Day 1
CNN
CNN 이란?
- Convolutional Neural Network, 합성곱 신경망
- 컴퓨터 비전에서 자주 사용
- 학습과정에서 공간적 특성을 보존하면서 학습이 가능
- 이미지는 위치에 맞는 공간적인 특성을 가지고 있는데 모든 입력값을
flatten해주면 공간적 특성을 잘 살리지 못함 → 이러한 문제 해결 - 이미지의 일부를 훑으면서 연산이 진행되며 특징을 잡아내어 학습하기 때문에 층이 깊어지더라도 공간적 특성을 최대한 보존할 수 있음
- 이미지는 위치에 맞는 공간적인 특성을 가지고 있는데 모든 입력값을
- CNN 구조
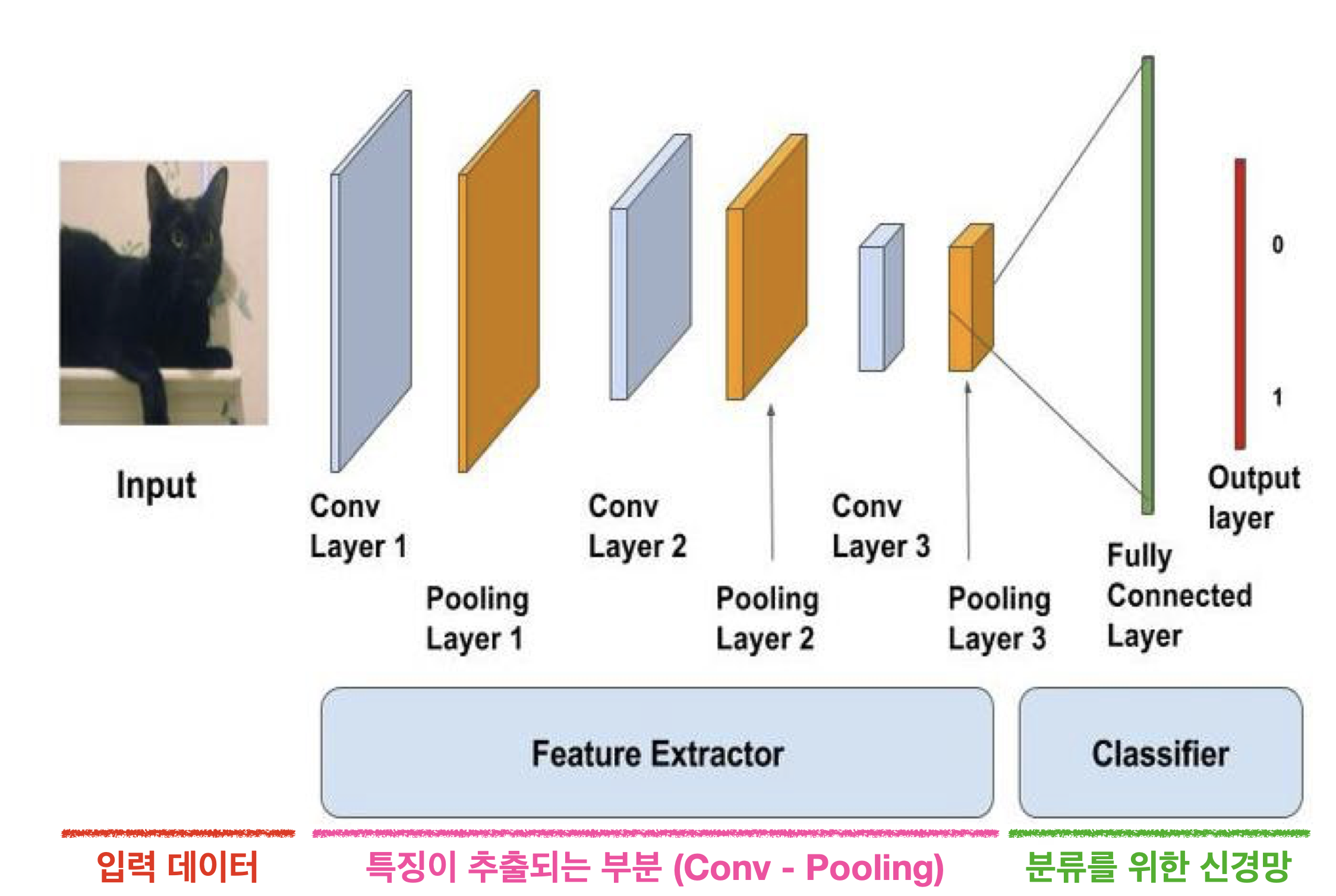
합성곱 층(Convolution Layer)
-
합성곱 필터(Convolution Filter)가 슬라이딩하며 이미지 부분부분을 읽어나감
-
합성곱 필터를 통해 좌측 상단부터 슬라이딩 시작
- 결과 값 = Feature map
- 필터 값은 가중치 초기화를 통해 랜덤 적용
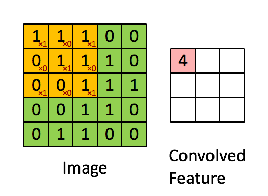
-
코너 값들이 반영이 덜 되고 feature map이 줄어드는 단점
↓ 극복
-
-
패딩(Padding)
-
이미지 외부를 특정 값으로 둘러싸서 처리해주는 방식
-
주로 제로-패딩(Zero-padding, 0으로 둘러싸주는 방식)이 많이 사용됨
-
연산되어 나오는 Feature map의 크기(=output)를 조절하고 실제 이미지 값을 충분히 활용하기 위해 사용
Nlp 에서의 padding 과 구분
-
-
스트라이드(Stride)
- 스트라이드를 조절하면 슬라이딩 시에 몇 칸씩 건너뛸지 정할 수 있음
- stride = 1
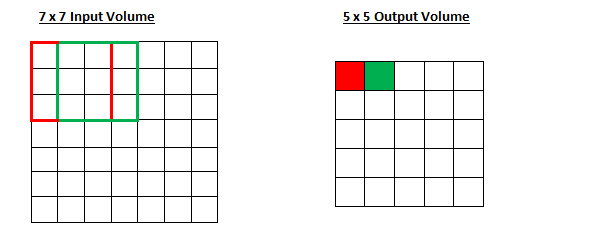
- stride = 2
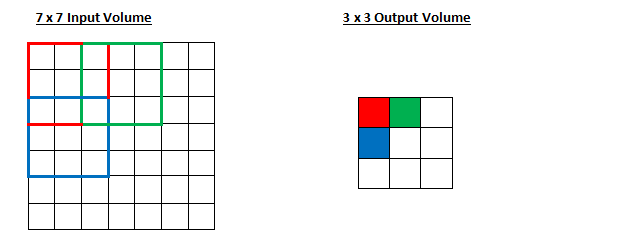
필터 크기, 패딩, 스트라이드에 따른 Feature map 크기 변화
- : 입력되는 이미지의 크기(=피처 수)
- : 출력되는 이미지의 크기(=피처 수)
- : 합성곱에 사용되는 커널(=필터)의 크기
- : 합성곱에 적용한 패딩 값
- : 합성곱에 적용한 스트라이드 값
소수점으로 나올 땐 버려지는 값이 생길 수도 있음 → 정보 손실 有 → 주의 필요
풀링 층(Pooling)과 완전 연결 신경망(Fully Connected Layer)
-
풀링(Pooling)
-
가로, 세로 방향의 공간을 줄이기 위해 수행
-
풀링 층은 학습해야 할 가중치(=필터)가 없고 채널 수(=필터 개수)가 변하지 않음
-
과적합 방지
-
최대 풀링(Max pooling) : 정해진 범위 내에서 가장 큰 값을 꺼내오는 방식
- 이미지를 처리할 때에는 각 부분의 특징을 최대로 보존하기 위해 최대 풀링 많이 사용
-
평균 풀링(Average pooling) : 정해진 범위 내에 있는 모든 요소의 평균을 가져오는 방식

-
-
완전 연결 신경망(Fully Connected Layer)
- Dense 층과 같음
- CNN에서는 Convolution 층에 있는 Filter 가중치를 학습
model.add(Conv2D(32, (3,3), padding = 'same', activation='relu'))
# 32 : 필터 수, (3,3) : 필터 크기
# padding = '' : 'valid'(default) or 'same', padding = 'same' 이고 strides = 1 이면 인풋 크기와 아웃풋 크기가 동일해짐, strides = 2 일때 모서리 부분에서 일부분만 데이터가 있을 경우 valid면 해당 데이터는 버려지고, same의 경우 데이터가 없는 부분에만 zero-padding이 생겨 데이터 손실 방지해줌
model.add(Flatten())
# 단지 Dense layer에 연결해주기 위한 용도로 대신 GlobalAveragepooling2D() 사용하기도 함전이 학습(Transfer Learning)
- 대량의 데이터를 학습한 사전 학습 모델의 가중치를 그대로 가져온 뒤 완전 연결 신경망 부분만 추가로 설계하여 사용
- 사전학습 모델
- 사전에 미리 학습된 모델
- 대량의 데이터로 학습한 모델
- 사전학습 모델
- 사전 학습 가중치는 학습되지 않도록 고정(
freeze)한 채로 진행되기 때문에 빠르게 좋은 결과 얻을 수 있음- 가중치를 고정함으로써 내 데이터가 적더라도 어느 정도 보완이 가능
- 이미지 분류를 위한 주요 사전 학습 모델
- VGG
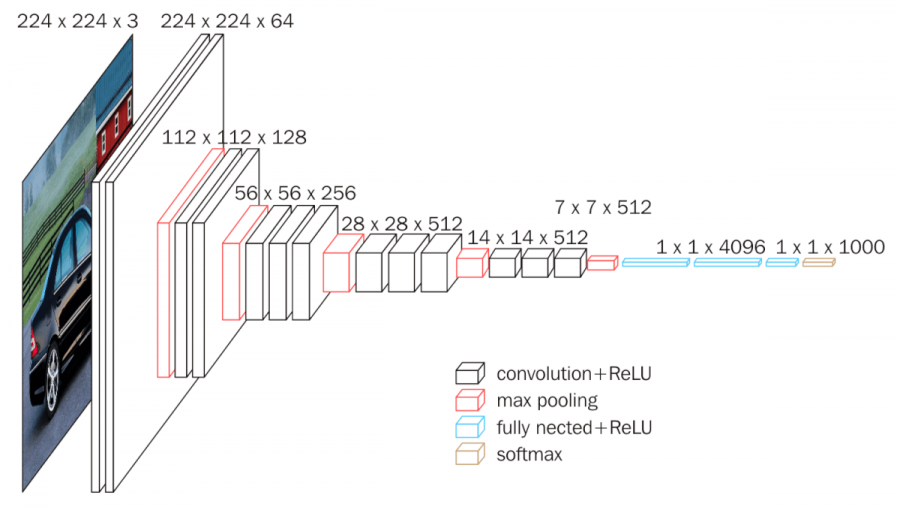
- 모든 합성곱 층에서 3 X 3 크기의 필터 사용 → 층을 깊게 쌓아 기존의 더 큰 크기의 필터 이상의 표현력을 가짐
- 활성화 함수로 ReLU를 사용, 가중치 초깃값으로는 He 초기화 사용 → 기울기 소실 문제가 발생 X
- 완전 연결 층에 드롭아웃을 사용하여 과적합 방지, 옵티마이저는 Adam사용 → 전이학습시엔 효과가 없음(완전연결신경망에서 사용하는 것이기 때문)
- CNN과 유사하고 간단해서 많이 사용
- GoogLeNet(Inception)
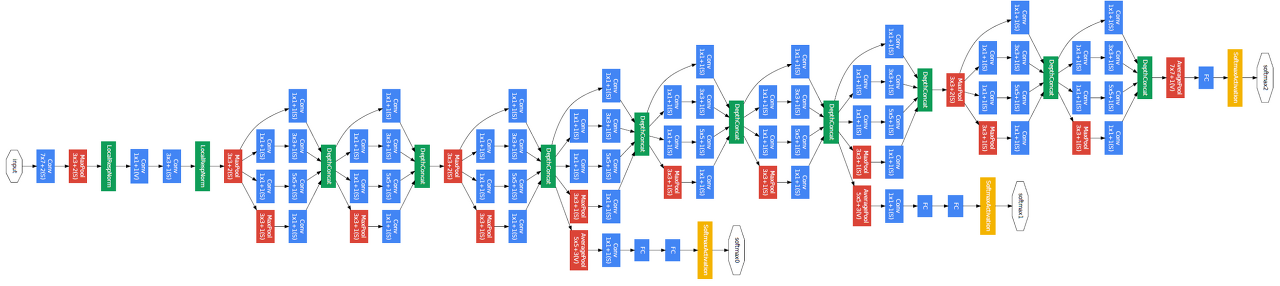
- 세로 방향의 깊이 + 가로 방향의 깊이 모두 넓은 신경망 층을 가지고 있음
- 신경망 깊이 = 세로 방향 + 가로 방향
- 가로 방향 → 인셉션 구조
- 크기가 다른 필터와 풀링을 병렬적으로 적용한 뒤 결과를 조합
- 병렬적으로 적용하기 때문에 다양한 특징을 추출할 수 있음
- ResNet
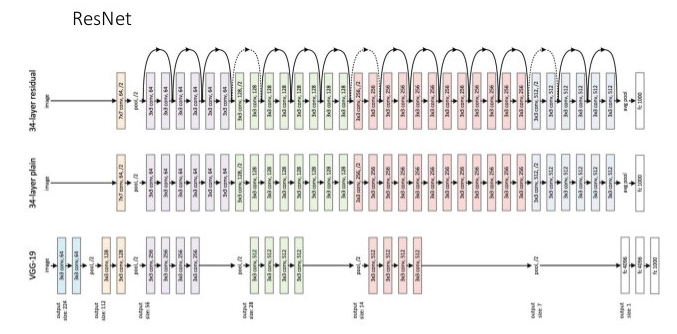
- 층을 넘어 이어지는 화살표 : Residual Connection(=Skipped Connection)
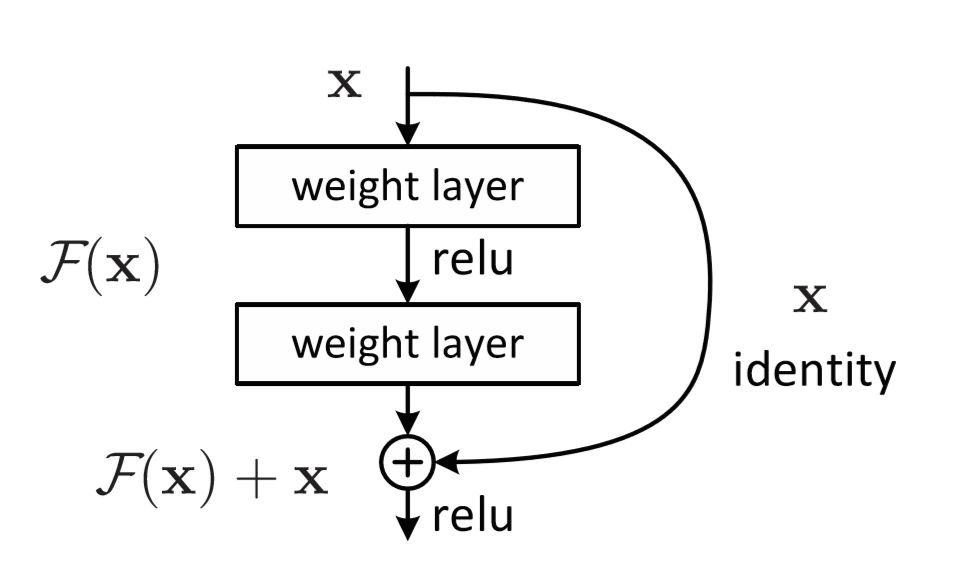
- 층을 거친 데이터의 출력에 거치지 않은 출력을 더함
→ 역전파 과정에서 미분을 적용하더라도 1 이상의 값으로 보존되어 기울기 소실 문제를 해결할 수 있음
- 층을 거친 데이터의 출력에 거치지 않은 출력을 더함
- 층을 넘어 이어지는 화살표 : Residual Connection(=Skipped Connection)
- VGG
이미지 데이터 증강(Image Data Augmentation)
- 회전, 반전, 자르기, 밝기 혹은 채도 변화 등을 통해 데이터를 늘리는 방법
- 이미지 데이터 증강 : 사람처럼 일반화가 잘 되는 모델을 만들기 위해서 학습 데이터셋에 있는 이미지를 일부러 회전하거나 기울이는 등의 방법
- 이미지 증강을 통해 더욱 강건(Robust)한 모델을 만들 수 있음
- 이미지 변화를 통해 데이터 양을 늘려 B컷, C컷 등등도 컴퓨터가 이해할 수 있도록 함
Day 2
Beyond Classification
분할(Segmentation)
- 하나의 이미지에서 같은 의미를 가지고 있는 부분을 구분해 내는 Task
- 의료이미지, 자율주행, 위성 및 항공사진등의 분야에서 사용
- 이미지 분류에서는 이미지를 하나의 단위로 레이블을 예측, segmentation에서는 더 낮은 단위로 분류
- 동일한 의미마다 해당되는 픽셀이 모두 레이블링 되어 있는 데이터셋을 픽셀 단위에서 레이블을 예측
- Semantic Segmentation(의미적 분할) vs (Semantic) Instance Segmentation
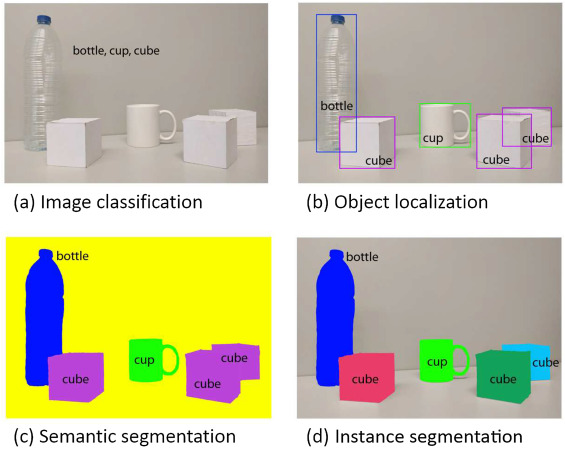
분할 모델
-
FCN(Fully Convolutional Networks)
- 이미지 분류를 위한 신경망에 사용되었던 CNN의 분류기 부분(=완전 연결 신경망)을 합성곱 층으로 대체한 모델
- segmentation은 픽셀 단위로 분류가 이루어지기 때문에 픽셀의 위치 정보를 끝까지 보존
- 기존 CNN에서 사용하였던 완전 연결 신경망은 위치 정보를 무시한다는 단점
- FCN에서는 이를 합성곱 층으로 모두 대체함으로써 문제 해결
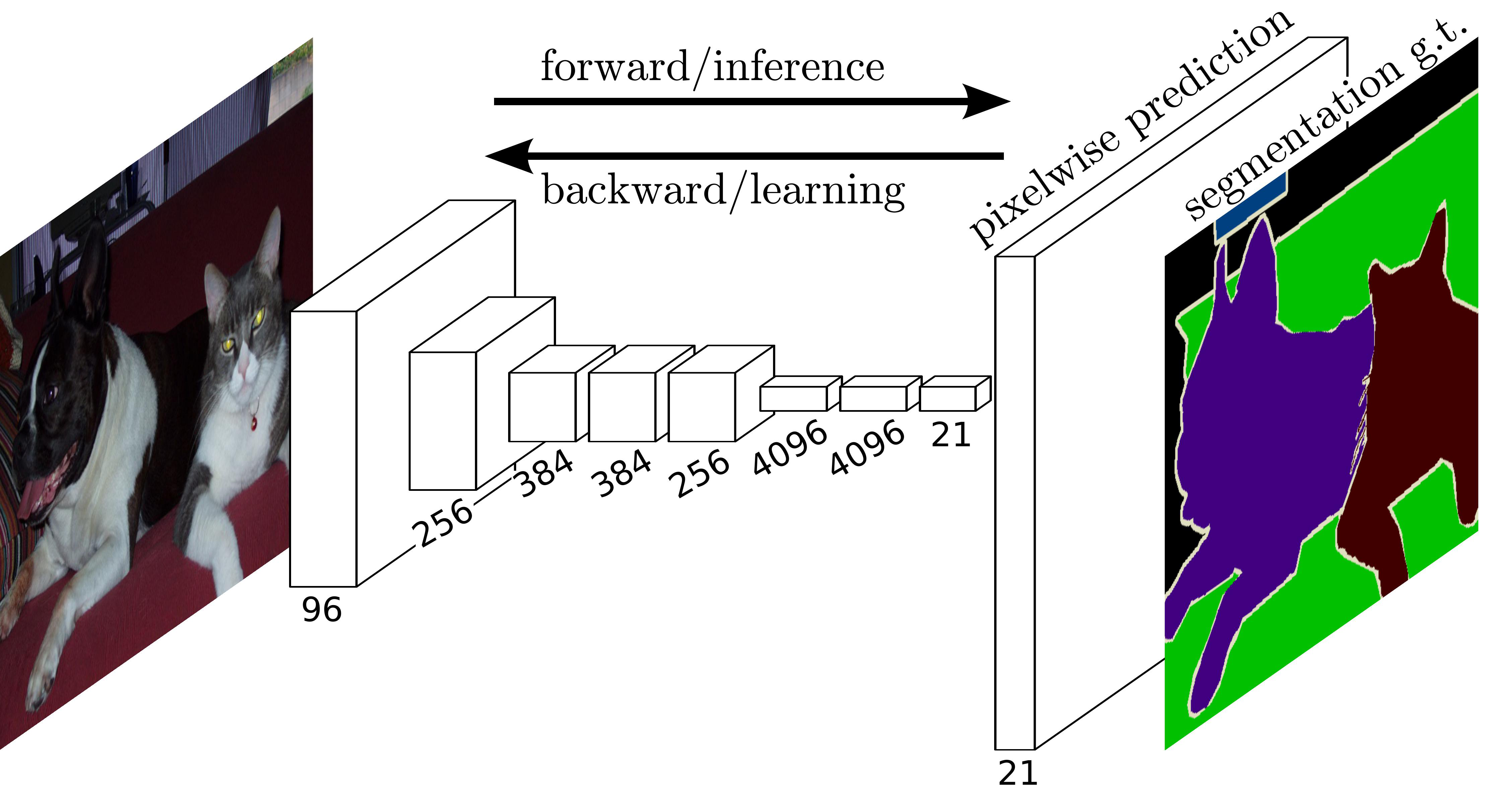
21의미 : 분류 클래스 수- 갑자기 이미지의 크기가 커지는 부분
- segmentation은 픽셀별로 분류를 진행하기 때문에 원래 이미지와 비슷하게 크기를 키워주는 Upsampling 해줘야 함
- Upsampling
- Downsampling
- CNN에서 사용되는 것처럼 Convolution과 Pooling을 사용하여 이미지의 특징을 추출하는 과정
- 원래 이미지의 크기로 키우는 과정
Transpose Convolution적용- 각 픽셀에 커널을 곱한 값에 stride를 주어 나타냄으로써 이미지 크기를 키워냄
- Downsampling
-
U-net
- segmentation 을 위한 대표적인 모델
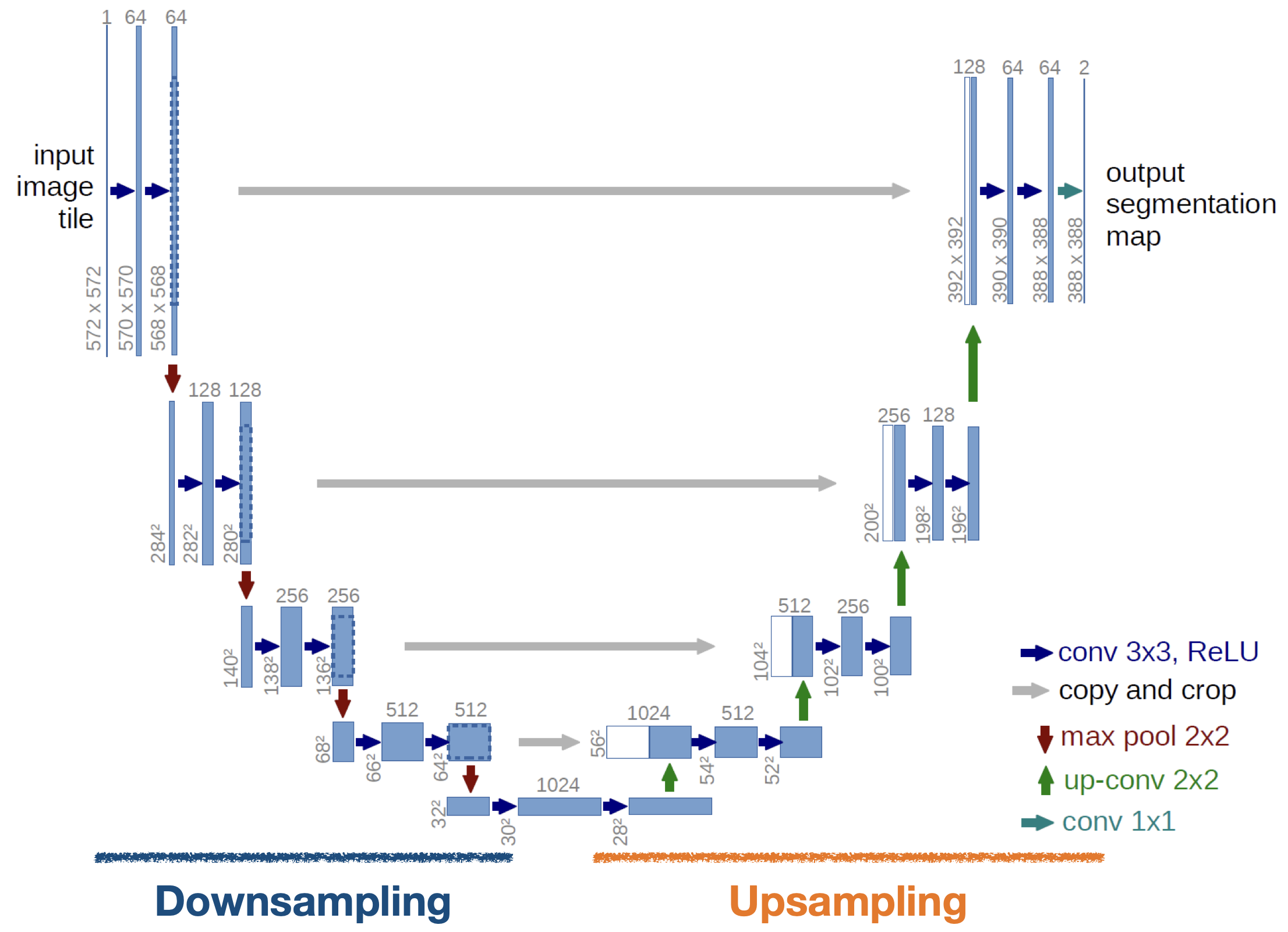
- out segmentation map 의
2의미 : 분류 클래스 수 - 왼쪽과 오른쪽 바의 길이/크기가 다른 이유 : zero-padding을 사용하지 않고 mirroring padding을 사용하는데 mirroring padding은 이미지 크지를 보존해주지 않음
- out segmentation map 의
- Downsampling에서는 이미지의 특징을 추출, Upsampling에서는 원본이미지와 비슷한 크기로 복원
- 추가적으로 Upsampling에서 Downsampling 출력으로 나왔던 feature map을 적당한 크기로 잘라서 붙여준 뒤 추가 데이터로 사용(→ 회색 화살표)
- segmentation 을 위한 대표적인 모델
객체 탐지/인식(Object Detection/Recognition)
-
전체 이미지에서 레이블에 맞는 객체를 찾아내는 Task
-
자율주행을 위한 인공지능 기술로 사용
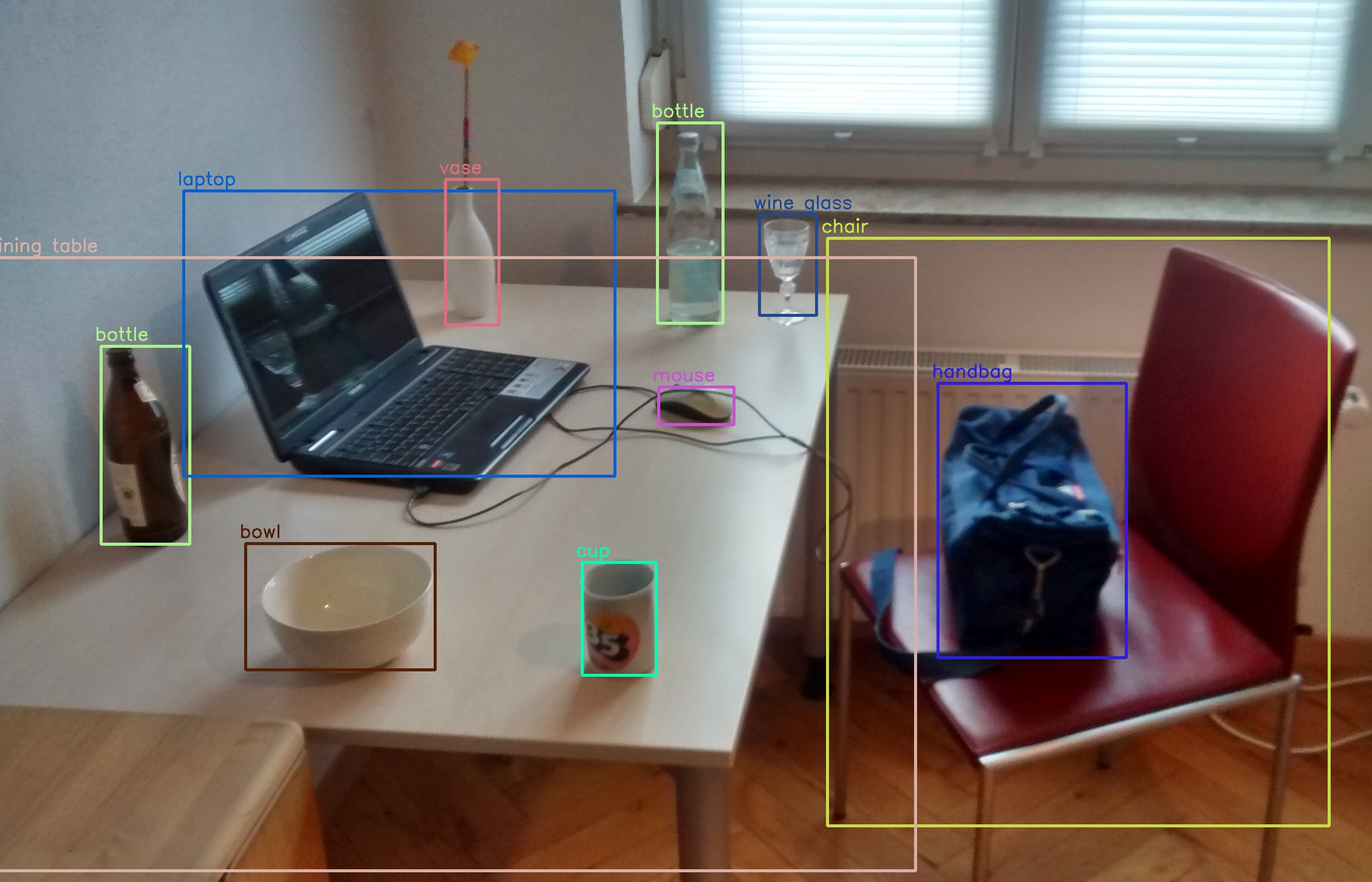
- 객체 경계에 Bounding Box라고 하는 사각형 박스를 만든 후, 박스 내의 객체가 속하는 클래스가 무엇인지 분류
-
IoU(Intersection over Union)
- 객체 탐지 평가 지표

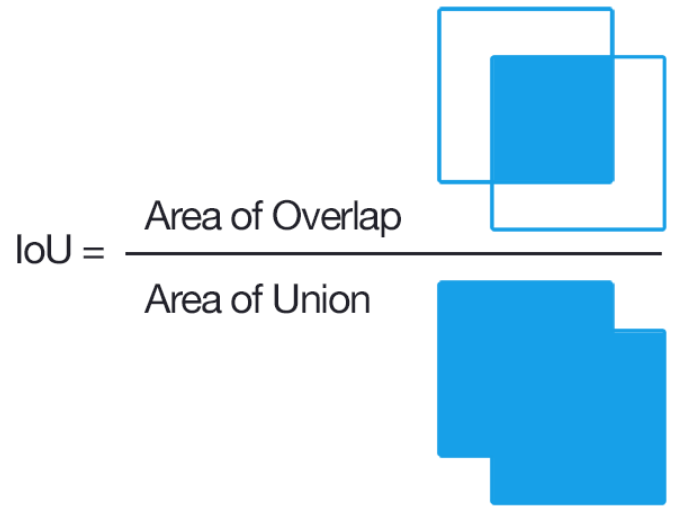
- 객체 탐지 평가 지표
-
객체 탐지 모델
-
Bounding box를 어떻게 쳐주냐에 따라 two stage, one stage로 나뉨
-
Two stage detector
- 일련의 알고리즘을 통해 객체가 있을 만한 곳을 추천(Region proposal)받은 뒤에 추천 받은 Region, RoI(Region of Interest)에 대해 분류를 수행하는 방식
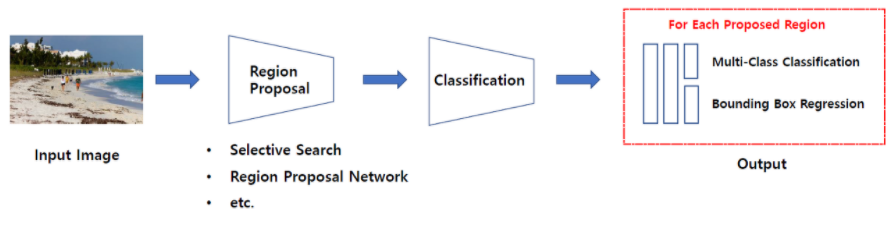
- 대표적으로 R-CNN계열 모델
- 일련의 알고리즘을 통해 객체가 있을 만한 곳을 추천(Region proposal)받은 뒤에 추천 받은 Region, RoI(Region of Interest)에 대해 분류를 수행하는 방식
-
One stage detector
- 특정 지역을 추천받지 않고 입력 이미지를 Grid 등의 같은 작은 공간으로 나눈 뒤 해당 공간을 탐색하며 분류를 수행하는 방식
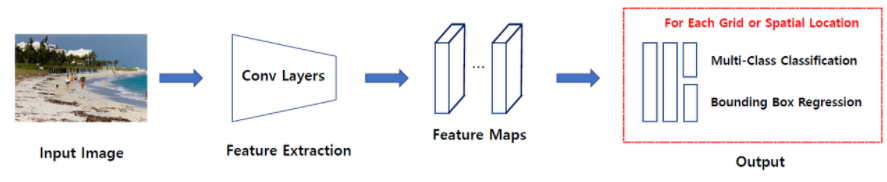
- 대표적으로 SSD(Single Shot multibox Detector)계열, YOLO(You Only Look Once)계열
- Two stage 보다 빠름
- 특정 지역을 추천받지 않고 입력 이미지를 Grid 등의 같은 작은 공간으로 나눈 뒤 해당 공간을 탐색하며 분류를 수행하는 방식
-
Day 3
AutoEncoder
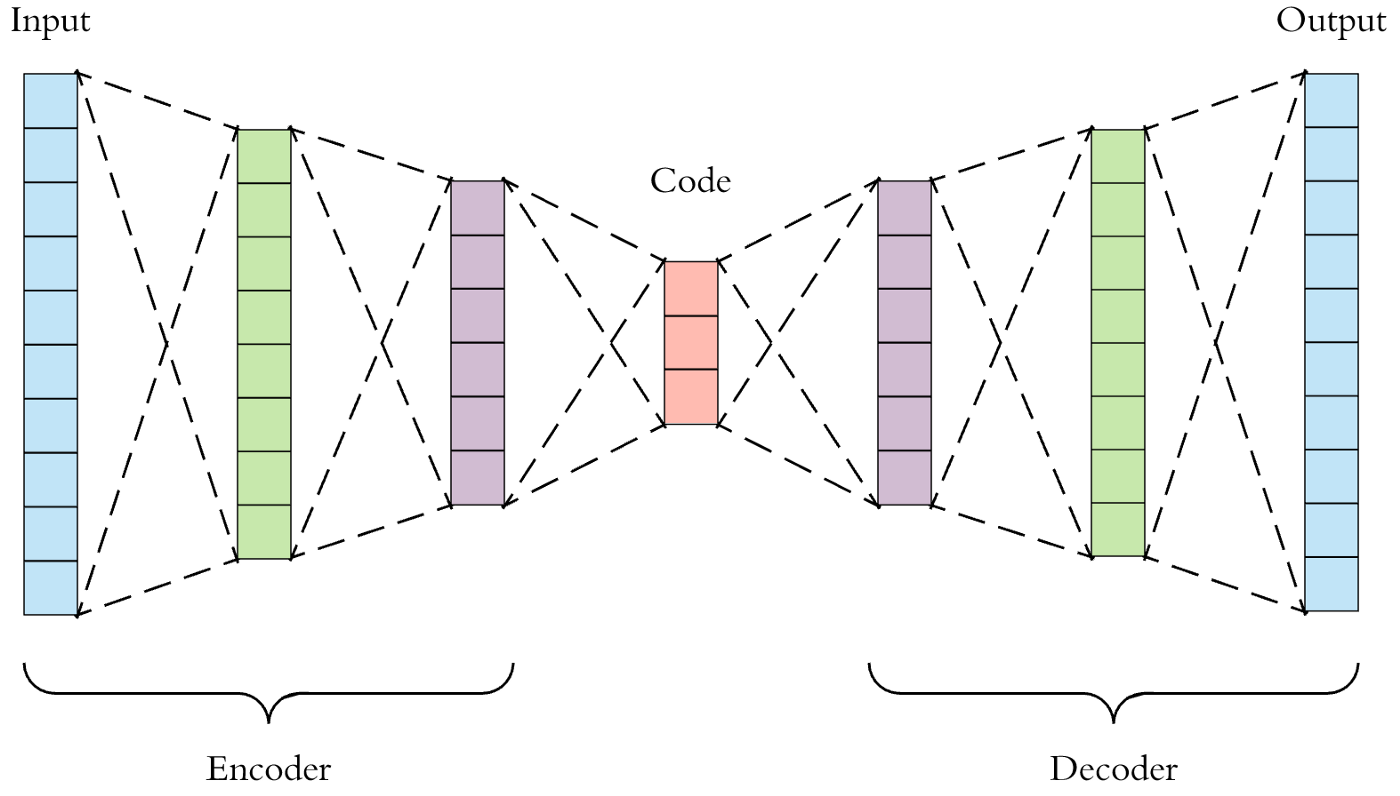
-
AutoEncoder는 잠재 벡터를 잘 얻기 위한 방법
-
입력 데이터를 저차원의 벡터로 압축한 뒤 원래 크기의 데이터로 복원하는 신경망
Latent(잠재) 벡터
- 원본 데이터보다 차원이 작으면서도 원본 데이터의 특징을 잘 보존하고 있는 벡터
- 잠재 벡터의 크기는 원본 데이터보다 작기만 하면 ok → 사용자 지정Encoder
- 입력데이터를 저차원 벡터로 축소
- 차원의 저주를 방지하기 위해
- 마음대로 축소 가능 → why? → Manifold Learning
Decoder
- 차원을 원래 크기로 복원
- 입력데이터를 저차원 벡터로 축소
-
인코더에서 차원을 줄였는 데 다시 디코더로 차원을 늘려주는 이유
→ 특징 보존이 끝이 아니라 특징이 잘 보존 되었는지 확인하기 위함 -
활용
- 차원 축소(Dimensionality Reduction)와 데이터 압축
- 데이터 노이즈 제거(Denoising)
- 이상치 탐지(Anomaly Detection)
-
예제 1 → 비지도학습
Latent_Dim = 64 # 잠재 벡터의 차원 수 정의 class Autoencoder(Model): def __init__(self, latent_dim): super(Autoencoder, self).__init__() self.latent_dim = latent_dim self.encoder = tf.keras.Sequential([ layers.Flatten(), # MNIST 데이터 사용해서 flatten layers.Dense(latent_dim, activation='relu'), # 잠재벡터 차원으로 축소 ]) self.decoder = tf.keras.Sequential([ layers.Dense(784, activation='sigmoid'), # 원본 데이터 차원수로 확대 layers.Reshape((28,28)) # flatten 한거 다시 복구 def call(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return decoded model = Autoencoder(Latent_Dim) model.compile(optimizer='adam', loss='mse') model.fit(x_train, x_train, epochs=10, shuffle=True, validation_data=(x_test, x_test)) -
예제 2 : DAE(Denoising AutoEncoder) → 안개가 있는 환경에서 사람인지 안개인지 확인
-
Conv2D사용 → Convolutional AutoEncoder# Random Noise 추가 noise_factor = 0.2 # 0.2, 0.25 가 성능이 가장 좋음 x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape) x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape) x_train_noisy = tf.clip_by_value(x_train_noisy, clip_value_min=0., clip_value_max=1.) x_test_noisy = tf.clip_by_value(x_test_noisy, clip_value_min=0., clip_value_max=1.) #DAE 모델 구축 class Denoise(Model): def __init__(self): super(Denoise, self).__init__() self.encoder = tf.keras.Sequential([ layers.Input(shape=(28, 28, 1)), layers.Conv2D(16, (3,3), activation='relu', padding='same', strides=2), layers.Conv2D(8, (3,3), activation='relu', padding='same', strides=2)]) self.decoder = tf.keras.Sequential([ layers.Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'), layers.Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'), layers.Conv2D(1, kernel_size=(3,3), activation='sigmoid', padding='same')]) def call(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return decoded model = Denoise() model.compile(optimizer='adam', loss='mse') # 입력데이터는 noise 있는 데이터, 타겟데이터는 원본 이미지 model.fit(x_train.noisy, x_train, epochs=10, shuffle=True, validation_data=(x_text_noisy, x_test)) -
Dropout으로Noise처럼 사용 가능
-
-
예제 3 : 이상치 탐지 → 산불 감지
-
AutoEncoder는 특정 데이터의 중요 특징, 즉 잠재 벡터를 바탕으로 다시 원본 데이터로 복원할 때에 발생하는 오류, 즉 복원 오류(Reconstruction Error) 를 최소화 하도록 훈련
-
정상 데이터로만 훈련한 뒤에 비정상 데이터셋을 복원한다면 복원 오류가 커짐
-
복원 오류가 특정한 임계값을 초과하는 경우 해당 데이터를 비정상으로 판단 할 수 있음
-
임계값 = 정상데이터셋에 대한 복원 오류 평균 + 표준편차
# 정상 데이터셋과 비정상 데이터셋 분리 # 모델 학습 시에는 데이터셋에서 레이블이 '1' 로 지정된 정상 데이터만 사용 train_label = train_label.astype(bool) test_label = test_label.astype(bool) normal_train_data = train_data[train_label] normal_test_data = test_data[test_label] anomalous_train_data = train_data[~train_label] anomalous_test_data = test_data[~test_label] # AutoEncoder 모델 구축 # 학습 시에는 정상데이터만 사용해야 함 class AnomalyDetector(Model): def __init__(self): super(AnomalyDetector, self).__init__() self.encoder = tf.keras.Sequential([ layers.Dense(32, activation="relu"), layers.Dense(16, activation="relu"), layers.Dense(8, activation="relu")]) self.decoder = tf.keras.Sequential([ layers.Dense(16, activation="relu"), layers.Dense(32, activation="relu"), layers.Dense(140, activation="sigmoid")]) # 마지막 층은 원본 데이터의 차원 수와 동일하게 맞추어줍니다. def call(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return decoded model = AnomalyDetector() model.compile(optimizer='adam', loss='mae') model.fit(normal_train_data, normal_train_data, epochs=20, batch_size=512, validation_data(test_data, test_data), shuffle=True) # 이상치로 분류하는 함수 def predict(model, data, threshold): reconstructions = model(data) loss = tf.keras.losses.mae(reconstructions, data) return tf.math.less(loss, threshold)
-
MinMaxScaling 방식의 정규화
- 표준화 방법 중 하나로 각 특성의 단위를 맞춰줌, 데이터를 0-1 사이로 맞춤
- 이상치에 굉장히 예민하기 때문에 예제에서처럼 이상치 탐지가 목적인 경우에 사용
Standard Scaler
- 이상치가 있어도 괜찮음
이상치 탐지 이유
- 정상 데이터셋에서도 이상치가 있지만 정상/비정상에서도 특정한 애들을 구별해서 더 집중하기 위함
- 1종 오류, 2종 오류 분류
- 평가지표에
Accuracy뿐만 아니라Recall과Precision도 함께 봄
Manifold
- AutoEncoder는 데이터가 펴져있는 공간상에서 데이터의 매니폴드를 찾아내어 학습하는 과정
- 매니폴드는 고차원 공간에서 데이터가 이루는 저차원의 공간을 의미, ex. Swiss-roll
- 매니폴드 학습은 매니폴드 공간을 찾는 것을 의미
https://deepinsight.tistory.com/124
Day 4
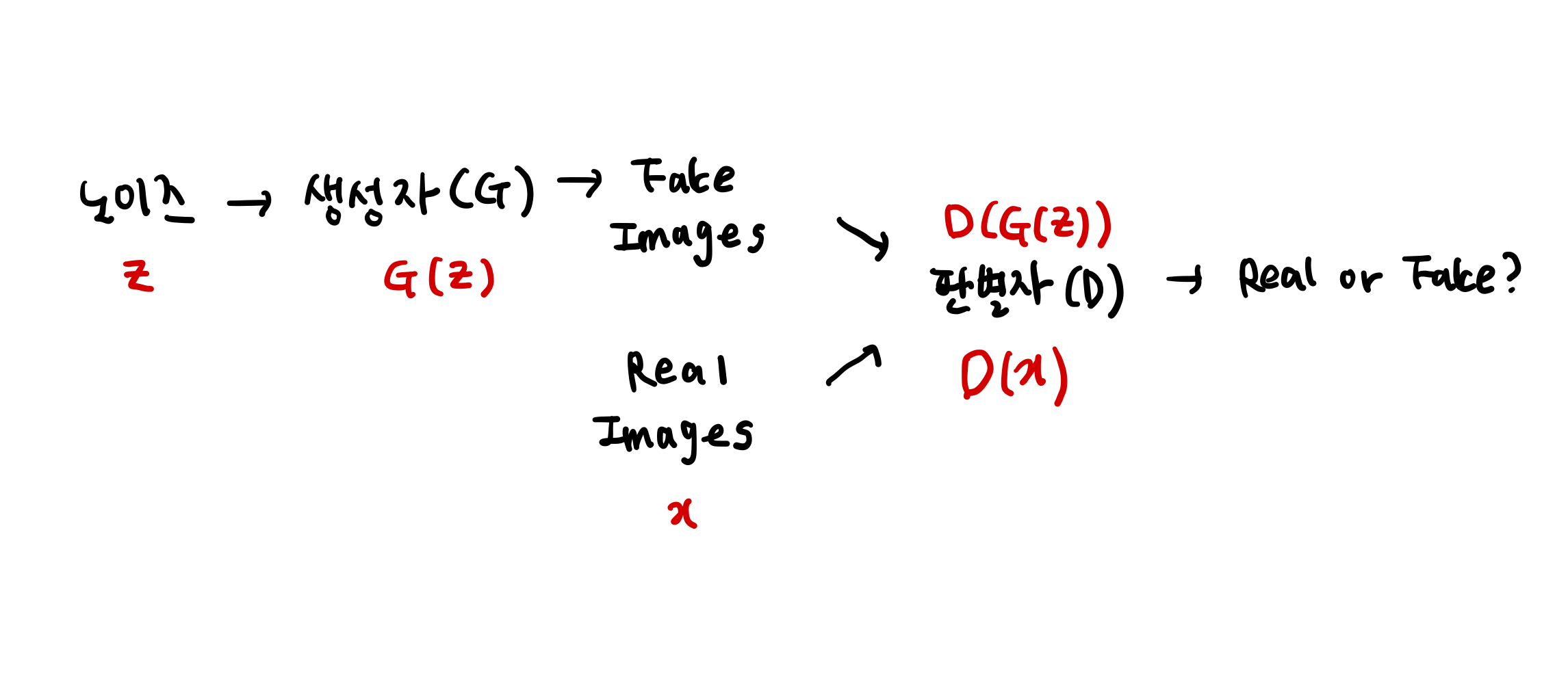
GAN(Generative Adversarial Networks, 생성적 적대 신경망)
- 딥페이크의 기반
- 실제와 유사한 데이터를 만들어내는 생성모델
- 생성자(
Gernerator)- Random Noise로부터 실제와 동일한 데이터를 만듦
- 비지도학습
- 판별자(
Discriminator)- 생성된 데이터가 진짜인지 가짜인지 판별
- 지도학습
예시 : DCGAN(Deep Convolution GAN)
-
Convolution Layer로 이루어짐
-
손실함수

- 판별자의 손실함수는
real_loss와fake_loss를 더한 값- 판별자는 손실함수 값을 최대로 = 0 이 나오게 하는 게 목적
real_loss: 전체가 1인 행렬과real_output을 비교fake_loss: 전체가 0인 행렬과fake_output을 비교
- 생성자 손실함수는 전체가 1인 행렬과
fake_output을 비교- 생성자는 손실함수 값이 최소로,
- 판별자의 손실함수는
Cycle GAN
- DCGAN의 구조를 변경하여 만든 새로운 구조
- 특정 이미지 도메인의 특성을 다른 이미지에 적용하는 작업 가능
- ex. 과일 색 변경, 계절 변경
- 서로 변환하고 싶은 두 스타일의 이미지를 따로 구하더라도 좋은 성능
- 비슷한 작업을 수행하는
Pix2Pix는 train 셋을 구성할 때 레이블에 해당하는 데이터를 무조건 짝지어 주어야 함
- 비슷한 작업을 수행하는
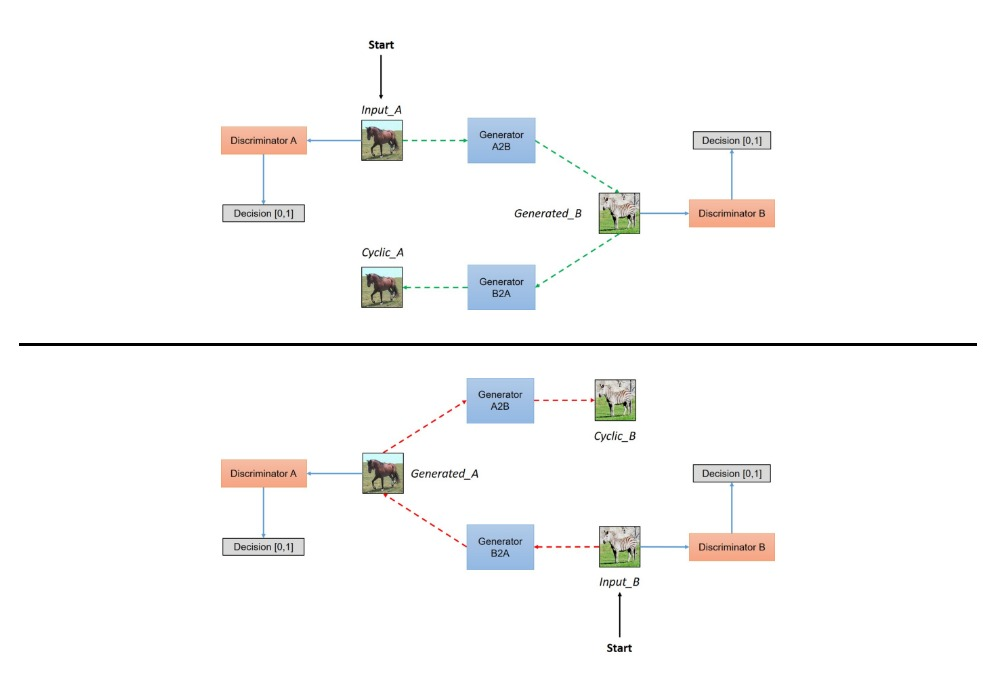
- 2개의 생성자
- 각각의 생성자는 A → B, B → A로 이미지 변경
- 2개의 판별자
- 각각의 판별자는 A, B에 대해 Real/Fake 판단
- 1:1 매칭을 통한 이미지 학습이 아니기 때문에 이미지를 변화하는 과정에서 Input 정보가 유실되어 원본 이미지의 특성을 잃어버리게 될 수 있음
- 때문에 원본 데이터로 돌아갈 수 있을 정도로만 변환을 진행하기 위해 Cycle 구조를 가지게 됨
- 2개의 결과물
