RNN (Recurrent Neural Network)
: Sequential data(순서가 있는 데이터) 의 특성을 추출하는데 좋은 성능을 보이는 Recurrent Layer를 Feature Extractor로 사용하는 딥러닝 모델.
🧱 Recurrent Layer 구조
RNN은 순서대로 입력되는 데이터를 반복 처리하는 Recurrent Layer를 이용해 순서를 감안해서 Feature vector를 추출하고 그 Feature vector를 Estimator Layer에 전달해 추론한다. (이건 뒤에서 더 자세하게 다룰 예정)
💡 즉, 순서를 감안한다는 것은 이전 순서의 내용을 기억한다는 것, 즉 memory system이 존재한다!

🧱 1. RNN은 어떤 구조인가요?
기본적으로는 선형 레이어(Linear Layer)처럼 생겼지만, 거기에 “자기 자신을 반복해서 참조하는 구조”가 들어간 것이 RNN입니다.
이걸 우리는 “재귀 순환 구조”라고 부릅니다.
아래 그림으로 함께 설명해보겠습니닷 !
구조 1. 순차 구조를 인식하면 콘텍스트를 기억하는 순환 신경망
순환 신경망은 데이터의 순차 구조를 인식하기 위해 데이터를 시간 순서대로 하나씩 입력받는다. 그리고 순서대로 입력받은 데이터의 콘텍스트를 만들기 위해 은닉 계층에 피드백 연결을 가진다.
왼쪽 그림은 은닉 계층에 피드백 연결을 갖는 모델 구조이고, 오른쪽 그림은 모델이 데이터를 처리하는 과정을 시간 순서에 따라 펼쳐서 보여준다.
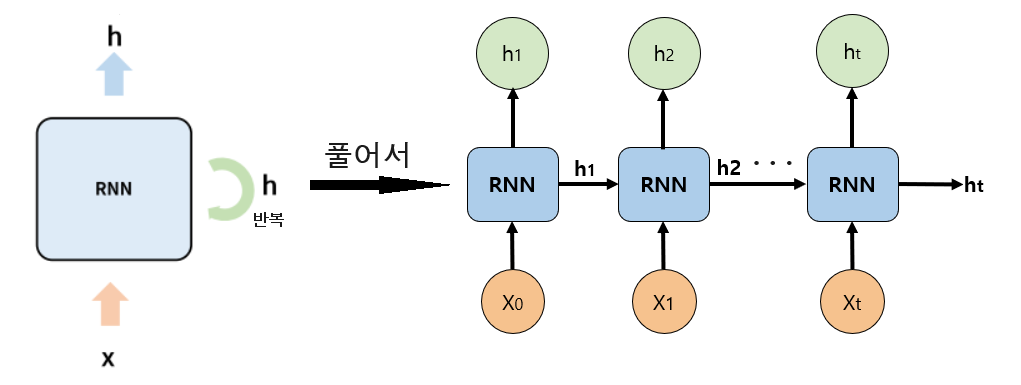
그럼 오른쪽 그림을 더 확대해서 보자!
일단 시간 순서에 따라 하나씩 입력을 받으니까, 아래 네모칸 하나를 하나의 time step이라고 보면 된다.
그럼 하나의 네모 칸 안에서는 무슨일이 일어나냐면!
일단, 각 시점(time step)에서 다음 두 가지를 입력으로 받아요:
1. 현재 시점의 입력 𝑋𝑡 예: 지금 단어, 지금 시점의 주가, 현재 시계열 값 등
2. 이전 시점까지의 결과 ℎ𝑡−1 예: 그 전에 들었던 단어들의 의미를 담고 있는 기억 (ℎ𝑡−1는 hidden state, 즉 “이전 기억” 이라고 불러요.)
🧠 Hidden State란? =기억
지금까지 들어온 입력들의 내용을 종합해서 요약한 벡터!

⚙️ 계산식은 다음과 같다.
- : 현재 입력 에 곱해지는 가중치 행렬
- : 이전 hidden state 에 곱해지는 가중치 행렬
- : 바이어스(bias)
- : 비선형 활성화 함수, 결과를 -1에서 1 사이로 압축함
즉, 현재 입력과 이전의 기억을 합쳐서, 새로운 출력을 만들어내는 구조입니다.
이렇게 계산된 는 현재 시점의 출력값이자 다음 시점의 입력값으로 사용됩니다.
그럼 여기서 궁금한 게 생길 수 있는데,,,
💡 랑 의 가중치는 어떤 차이가 있는걸까?
RNN은 모든 time step에서 랑 같은 가중치를 사용한다.
따라서, 시간 순서가 길어져도 모델의 복잡도는 늘어나지 않음 (공유된 파라미터 덕분에)
2. 🔄 Bidirectional RNN (양방향 순환 신경망)
✅ 기본 아이디어
"문장의 앞도 중요하지만, 뒤의 문맥도 함께 고려하면 더 정확한 이해가 가능하다!"
일반 RNN은 앞에서 뒤로 한 방향으로만 데이터를 처리합니다. 하지만 어떤 단어의 의미는 앞뒤 문맥을 모두 봐야 정확히 알 수 있죠?
예를 들어:
“나는 배를 탔다.” → 여기서 '배'는 타는 배
“나는 배를 먹었다.” → 여기선 과일 배
이럴 때 뒤에 오는 단어('탔다' or '먹었다')가 '배'의 의미를 결정합니다.
👉 그래서 뒤 문맥도 파악할 수 있도록 만든 구조가 바로 Bidirectional RNN입니다.
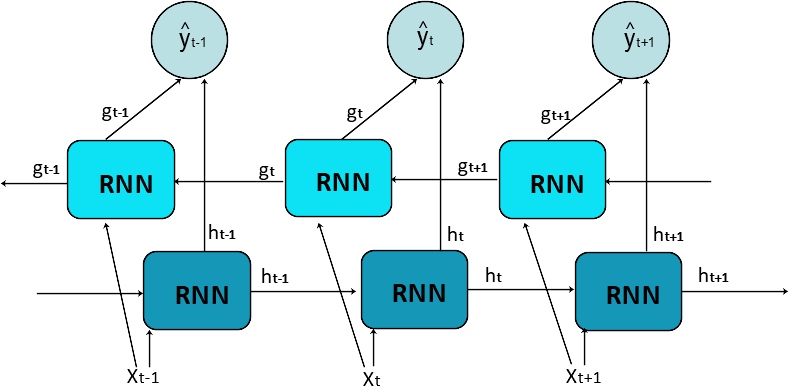
🔹 아래쪽 (진한 파랑) :일반적인 정방향 RNN
왼쪽에서 오른쪽으로 순서대로 진행 (과거 → 현재 → 미래)
🔹 위쪽 (연한 파랑) 역방향 RNN
오른쪽에서 왼쪽으로 진행 (미래 → 현재 → 과거)
🔹 위의 동그라미 두 방향에서 계산된 정보를 합쳐서 예측 결과를 만듭니다. 예: 텍스트 분류 결과, 번역 결과, 품사 태깅 등
✅ 언제 Bidirectional RNN을 쓰나?
문맥 전체를 알고 있는 경우, 즉 입력 전체가 고정되어 있을 때 사용하면 좋습니다. 예: 감정 분석, 품사 태깅, 번역 등
특히 입력과 출력 길이가 같은 구조(Many-to-Many)에서 매우 효과적이에요.
⚠️ 사용 시 주의: Auto Regressive 모델에는 ❌
❓ Auto Regressive란? 이전 출력값을 다음 입력으로 사용하는 구조 (예: GPT, 텍스트 생성 모델)
❌ 왜 Bidirectional 안 되는가?
미래 정보를 보면서 현재를 예측하면, 텍스트 "생성"이 아니라 "복귀"가 됨
GPT처럼 단어를 하나씩 이어서 생성하는 경우는 단방향만 가능
- 🏗️ Stacking (Multi-Layer) RNN 구조
: "하나의 RNN 층으로 부족할 때, 여러 개의 RNN 층을 층층이 쌓아서 더 복잡한 표현을 학습하는 구조"
✅ 1. 왜 여러 층을 쌓을까?
단일 RNN Layer는 입력 시퀀스를 시간적으로 요약하는 데는 유용하지만, 복잡한 문맥이나 고차원 패턴을 파악하는 데는 한계가 있어요.
그래서 여러 층을 쌓아서 표현 능력(representational capacity)을 강화합니다!
🧱 2. 구조는 어떻게 생겼을까?
첫 번째 RNN Layer는 입력 시퀀스를 받아서 각 time step마다 hidden state들을 출력합니다.
👉 예: [30, 100, 4] → [30, 100, 256] (batch, sequence, hidden size)
그 다음 Layer는 이 hidden state 시퀀스를 새로운 입력으로 받아 다시 RNN 연산을 수행합니다.
즉, 앞 층의 모든 time step별 출력값을 다음 층이 입력으로 받는다.
🧠 PyTorch RNN Layer 구조
PyTorch의 nn.RNN은 순차 데이터(예: 텍스트, 시계열 등)를 처리할 수 있는 기본 RNN 레이어
| 파라미터 이름 | 설명 |
| --------------- | --------------------------------------------------------------------------------------------------------------------- |
| input_size | 각 time step에서 입력되는 feature 수 |
| hidden_size | RNN 내부에서 계산되는 hidden state의 차원 |
| num_layers | RNN 레이어를 몇 층 쌓을지 |
| nonlinearity | 활성 함수 (기본: 'tanh', 선택: 'relu') |
| batch_first | 입력 텐서의 shape 순서 지정
(기본: (seq_len, batch_size, input_size) → True로 설정하면 (batch_size, seq_len, input_size)가 됨) |
| dropout | 레이어 간 dropout 비율 |
| bidirectional | 양방향 RNN 여부 |
📥 Input Tensor Shape
- 입력값 두개 : Input_Data, Hidden_state
✅ 기본 구조
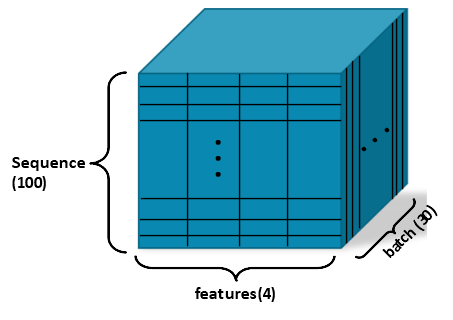
input_data의 shape:
✨ 예시
- feature: 4 (시가, 종가, 최고가, 최저가)
- sequence length: 100일치
- batch size: 30개
따라서 입력 텐서의 shape은:
단,
batch_first=True로 설정하면:
💾 3. Hidden State 입력
초기 hidden state는 생략하면 자동으로 0으로 초기화됩니다.
✅ shape
- ( D = 2 ) (양방향), ( D = 1 ) (단방향)
num_layers: RNN이 몇 층인지
📤Output: RNN의 반환값
output, hidden_state = rnn(input, h_0)✅ output의 shape
-
전체 time step의 출력값을 담고 있음
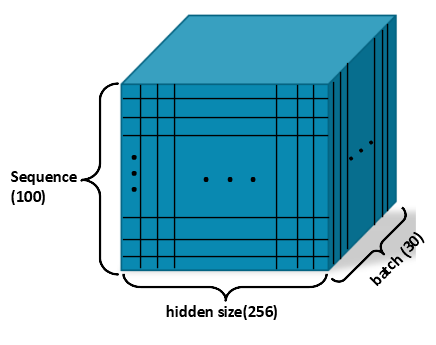
-
Shape:
- : 양방향 RNN (
bidirectional=True) - : 단방향 RNN (기본값)
📌 Many-to-Many 구조에서 사용됨 (모든 시점의 출력이 필요할 때)
✅ hidden_state의 shape
- 마지막 time step에서 각 레이어의 출력값이 모여 있는 텐서
- Shape:
- : 양방향
- : 단방향
num_layers: RNN이 몇 층으로 구성되어 있는지
📌 Many-to-One 구조에서 사용됨 (마지막 출력만 사용할 때)
