어의 쿼리 벡터와 모든 단어의 키 벡터를 내적
→ 이 값이 Attention score - 이 가중치를 뭐리, 키, 밸류 벡터 차원 의 제곱근 로 나눠 줌
→ =
→ 계산값을 안정적으로 만들어 주기 위한 계산 보정 - Softmax
→ 쿼리에 해당하는 단어와 문장 내 다른 단어가 가지는 관계의 비율 구할 수 있음 - 밸류과 내적하면 최종 행렬 도출
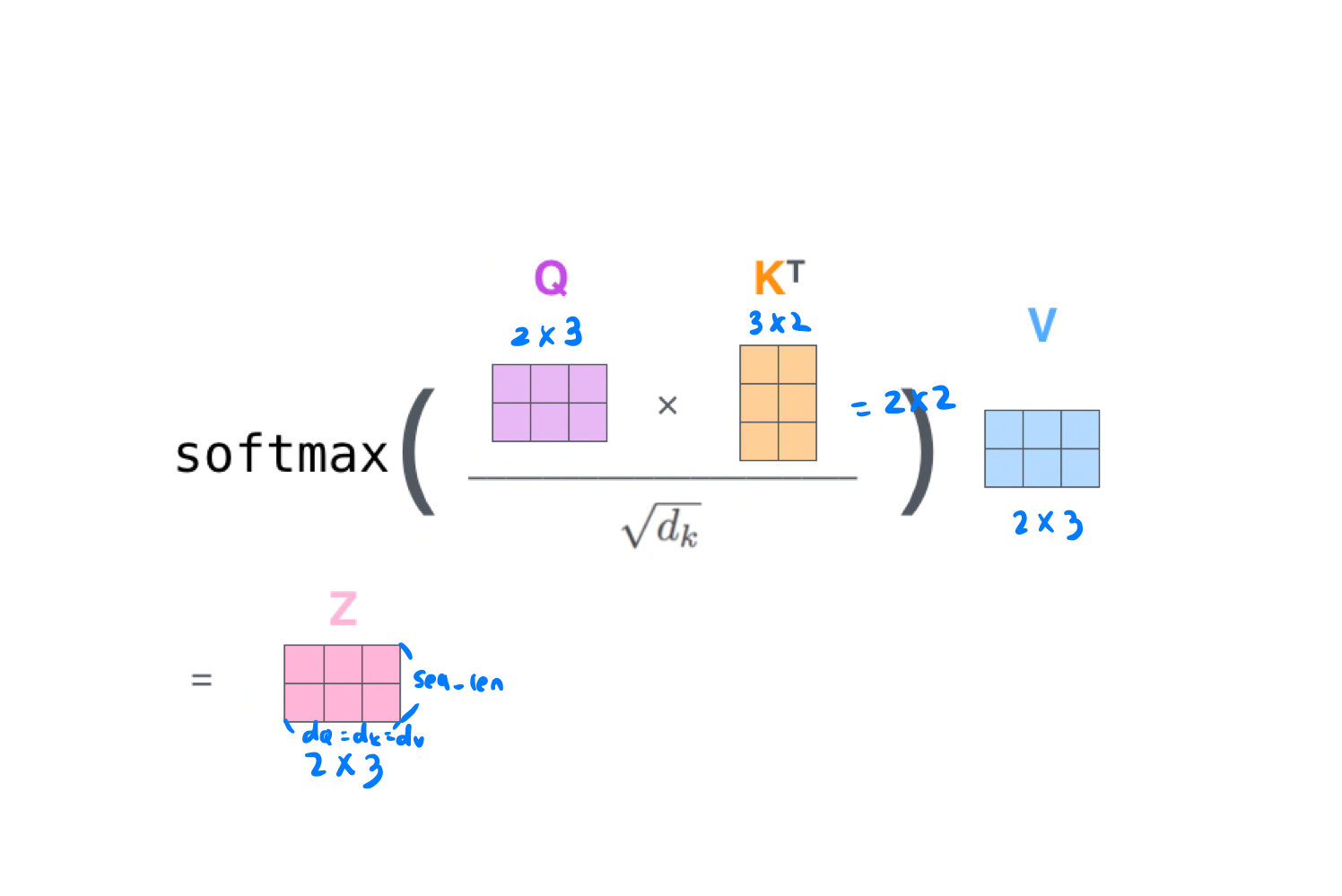
def scaled_dot_product_attention(q, k, v, mask): # Tensorflow 에서 Self-Attention 구현 코드 # q, k, v 의 leading dimension은 동일 # k, v의 penultimation dimension 은 동일, i.e. : seq_len_q, seq_len_k # Mask는 타입(padding or look ahead)에 따라 다른 차원을 가질 수 있음 # 덧셈시에는 브로드캐스팅 될 수 있어야 함 matmul_qk = tf.matmul(q, k, transpose_b = True) #(..., seq_len_q, seq_len_k) # matmul_qk(쿼리와 키의 내적)을 dk제곱근으로 나눠줌 dk = tf.cast(tf.shape(k)[-1], tf.float32) scaled_attention_logits = matmul_qk / ft.math.sqrt(dk) # 마스킹 if mask is not None: scaled_attention_logits += (mast * -1e9) # 소프트 맥스 → attention score attention_weights = tf.nn.softmax(scaled_attention_logits, axis=1) # (..., seq_len_q, seq_len_k) output = tf.matmul(attention_weights, v) #(..., seq_len_q, depth_v) return output, attention_weights
-
-
Multi-Head Attention
- Self-Attention 을 동시에 병렬적으로 실행하는 것
- 각 Head 마다 다른 Attention 결과를 내어주기 때문에 앙상블과 유사한 효과
- 앙상블 모델 : 여러 모델이 동일한 문제를 해결하고 더 나은 결과를 얻도록 훈련시키는 기계학습 패러다임
- Head의 수 만큼 Self-Attention 을 실행하여 얻은 행렬들을 이어붙이고(concatenate) 가중치 행렬과의 내적을 통해 Multi-head Attention 의 최종 행렬 를 만듦
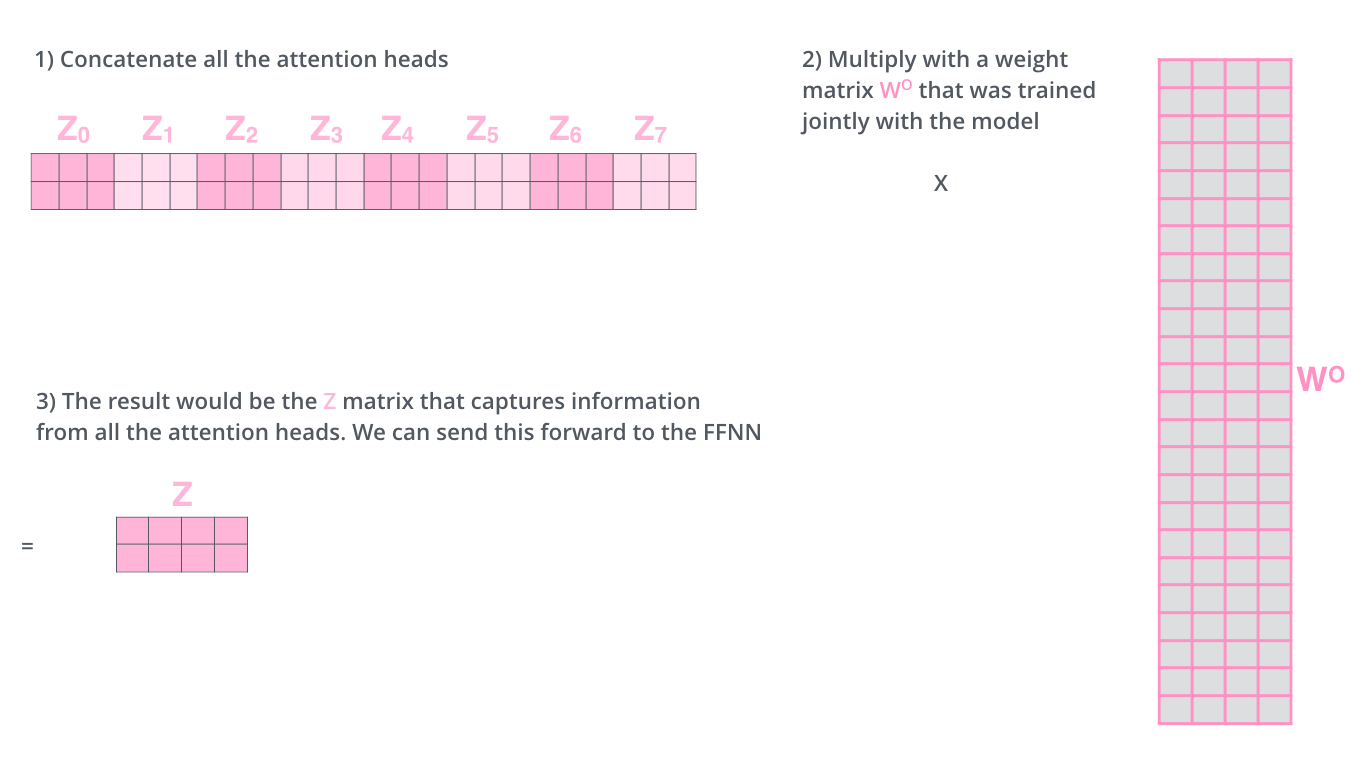
- 1번 : 가로는 d_model(임베딩 벡터 차원 수), 세로는 단어 수
- 2번 : 가로 세로 모두 d_model, 원래는 정사각형 형태
- 최종 행렬 은 토큰 벡터로 이루어진 행렬 와 동일한 크기(위의 그림에서 초록색 행렬)
- 최종 행렬 는 위치정보 + self attention 의 결과로 나온 단어 간의 상관관계
-
Add & Norm(Layer Normalization & Skip Connection)
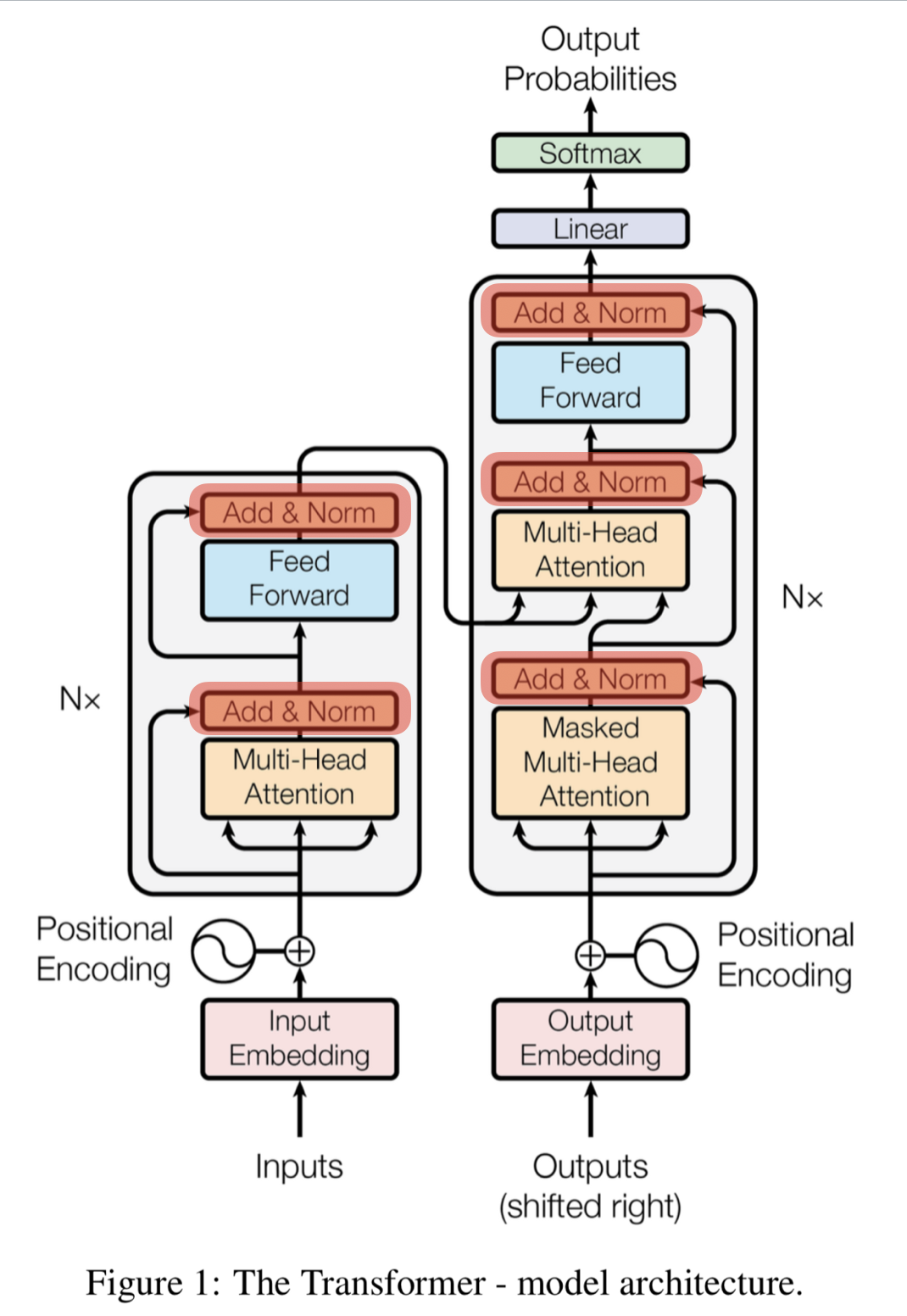
- 모든 sub-layer 에서 출력된 벡터들이 거치는 단계
- Layer normalization 의 효과는 Batch normalization 과 유사
- 학습이 훨씬 빠르고 잘 됨
- Skip connection(= Residual connection)은 역전파 과정에서 정보가 소실되지 않도록 함
-
Feed Forward(Feed Forward Neural Network)
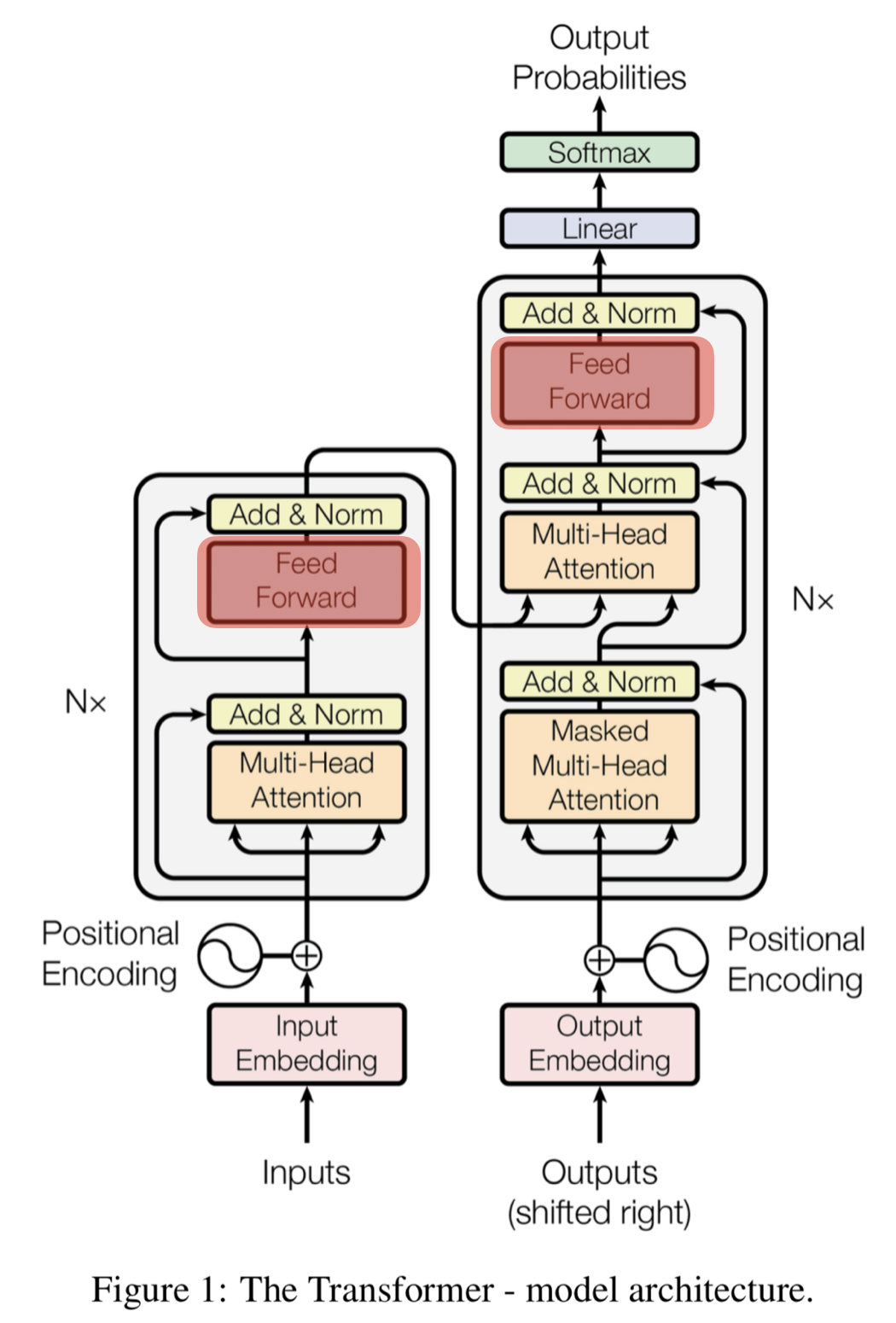
- 은닉층의 차원이 늘어났다가 다시 원래 차원으로 줄어드는 단순한 2층 신경망
- 활성화 함수로 ReLU 사용
def point_wise_feed_forward_network(d_model, dff): # d_model : 모델의 차원 # dff : 은닉층의 차원 수 return tf.keras.Sequential({ tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff) tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model) ])
-
Masked Self(Multi-Head) Attention
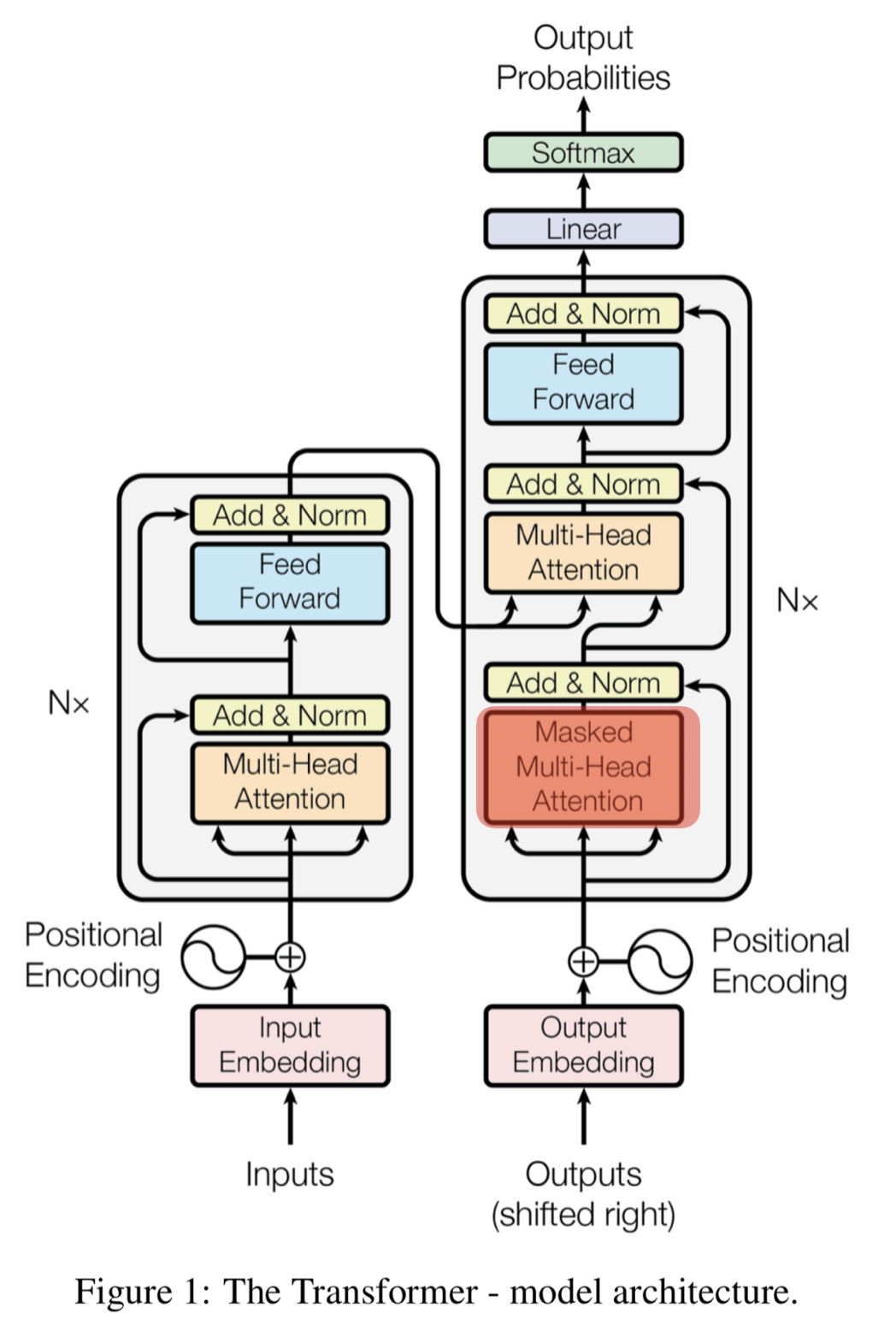
-
디코더 블록에서 사용되는 특수한 Self-Attention
-
디코더는 Auto-Regressive(왼쪽 단어를 보고 오른쪽 단어를 예측)하게 단어를 생성하기 때문에 타겟 단어 뒤에 위치한 단어는 Self-Attention에 영향을 주지 않도록 마스킹(masking)해야 함
- 정보 누수와 객관성 문제로 타겟 단어 뒤는 마스킹
Self-Attention (without Masking) vs Masked Self-Attention
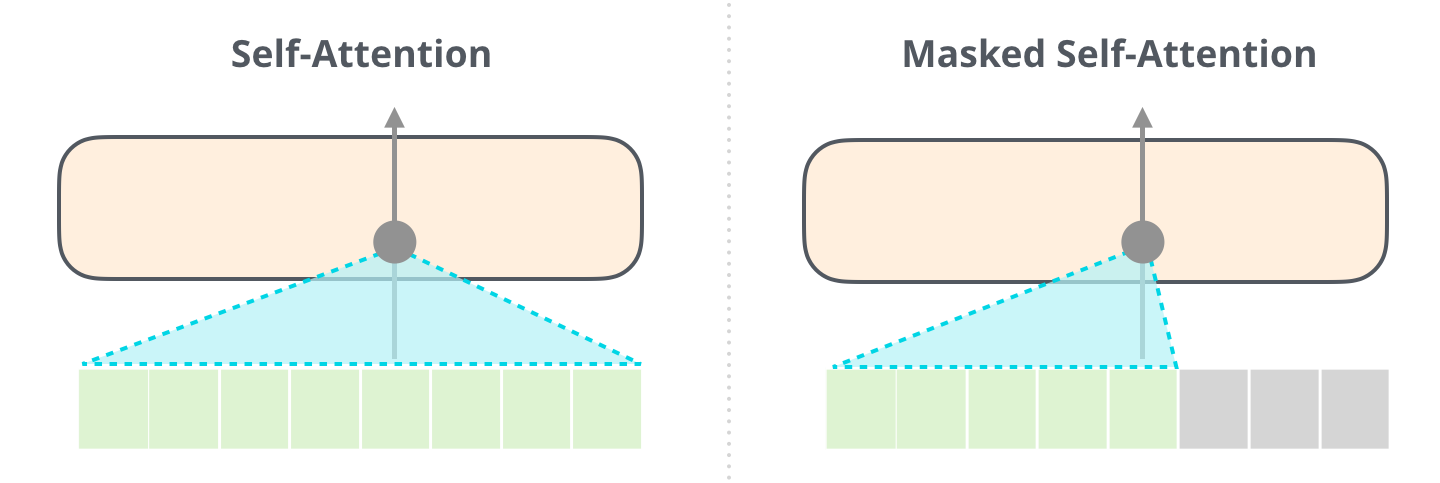
-
Masking : softmax를 취해주기 전 가려주고자 하는 요소에만 에 해당하는 매우 작은 수를 더해 줌
- 마스된 값은 softmax를 취해 주었을 때 0이 나오므로 value 계산에 반영되지 않음


- 마스된 값은 softmax를 취해 주었을 때 0이 나오므로 value 계산에 반영되지 않음
-
-
Encoder-Decoder Attention
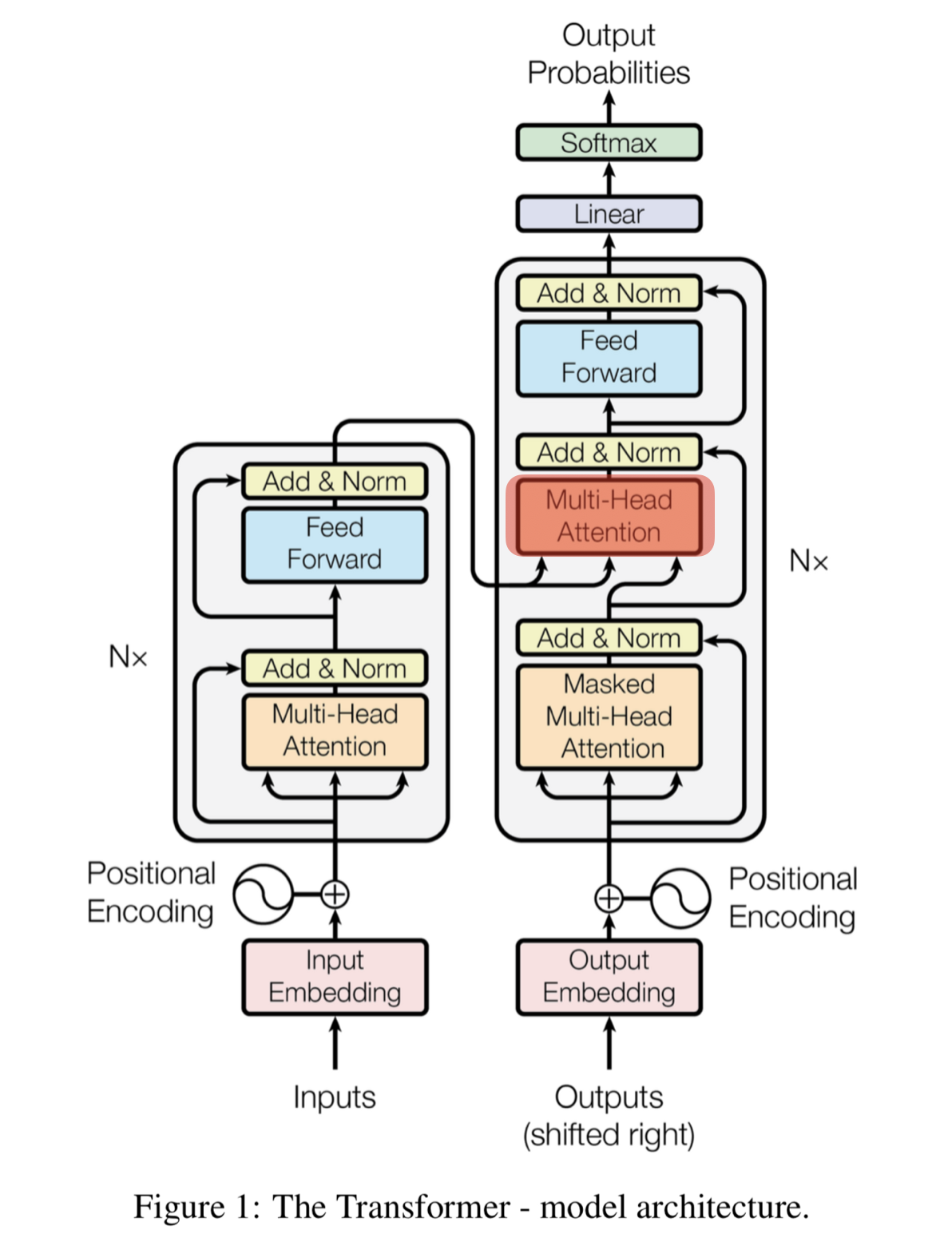
- 번역할 문장과 번역되는 문장의 정보 관계를 엮어주는 부분
- 다른 쿼리에 attention 하는 것
- 디코드 블록의 Masked Self-Attention으로부터 출력된 벡터를 쿼리 벡터로 사용
- 키(K), 밸류(V) 벡터는 최상위(=6번째) 인코더 블록에서 사용했던 값을 그대로 사용
-
Linear → Softmax
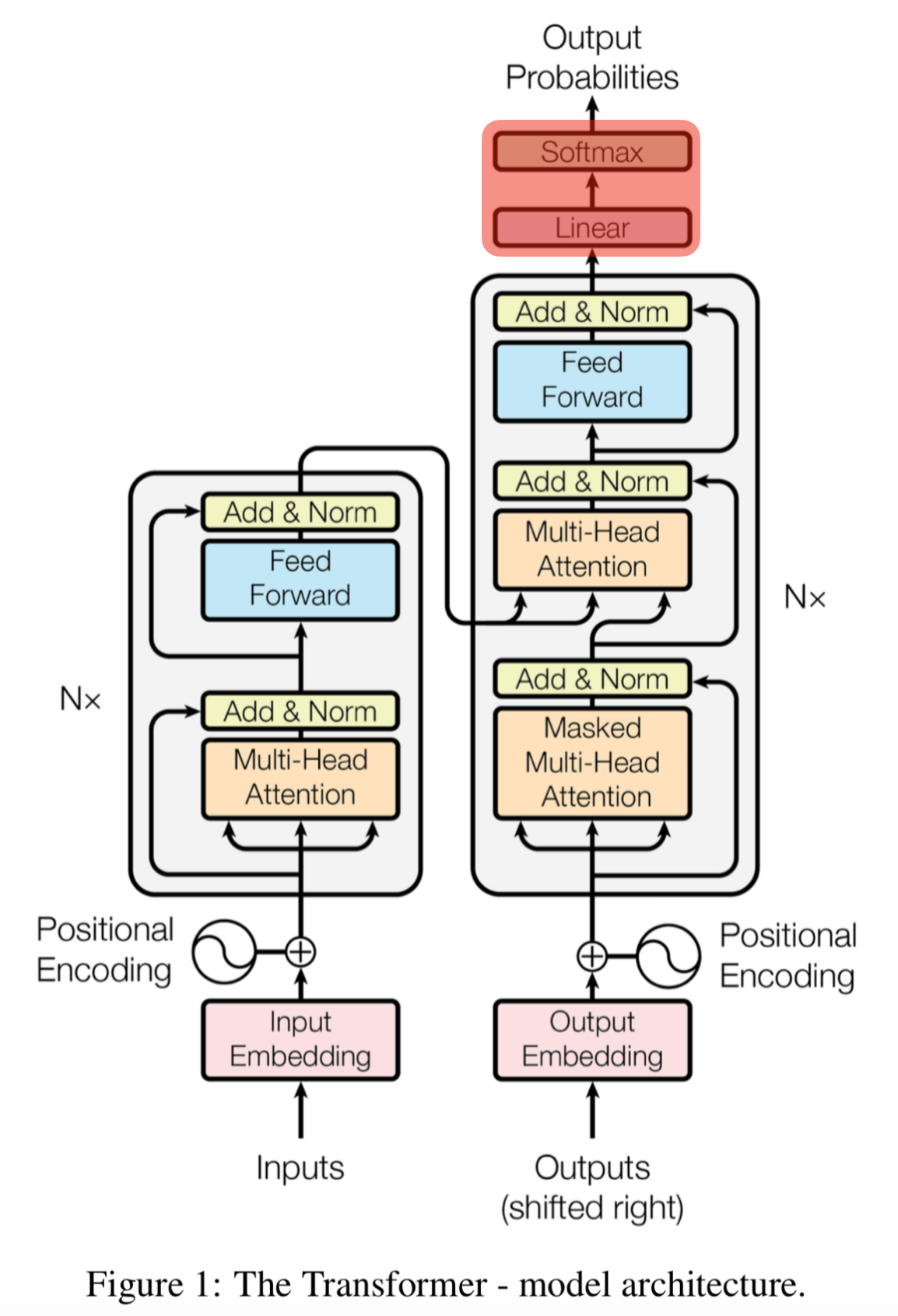
- 디코더의 최상층을 통과한 벡터들은 linear 층을 지난 후 softmax를 통해 예측할 단어의 확률을 구함