1. 함수식과 그래프 그리기
선형 피팅(linear fitting)
- 수많은 데이터가 일정한 규칙성이 있는지 알기 위해 이 데이터를 잘 분석해 가장 잘 맞는 규칙인 공식을 찾는 것 또는 가장 잘 표현하는 직선(best fitting)을 찾는 것
- 이 점들을 지나는 가장 적합한 선형회귀(linear regression)
- 선형 상관 관계를 나타내는 y = f(x) 찾는 것
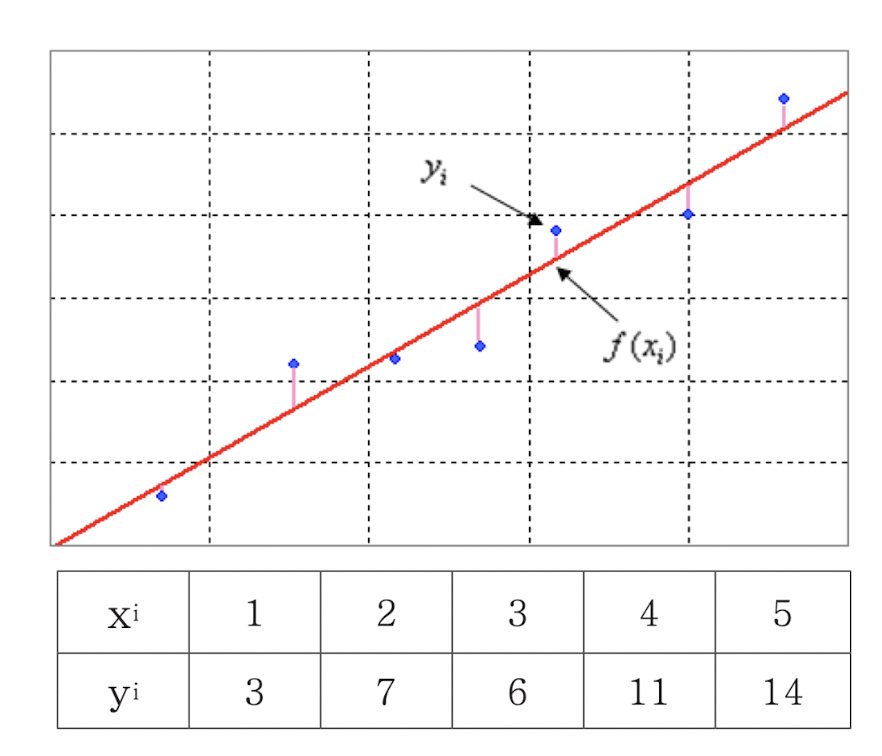
polyfit(x,y,n) : 기울기(m)와 y절편값(b)을 구할 수 있음.
- 첫 번째 인자 : x 값에 대한 리스트
- 두 번째 인자 : y 값에 대한 리스트
- 세 번째 인자 : x의 차수
ex) 1인 경우, x의 1차 차수
linspace(start, end, num=개수) : start~end 사이의 값을 개수만큼 생성해 배열로 반환
import numpy as np
import matplotlib.pyplot as plt
x = [1,2,3,4,5]
y = [3,7,6,11,14]
m,b = np.polyfit(x,y,1)
def f(x):
return x*m + b
plt.plot(x,y,'o')
L = np.linspace(0, 6)
plt.plot(L, f(L))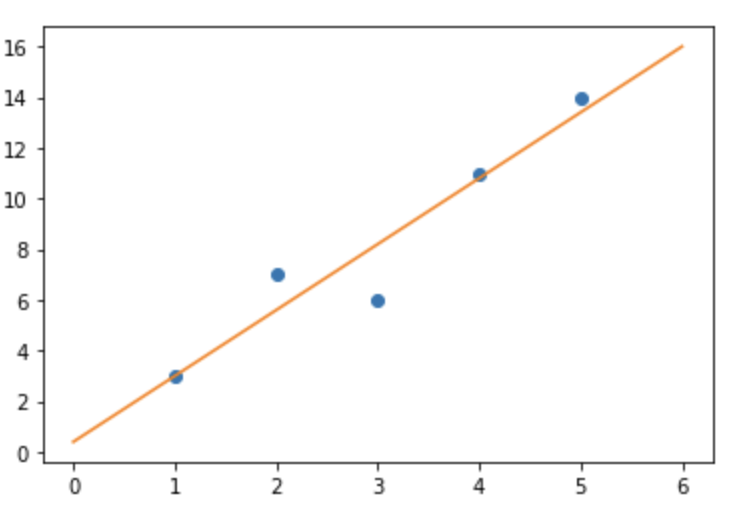
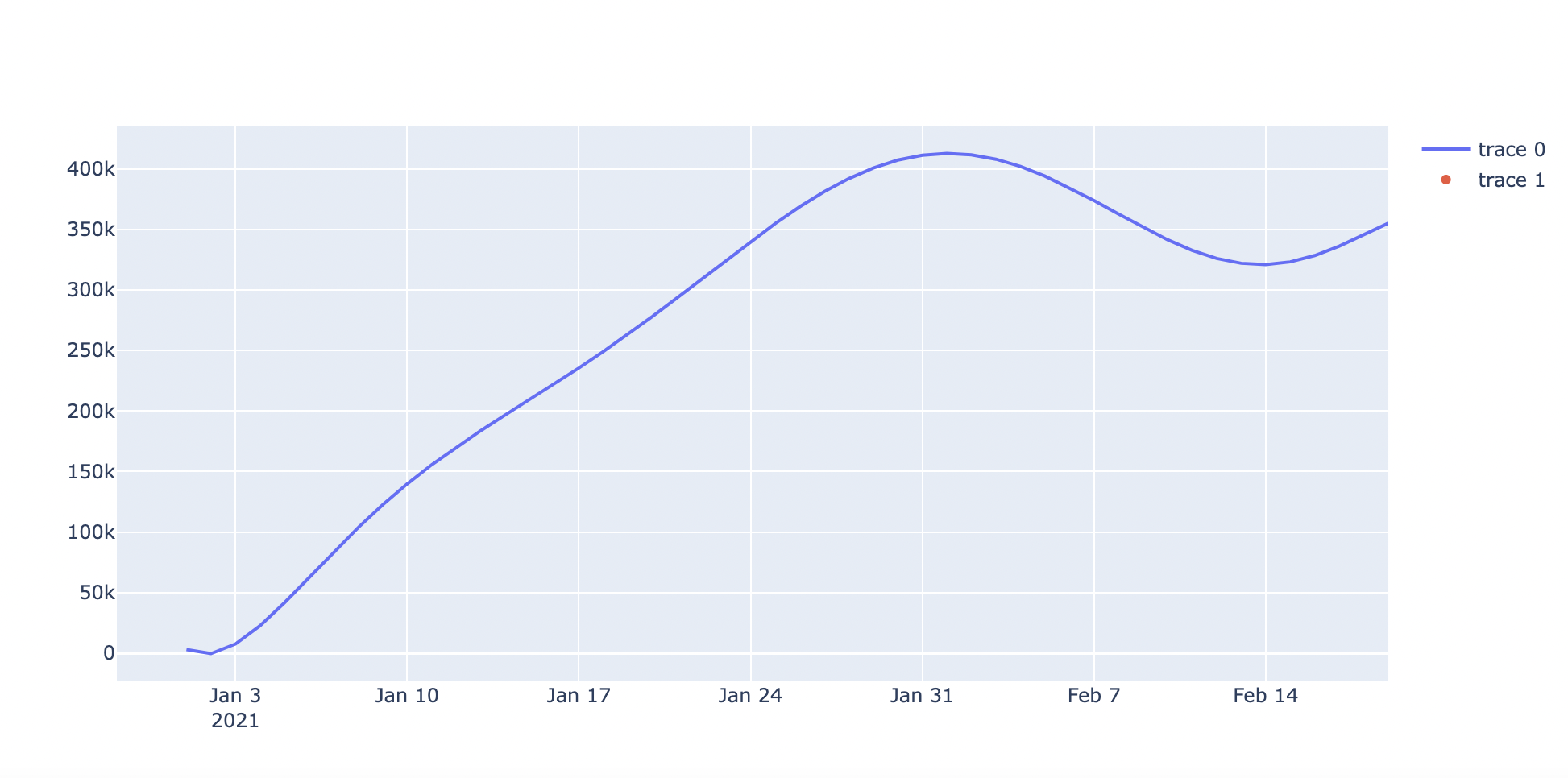
2. 한국 코로나 증가 추이
import pandas as pd
import plotly.graph_objects as go
import numpy as np
covid_df = pd.read_csv('https://covid.ourworldindata.org/data/jhu/full_data.csv')
covid_df.head(3)
df = covid_df.query('location=="South Korea"').query('date>"2020.01.20"')
fig = go.Figure(data=[go.Scatter(x=df['date'], y=df['total_cases'])])
fig.add_trace(go.Scatter(x=df['date'], y=df['biweekly_cases']))
fig.add_trace(go.Scatter(x=df['date'], y=df['new_cases']))
a3,a2,a1,a,b,c,d,e,g = np.polyfit(df['total_cases'],df['new_cases'],8)
def f(x1):
return a3*x1**8 + a2*x1**7 + a1*x1**6 + a*x1**5 + b*x1**4 + c*x1**3 + d*x1**2 + e*x1**1 + g
x1 = np.linspace(np.min(df['total_cases']), np.max(df['total_cases']))
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['date'], y=f(x1), mode='lines'))
fig.add_trace(go.Scatter(x=df['date'], y=['new_cases'], mode='markers'))
- 판다스 데이터 프레임 인덱싱
- loc[행, 인덱싱값] : 행을 인덱싱값으로 선택해 해당 열을 골라냄
- query() : 조건식(문자열)에 맞는 행을 Series 형태로 출력
- 코로나 예측 ➡️ 단순 선형회귀
- 선형 회귀 : 각 변수들 관계가 선형관계로서 독립변수에 따라 종속변수 값이 일정한 패턴으로 변해가는 관계를 나타내는 회귀선
np.polyfit(x,y,n)- polyfit() : 입력(독립변수)과 출력(종속변수)로부터 다항식 계수를 찾아 예측 추세선을 구함

hello world!