1. 데이터프레임
- 판다스의 가장 기본적인 구조
import pandas as pd
index = pd.date_range('1/1/2000', periods=8)
print(index)
#DatetimeIndex(['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04', '2000-01-05', '2000-01-06', '2000-01-07', '2000-01-08'], dtype='datetime64[ns]', freq='D')
- 날짜 형태로 된 8개 인덱스 생성
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(8,3), index=index, columns=list('ABC'))
df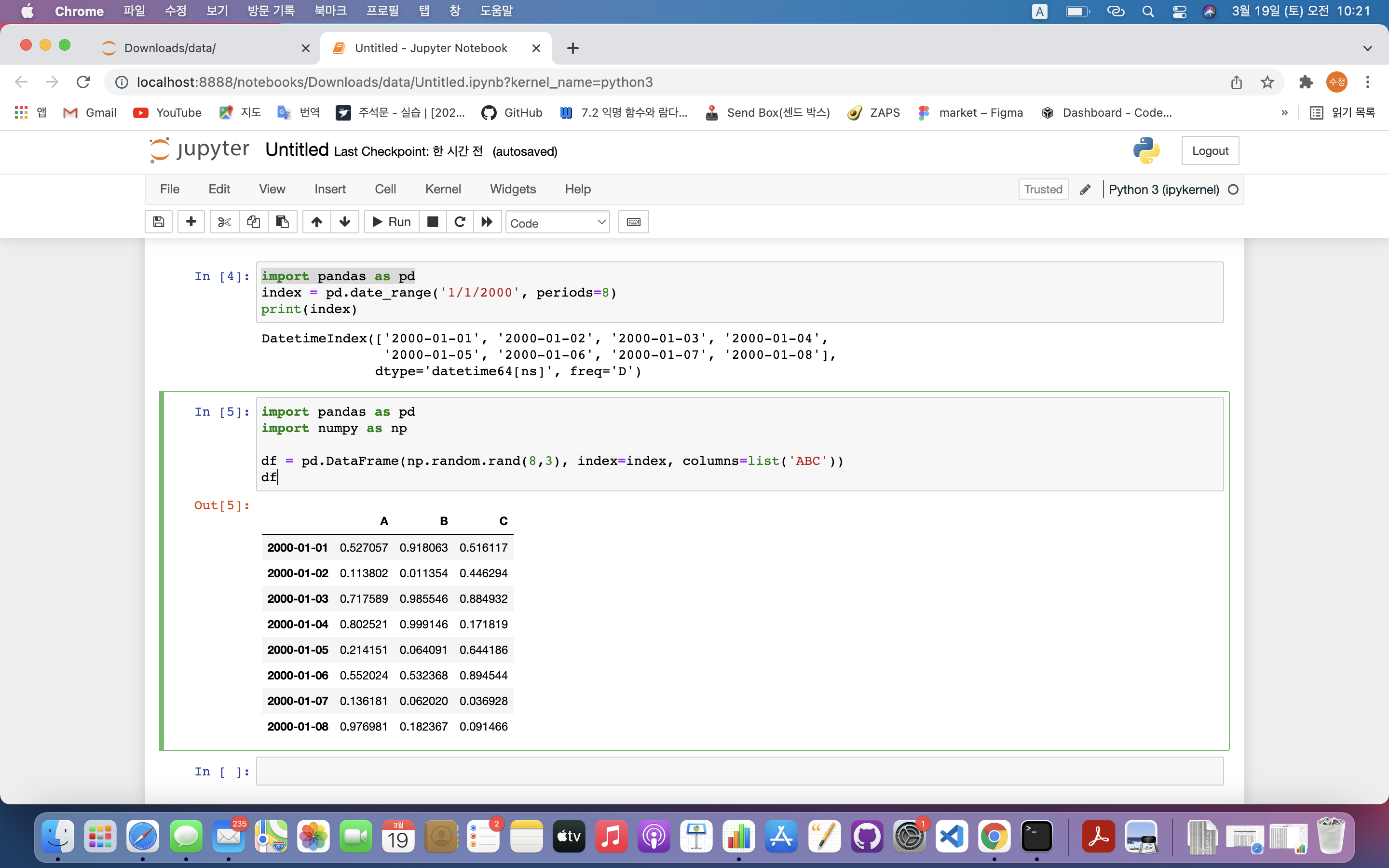
- 8행 3열로 구성된 행렬 생성
- index는 선택하지 않아도 자동으로 선택됨
- 특정 행/열 선택 시 시리즈(Series) 데이터구조 형태로 표현됨
print(df['B'])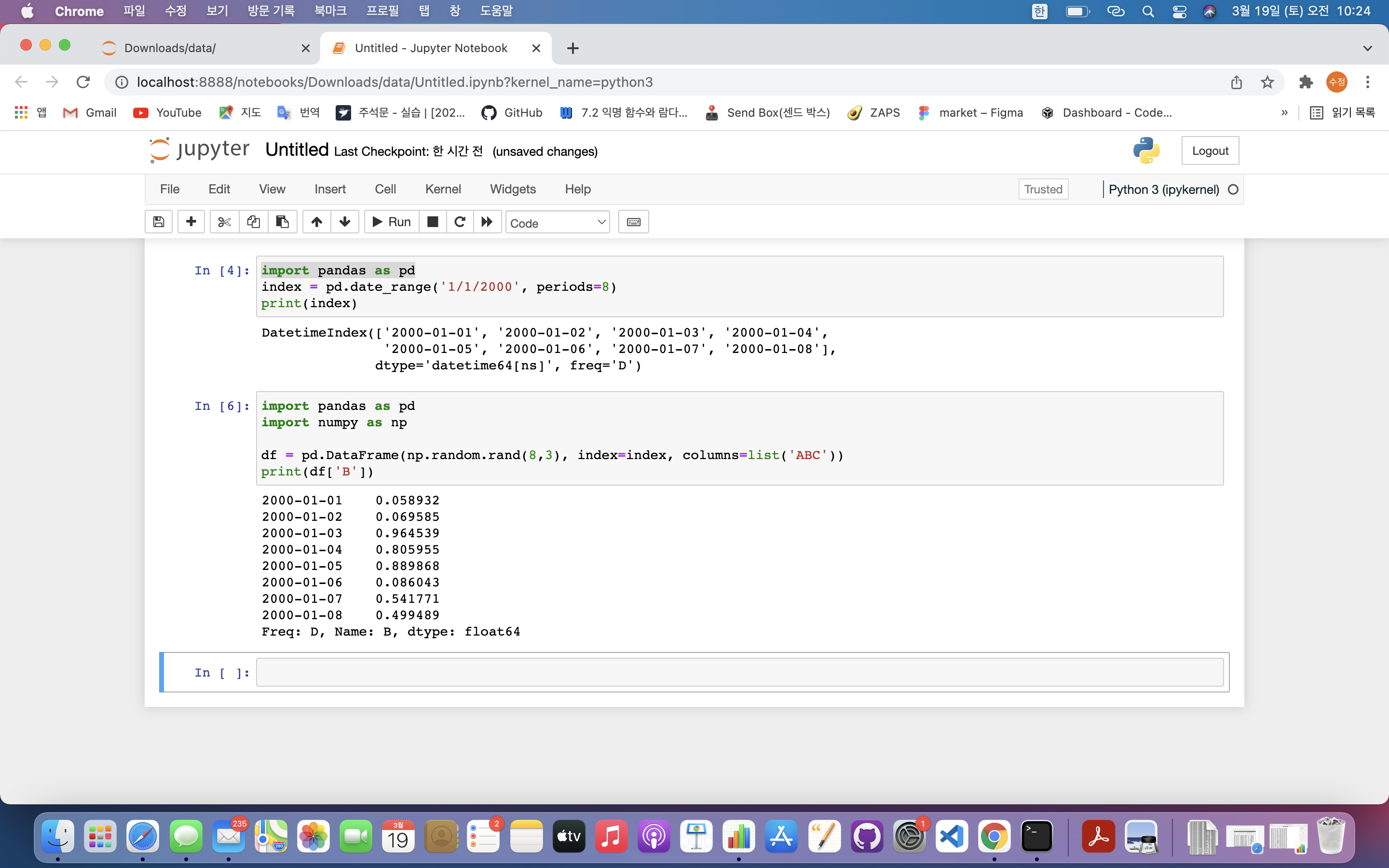
- Series 형태로 표현
print(df['B'] > 0.4)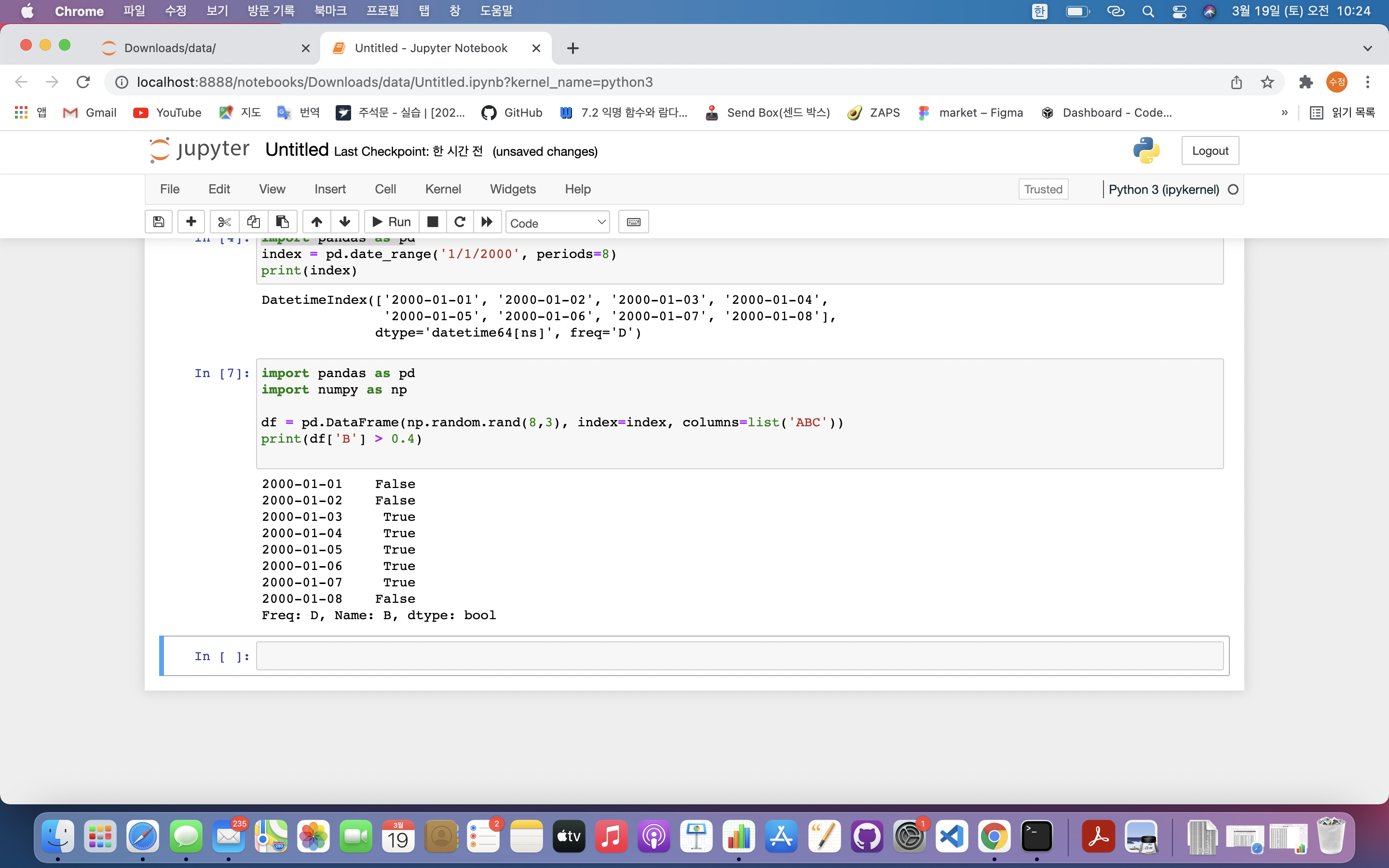
- 마스크 적용 가능
import pandas as pd
import numpy as np
index = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.rand(8,3), index=index, columns=list('ABC'))
df2 = df[df['B']>0.4]
df2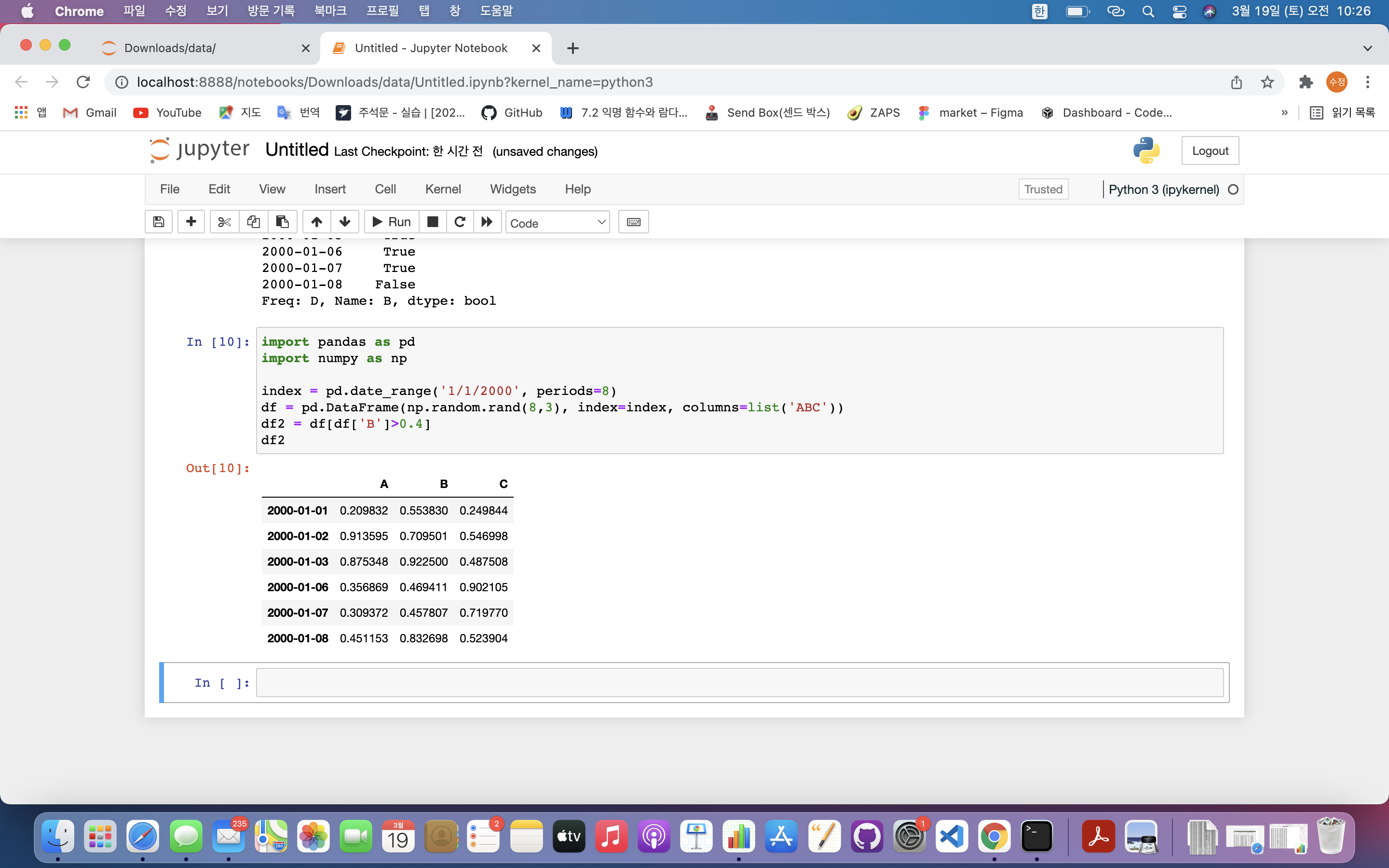
df2.T #데이터 프레임 뒤집기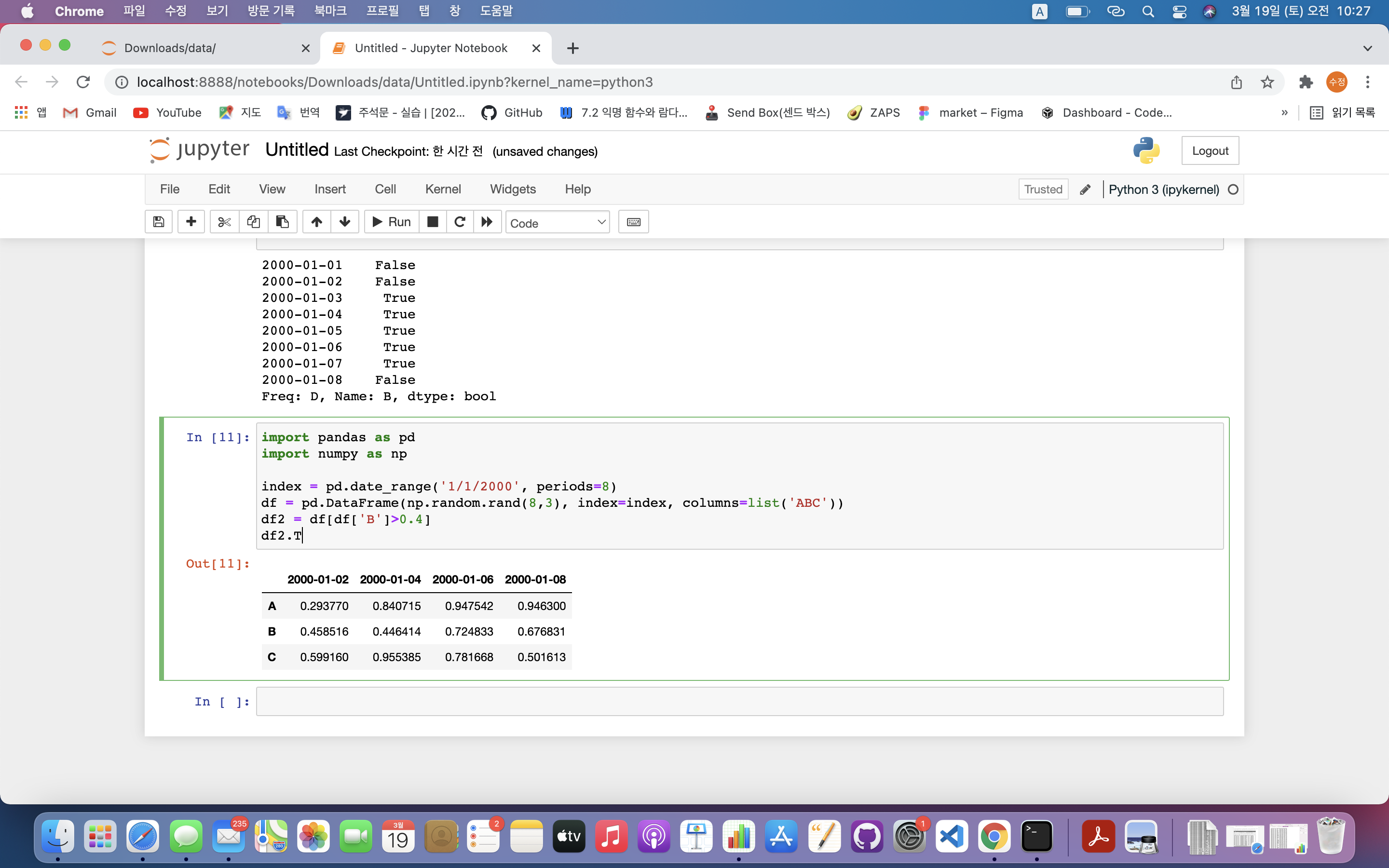
- 데이터 프레임 행과 열 바꾸기 : T(transpose)
- 이차원 배열
🌼 행 우선 계산 vs 열 우선 계산
- 행 우선 계산을 기본으로 함
- 열 방향 축 계산 : axis = 1
1) 행 방향 축 계산
import pandas as pd
import numpy as np
index = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.rand(8,3), index=index, columns=list('ABC'))
df['D'] = df['A'] / df['B']
df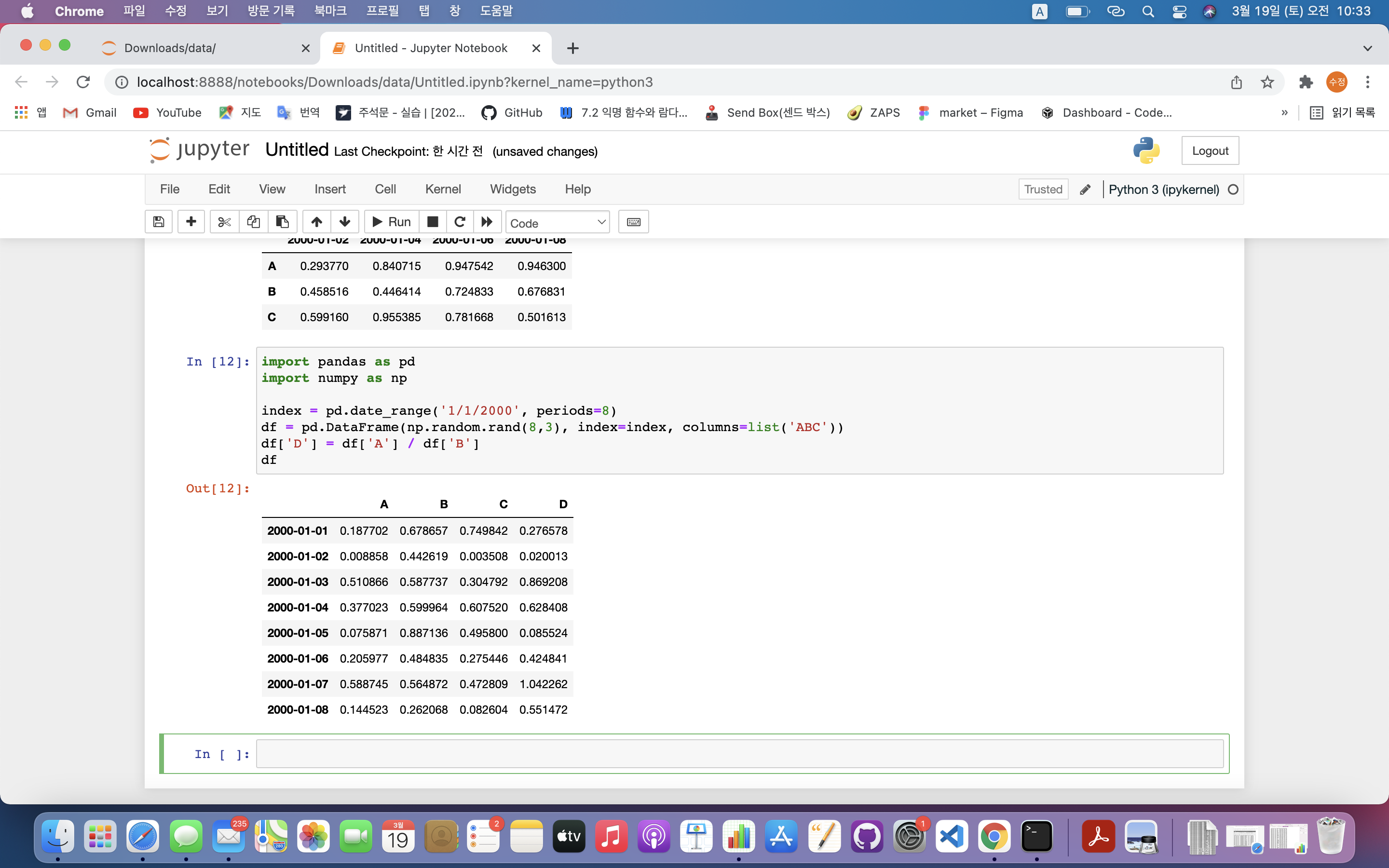
2) 열 방향 축 계산
import pandas as pd
import numpy as np
index = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.rand(8,3), index=index, columns=list('ABC'))
df['D'] = df['A'] / df['B']
df['E'] = np.sum(df, axis=1)
df.head()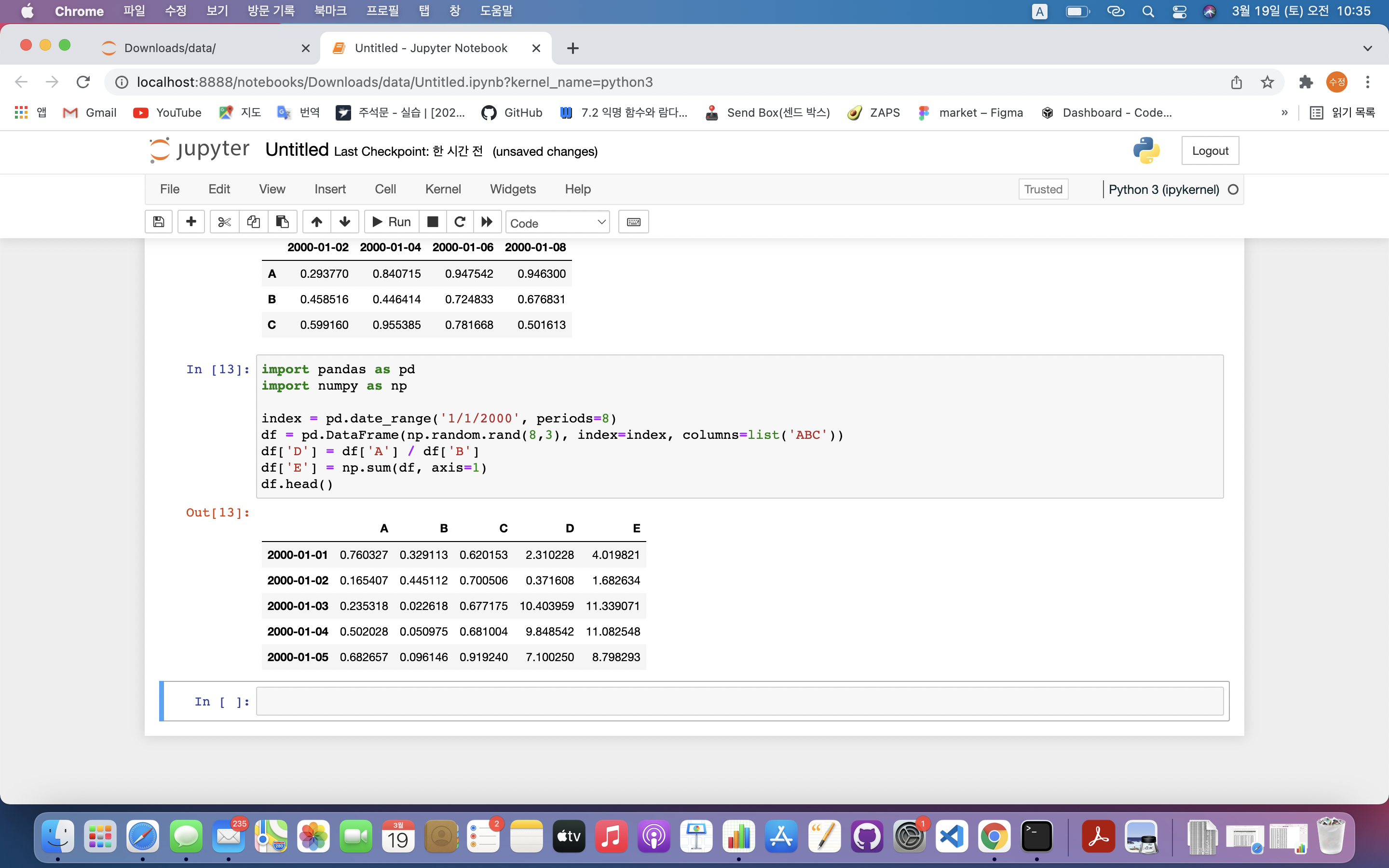
df['E'] = np.sum(df, axis=1): 행 기준으로 합산 후 E라는 열 생성df.head(): 첫 5줄만 출력
2-1) 전체 데이터에 대한 열 우선 계산
import pandas as pd
import numpy as np
index = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.rand(8,3), index=index, columns=list('ABC'))
df['D'] = df['A'] / df['B']
df['E'] = np.sum(df, axis=1)
df = df.sub(df['A'], axis=0)
df.head()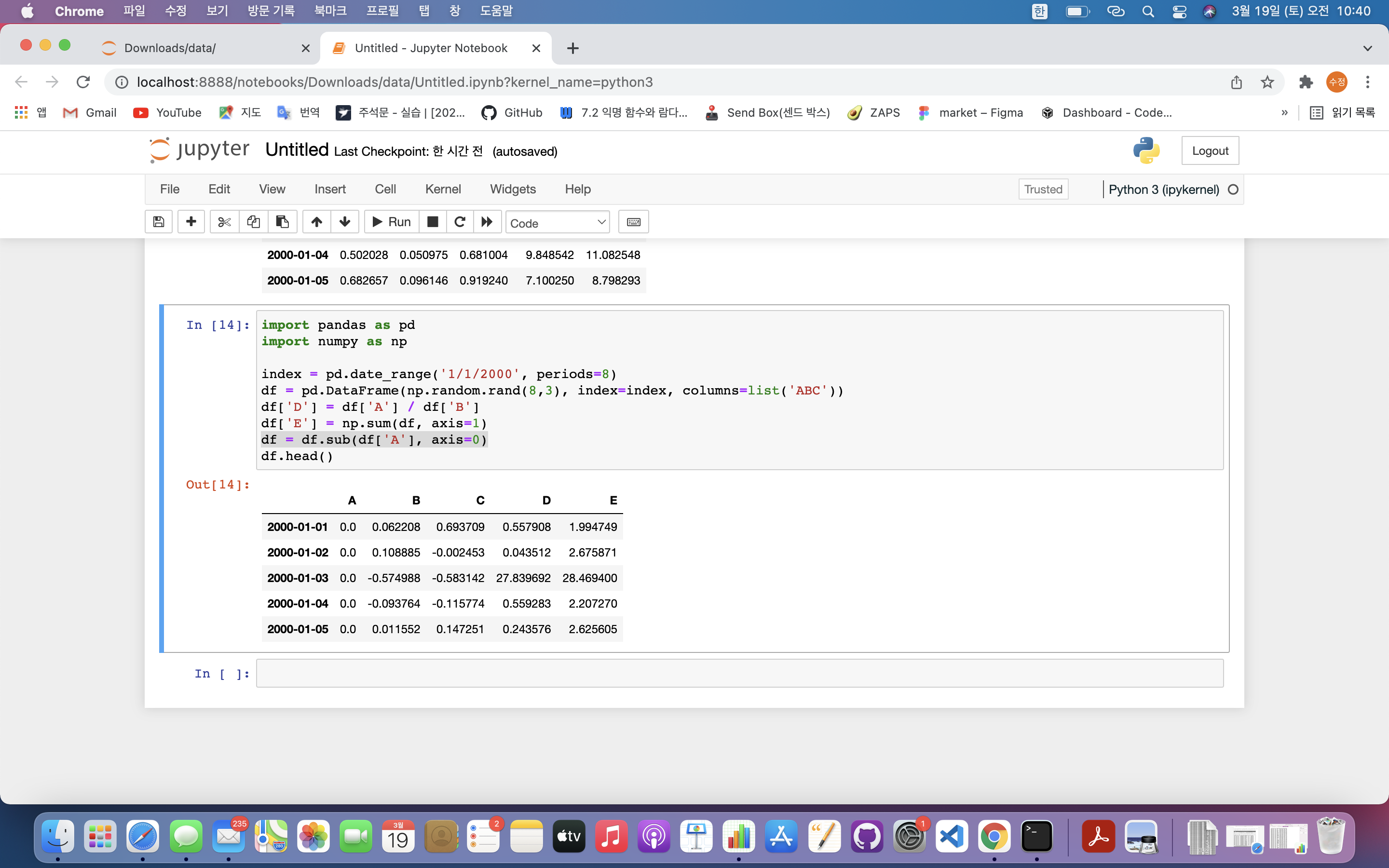
df = df.sub(df['A'], axis=0): A열 기준으로 전체 데이터 뺄셈- B열부터 기존 값에서 A열 값을 뺀 값이 저장된 것 확인 가능
import pandas as pd
import numpy as np
index = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.rand(8,3), index=index, columns=list('ABC'))
df['D'] = df['A'] / df['B']
df['E'] = np.sum(df, axis=1)
df = df.sub(df['A'], axis=0)
df = df.div(df['C'], axis=0)
df.to_csv('test.csv')
df.head()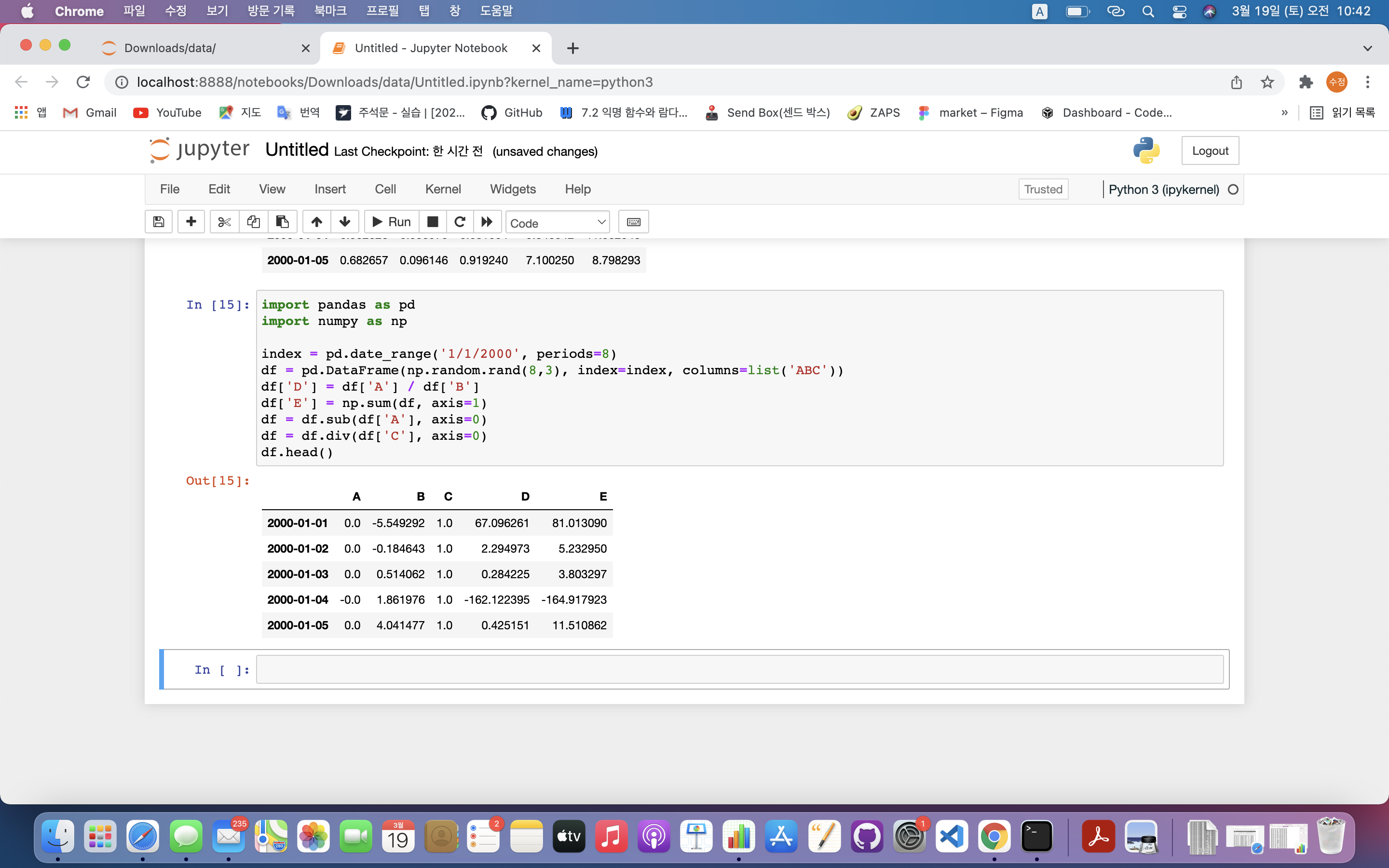
df = df.div(df['C'], axis=0): 전체 데이터를 C열 기준으로 나눔.df.to_csv('test.csv'): 데이터프레임에 대한 csv 파일이 저장됨
2. 인구 구조 분석하기 with Pandas
🌼알고리즘
1. 데이터 읽어오기
1.1) 전체 데이터를 총 인구수로 나누어 비율 구함
1.2) 총 인구수와 연령구간 인구 수 삭제
2. 알고 싶은 지역 입력 받기
3. 해당 지역 인구 구조 저장
4. 해당 지역과 가장 비슷한 인구구조를 가진 지역 찾기
4.1) 전국 모든 지역 중 한 곳 선택
4.2) 입력 받은 지역의 0세 인구 비율 - 선택된 지역의 0세 인구비율
4.3) 100세 이상 인구비율까지 계산 후 계산된 값 제곱 더하기
4.4) 전국 모든 지역에 대해 반복 후 가장 차이가 적은 지역 선택
5. 두 지역 시각화
1) 데이터 읽어오기
import pandas as pd
import numpy as np
df = pd.read_csv('people.csv', index_col=0)
df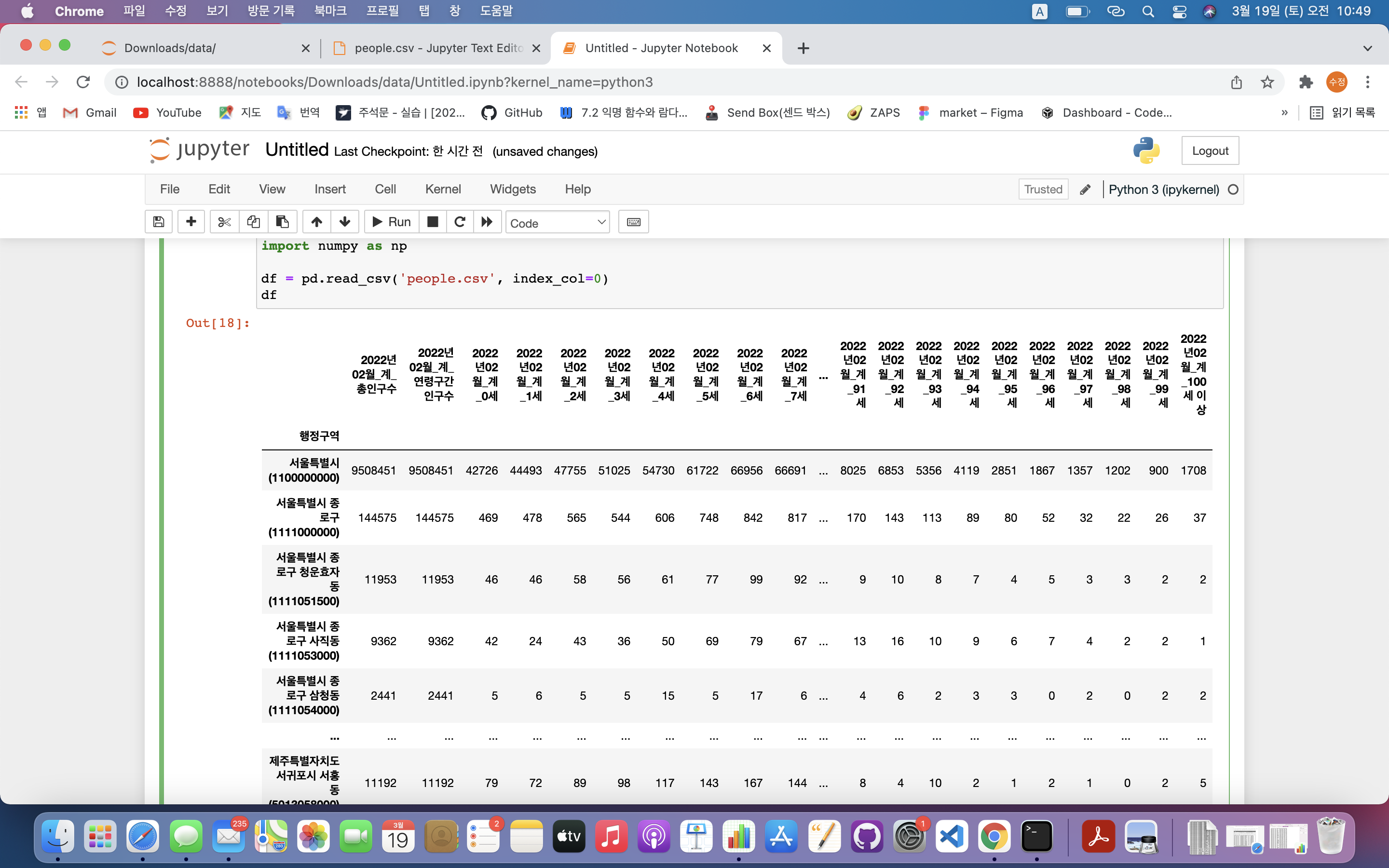
1.1) 총 인구수로 나누기 및 열 삭제
import pandas as pd
import numpy as np
df = pd.read_csv('people.csv', index_col=0)
df = df.div(df['총인구수'], axis=0) #전체 데이터를 총인구수로 나누어 비율을 구함
del df['총인구수'], df['연령구간인구수'] # 필요 없는 두 열 삭제
df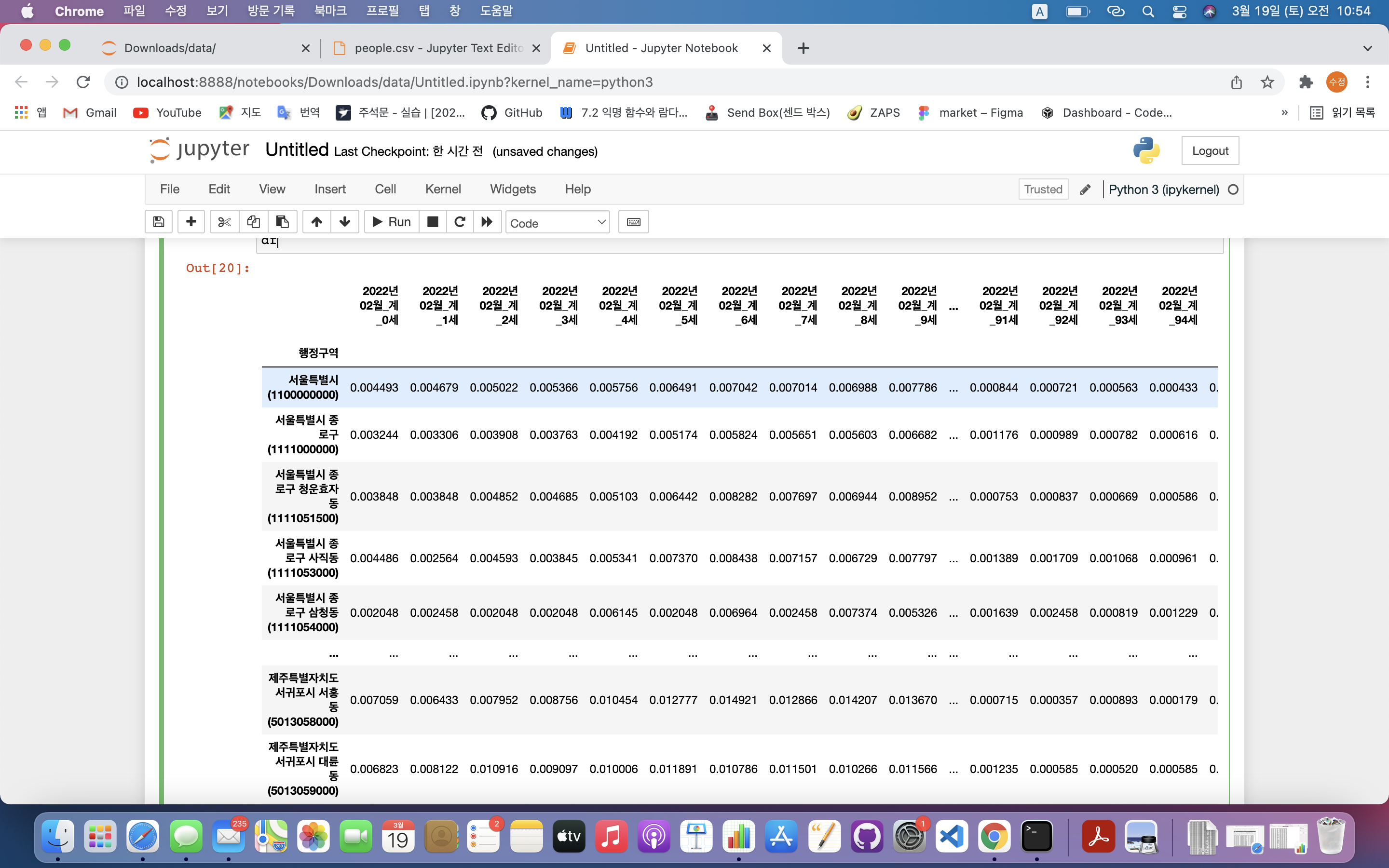
2. 원하는 지역 입력받고 해당 지역 인구구조 저장하기
import pandas as pd
import numpy as np
df = pd.read_csv('people.csv', index_col=0)
df = df.div(df['총인구수'], axis=0)
del df['총인구수'], df['연령구간인구수']
name = input('원하는 지역?')
a = df.index.str.contains(name) #해당 문자가 있는 행 찾음
df2 = df[a]
df2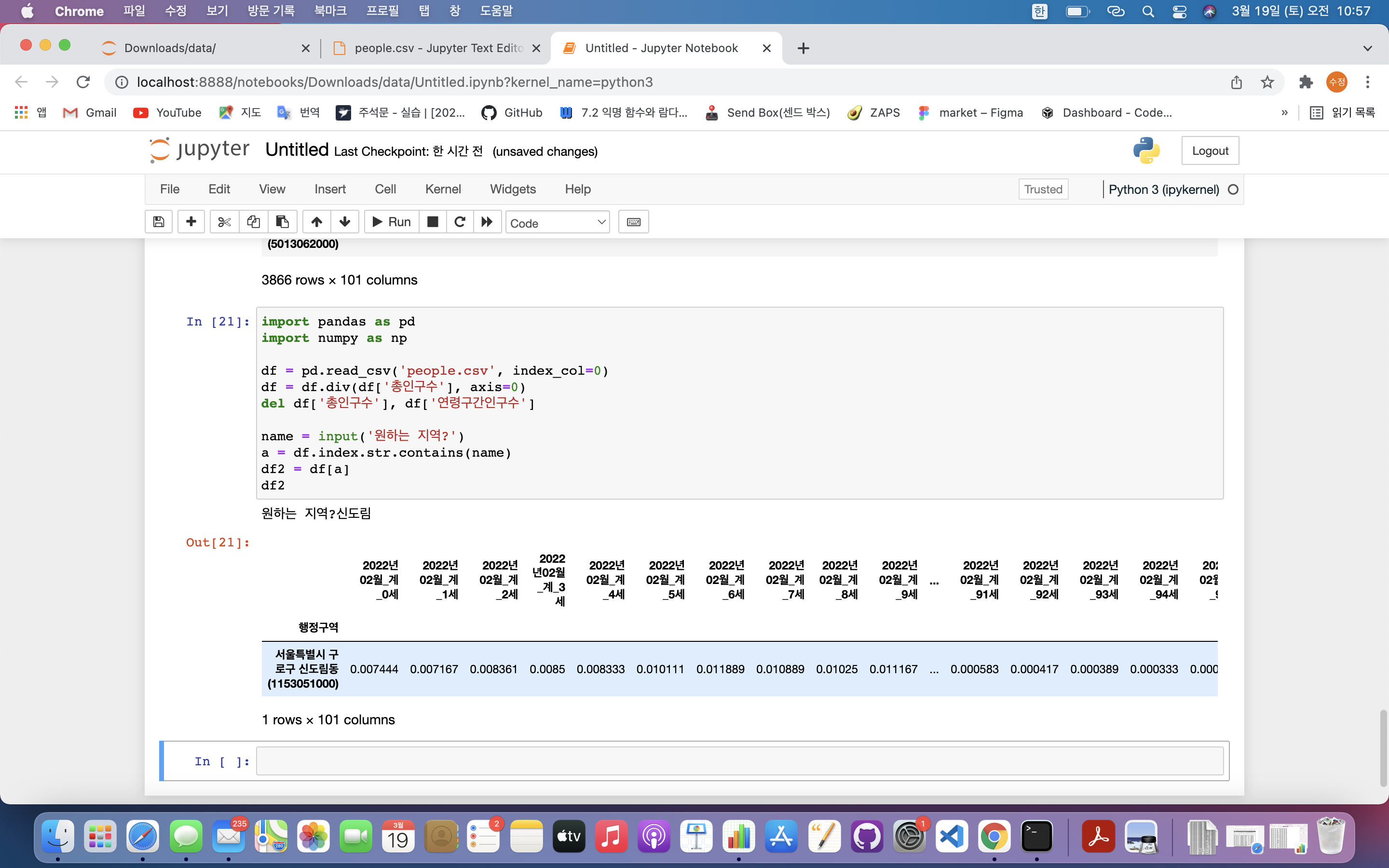
df.index.str.contains(name): 데이터 프레임의 인덱스 문자열에 원하는 문자가 있는 행 찾아냄
import pandas as pd
import numpy as np
df = pd.read_csv('people.csv', index_col=0)
df = df.div(df['총인구수'], axis=0)
del df['총인구수'], df['연령구간인구수']
name = input('원하는 지역?')
a = df.index.str.contains(name)
df2 = df[a]
df2
import matplotlib.pyplot as plt
plt.rc('font', family='AppleGothic')
df2.T.plot()
plt.show()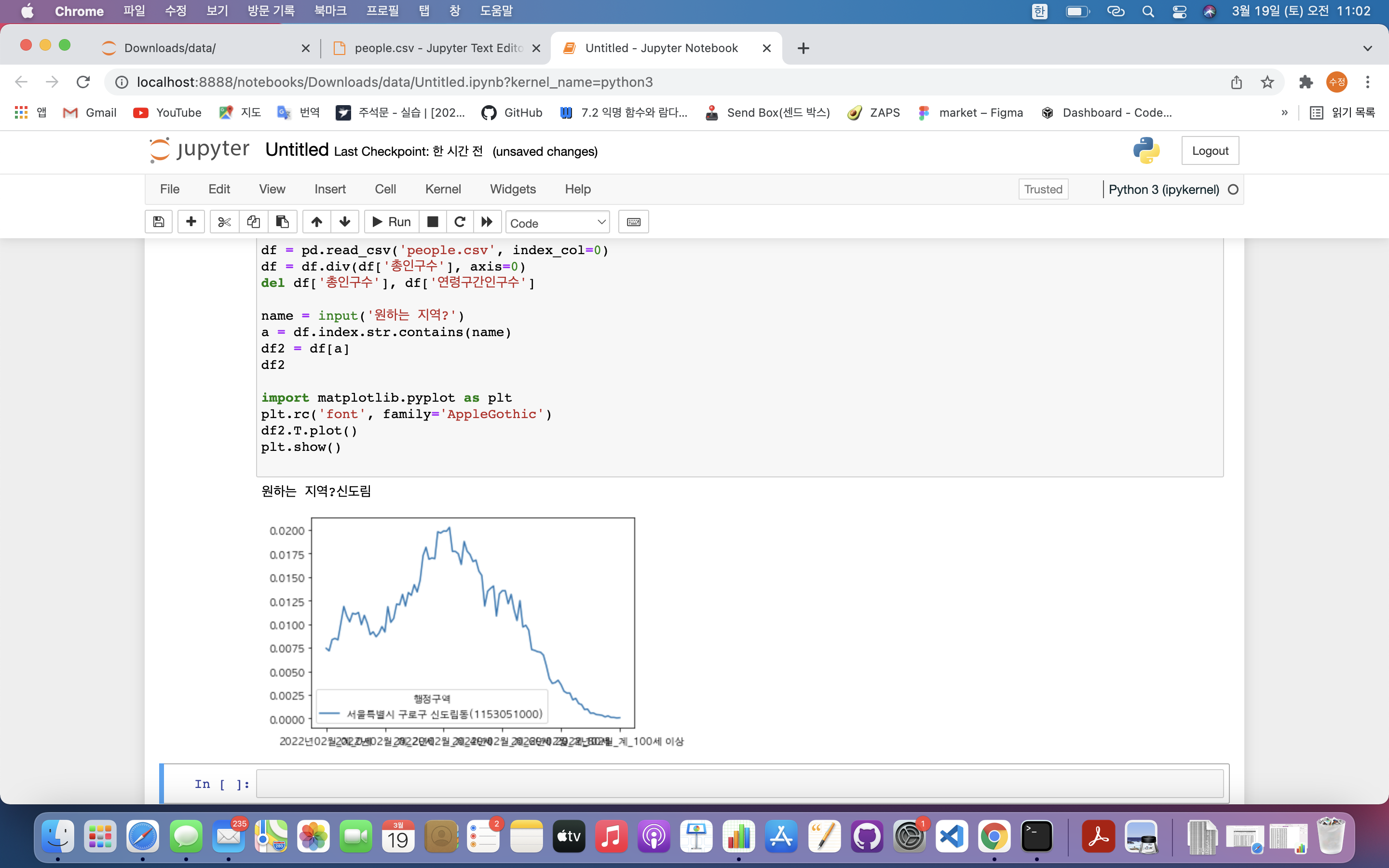
- 해당 지역 시각화
3. 입력 받은 지역과 인구구조가 비슷한 지역을 찾고 시각화하기
x = df.sub(df2.iloc[0], axis=1) # 전체지역에서 해당지역의 열과 뺄셈
y = np.power(x, 2) # 해당값 제곱
z = y.sum(axis=1) #제곱한 값들을 합산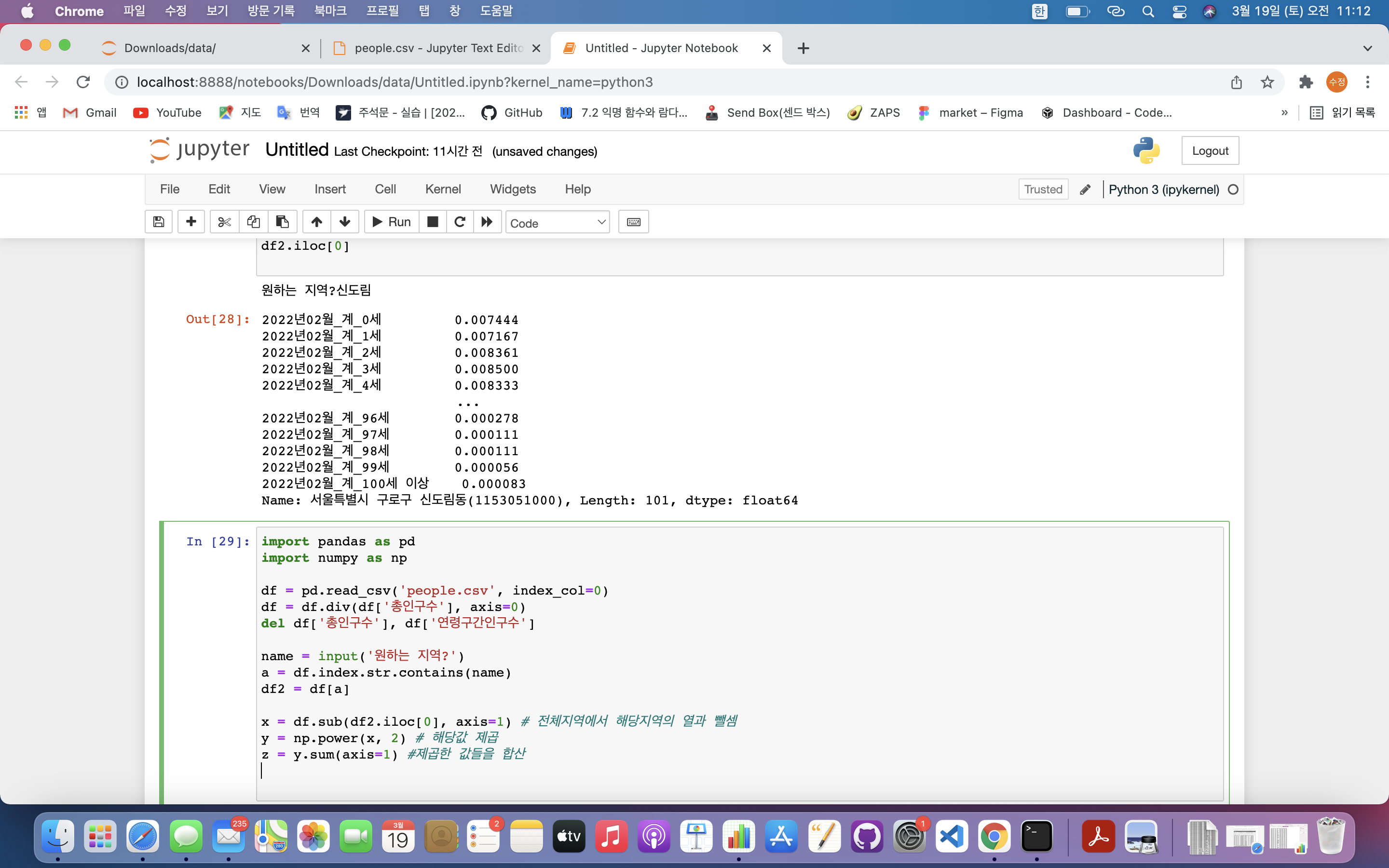
- iloc : 열 단위 데이터 읽기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('people.csv', index_col=0)
df = df.div(df['총인구수'], axis=0)
del df['총인구수'], df['연령구간인구수']
plt.rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False
name = input('원하는 지역?')
a = df.index.str.contains(name)
df2 = df[a]
x = df.sub(df2.iloc[0], axis=1) # 전체지역에서 해당지역의 열과 뺄셈
y = np.power(x, 2) # 해당값 제곱
z = y.sum(axis=1) #제곱한 값들을 합산
i = z.sort_values().index[:4] # 값들의 차이가 가장 적은 지역 5개만 추출
df.loc[i].T.plot()
# df.loc[np.power(df.sub(df2.iloc[0], axis=1), 2).sum(axis=1).sort_values().index[:5]].T.plot()
plt.show()
hello world!