Age and Gender Classification Model을 돌려보았다.
사전 학습된 모델을 돌려봤는데 나이를 잘 맞추지 못했다

그래서 새롭게 학습시키는 중이다.
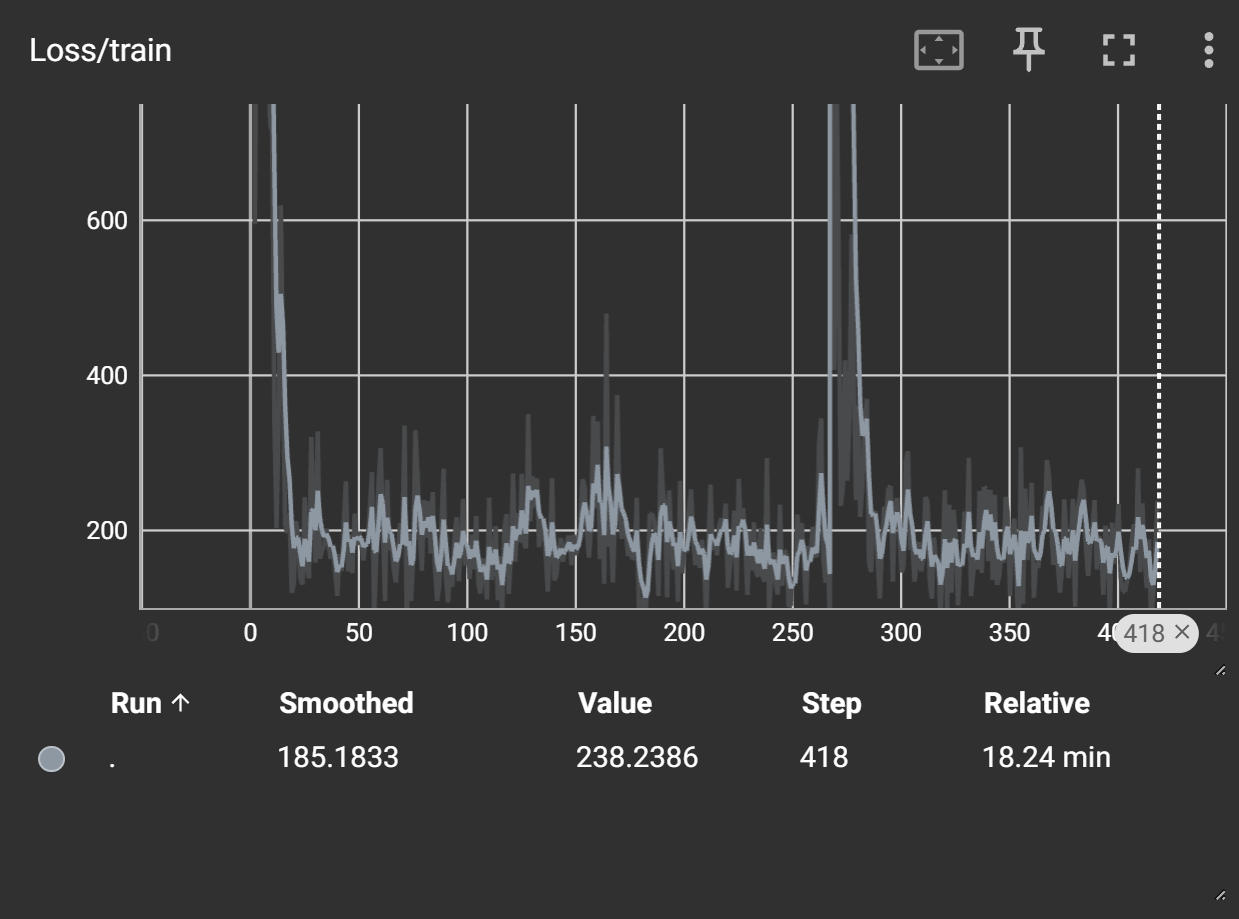
학습률이 너무 높아서 다시 훈련을 시켜볼 예정이다.
import argparse
import logging
import os
import cv2
import torch
import yt_dlp
import pandas as pd
import matplotlib.pyplot as plt
from mivolo.data.data_reader import InputType, get_all_files, get_input_type
from mivolo.predictor import Predictor
from timm.utils import setup_default_logging
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from PIL import Image
import torch.nn as nn
import torch.optim as optim
from model import MyModel
from torch.utils.tensorboard import SummaryWriter
import time
_logger = logging.getLogger("inference")
class IMDBDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None):
self.labels = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, self.labels.iloc[idx, 0])
image = Image.open(img_name).convert('RGB')
age = self.labels.iloc[idx, 1]
gender = self.labels.iloc[idx, 2]
if self.transform:
image = self.transform(image)
return image, age, gender
def get_direct_video_url(video_url):
ydl_opts = {
"format": "bestvideo",
"quiet": True,
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info_dict = ydl.extract_info(video_url, download=False)
if "url" in info_dict:
direct_url = info_dict["url"]
resolution = (info_dict["width"], info_dict["height"])
fps = info_dict["fps"]
yid = info_dict["id"]
return direct_url, resolution, fps, yid
return None, None, None, None
def get_local_video_info(vid_uri):
cap = cv2.VideoCapture(vid_uri)
if not cap.isOpened():
raise ValueError(f"Failed to open video source {vid_uri}")
res = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fps = cap.get(cv2.CAP_PROP_FPS)
return res, fps
def get_parser():
parser = argparse.ArgumentParser(description="PyTorch MiVOLO Inference")
parser.add_argument("--input", type=str, default=None, required=True, help="image file or folder with images")
parser.add_argument("--output", type=str, default=None, required=True, help="folder for output results")
parser.add_argument("--detector-weights", type=str, default=None, required=True, help="Detector weights (YOLOv8).")
parser.add_argument("--checkpoint", default="", type=str, required=True, help="path to mivolo checkpoint")
parser.add_argument(
"--with-persons", action="store_true", default=False, help="If set model will run with persons, if available"
)
parser.add_argument(
"--disable-faces", action="store_true", default=False, help="If set model will use only persons if available"
)
parser.add_argument("--draw", action="store_true", default=False, help="If set, resulted images will be drawn")
parser.add_argument("--device", default="cuda", type=str, help="Device (accelerator) to use.")
parser.add_argument("--train", action="store_true", default=False, help="If set, the model will be trained")
return parser
def main():
parser = get_parser()
setup_default_logging()
args = parser.parse_args()
if torch.cuda.is_available():
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.benchmark = True
os.makedirs(args.output, exist_ok=True)
# Check if checkpoint is set to a dummy value indicating no checkpoint
if args.checkpoint.lower() in ["", "none", "null"]:
args.checkpoint = None
if args.train:
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
dataset = IMDBDataset(csv_file='C:/Users/user141/Downloads/imdb_crop/imdb_labels.csv', root_dir='C:/Users/user141/Downloads/imdb_crop/imdb_crop', transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 데이터셋 크기 확인
print(f'Dataset size: {len(dataset)}')
image, age, gender = dataset[0]
print(f'First image size: {image.size}, Age: {age}, Gender: {gender}')
model = MyModel()
if args.checkpoint:
model.load_state_dict(torch.load(args.checkpoint))
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 구조 확인
print(model)
num_epochs = 10 # 에폭 수를 원하는 대로 설정
epoch_losses = []
writer = SummaryWriter(log_dir=args.output) # TensorBoard 로그 기록을 위한 SummaryWriter 초기화
start_time = time.time()
for epoch in range(num_epochs):
epoch_loss = 0
for batch_idx, (images, ages, genders) in enumerate(dataloader):
outputs = model(images)
loss = criterion(outputs, ages.unsqueeze(1).float())
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
# TensorBoard에 손실 값 기록
writer.add_scalar('Loss/train', loss.item(), epoch * len(dataloader) + batch_idx)
avg_loss = epoch_loss / len(dataloader)
epoch_losses.append(avg_loss)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
end_time = time.time()
print(f'Training Time: {end_time - start_time:.2f} seconds')
writer.close() # TensorBoard 로그 기록 종료
# 모델 저장
torch.save(model.state_dict(), os.path.join(args.output, 'trained_model.pth'))
print('훈련 완료!')
else:
predictor = Predictor(args, verbose=True)
input_type = get_input_type(args.input)
if input_type == InputType.Video or InputType.VideoStream:
if not args.draw:
raise ValueError("Video processing is only supported with --draw flag. No other way to visualize results.")
if "youtube" in args.input:
args.input, res, fps, yid = get_direct_video_url(args.input)
if not args.input:
raise ValueError(f"Failed to get direct video url {args.input}")
outfilename = os.path.join(args.output, f"out_{yid}.avi")
else:
bname = os.path.splitext(os.path.basename(args.input))[0]
outfilename = os.path.join(args.output, f"out_{bname}.avi")
res, fps = get_local_video_info(args.input)
if args.draw:
fourcc = cv2.VideoWriter_fourcc(*"XVID")
out = cv2.VideoWriter(outfilename, fourcc, fps, res)
_logger.info(f"Saving result to {outfilename}..")
for (detected_objects_history, frame) in predictor.recognize_video(args.input):
if args.draw:
out.write(frame)
elif input_type == InputType.Image:
image_files = get_all_files(args.input) if os.path.isdir(args.input) else [args.input]
for img_p in image_files:
img = cv2.imread(img_p)
detected_objects, out_im = predictor.recognize(img)
if args.draw:
bname = os.path.splitext(os.path.basename(img_p))[0]
filename = os.path.join(args.output, f"out_{bname}.jpg")
cv2.imwrite(filename, out_im)
_logger.info(f"Saved result to {filename}")
if __name__ == "__main__":
main()

안녕하세요. 배운 것을 메모하는 velog입니다.