- RNN 계열의 모델은 sequence 길이가 길어지게 되면 vanishing gradient 가 발생
- 이로 인해 context vector 가 정보를 제대로 표현할 수 없게 된다
- 위 문제를 해결하기 위해 attention 이 등장
Attention
- sequence data 에서 어느 부분에 집중을 해야 하는가?
- attention 의 핵심은 Q, K, V (Query, Key, Value)
- Query : 질의문, 검색어
- 미분이 가능한 key-value function 이용
- Query 와 Key 의 내적을 통한 유사도에 따라 value 를 구한다
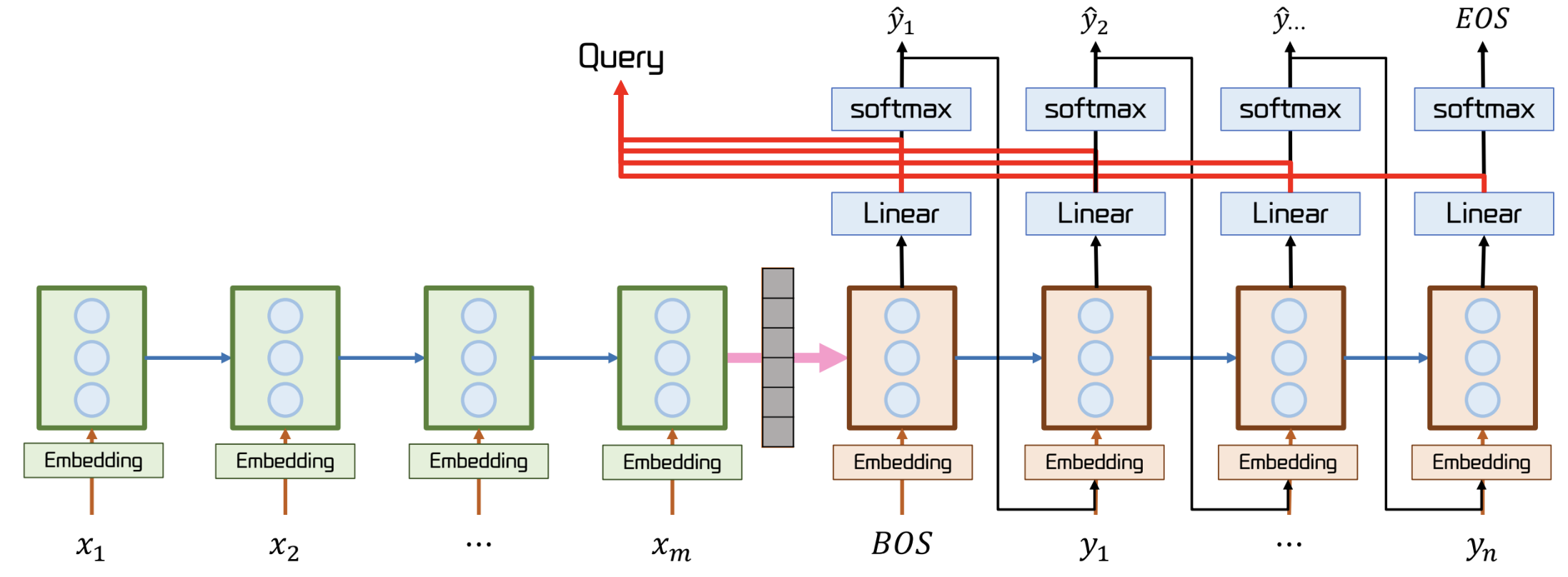
- Decoder 가 생성하는 단어가 Encoder 의 어떤 단어와 가장 유사한가?
- Decoder 와 Generator 사이에서 동작
Decoder 가 정보를 잘 얻어오기 위해 Query 를 만들어 내는 과정이 학습된다
Query
- 현재 timestep 의 Decoder 의 output. 즉, Generator 에 들어가기 전의 hidden state
- query 는 key 와의 내적을 통해 유사도를 얻을 수 있다
- linear layer 를 통해 key 와의 dimension 통일 및 중요한 정보 강조 가능
Key
- Encoder 의 각 timestep 의 hidden state
- linear layer 를 통해 query 와 차원을 맞춰줄 수 있다.
- value 는 key 의 context vector
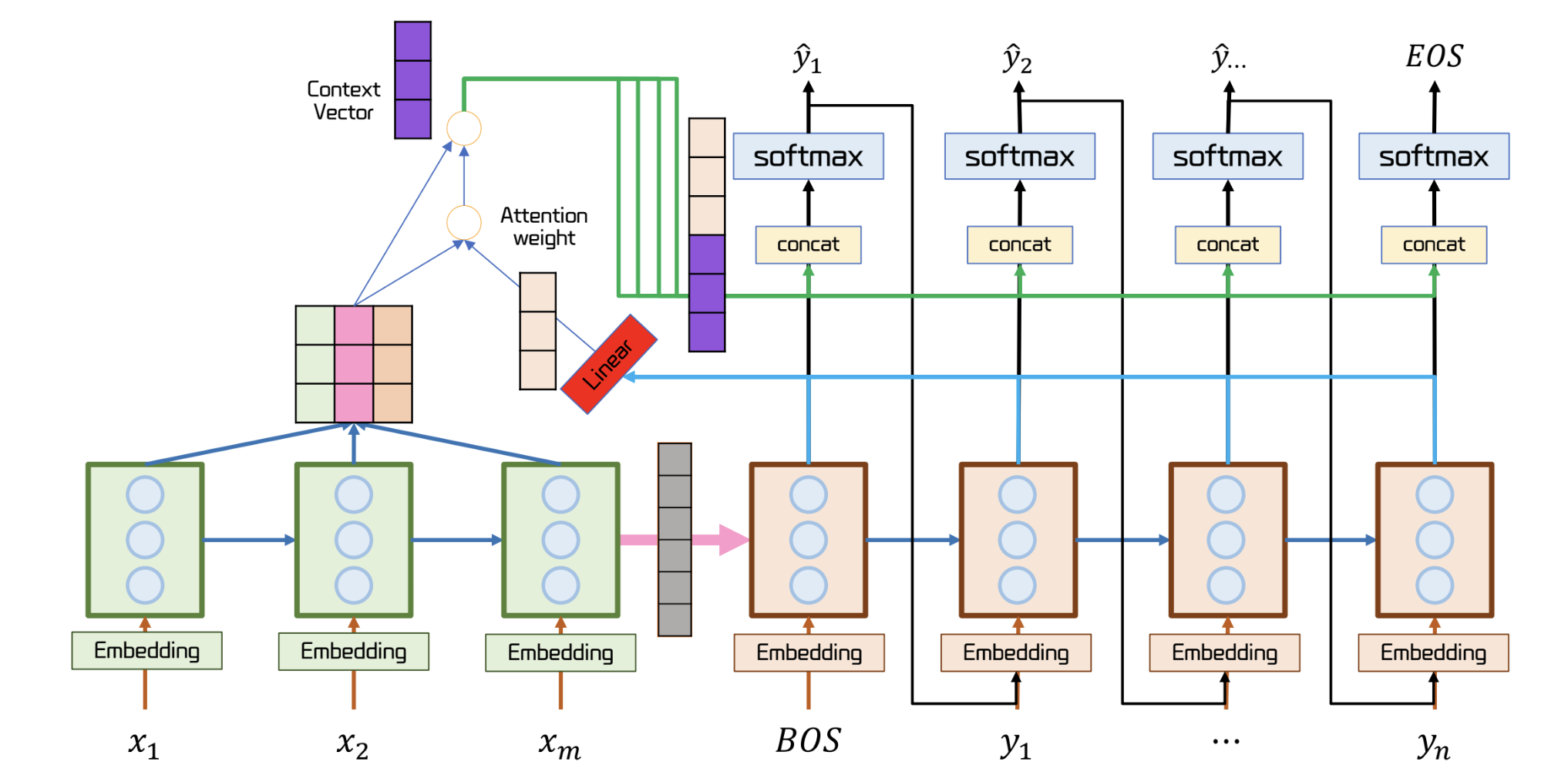
Attention 동작 과정
- query 와 key 의 내적 결과에 softmax 를 적용해 유사도를 도출할 수 있다.
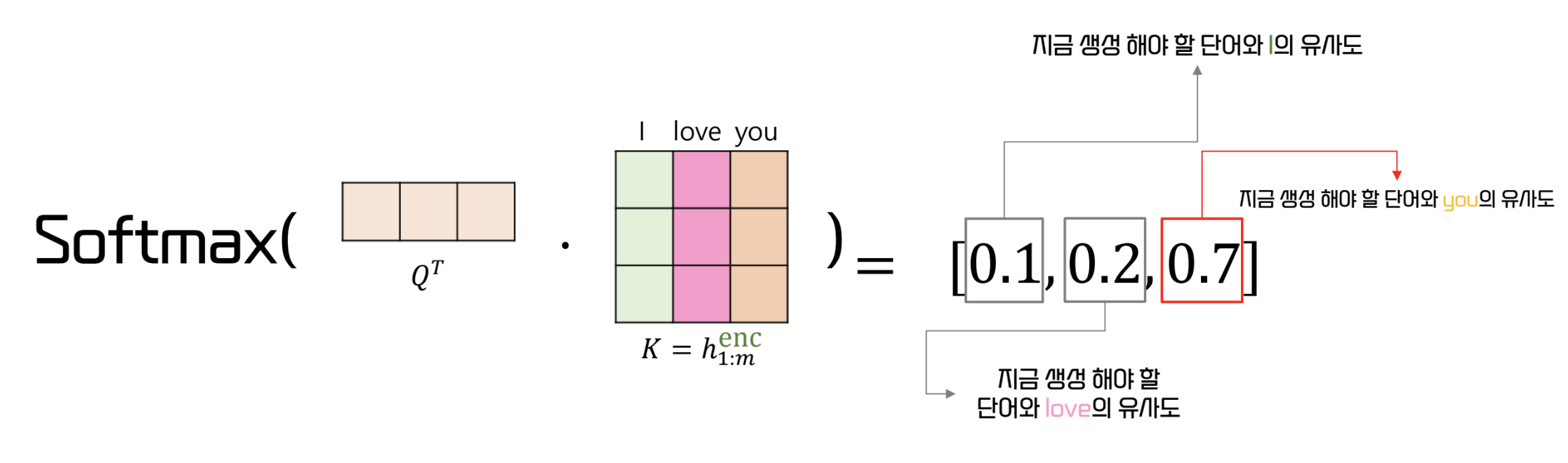
- 위와 같은 유사도를 energy 라고 한다
- 이렇게 얻어낸 energy 와 value 의 가중합 연산을 수행
- 각 요소의 중요도를 반영하기 위함이다
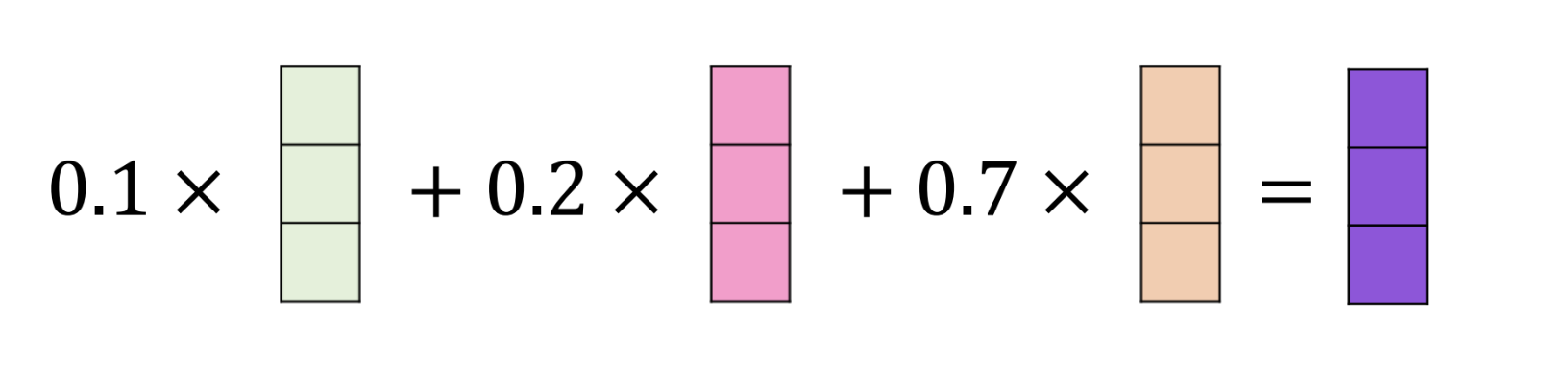
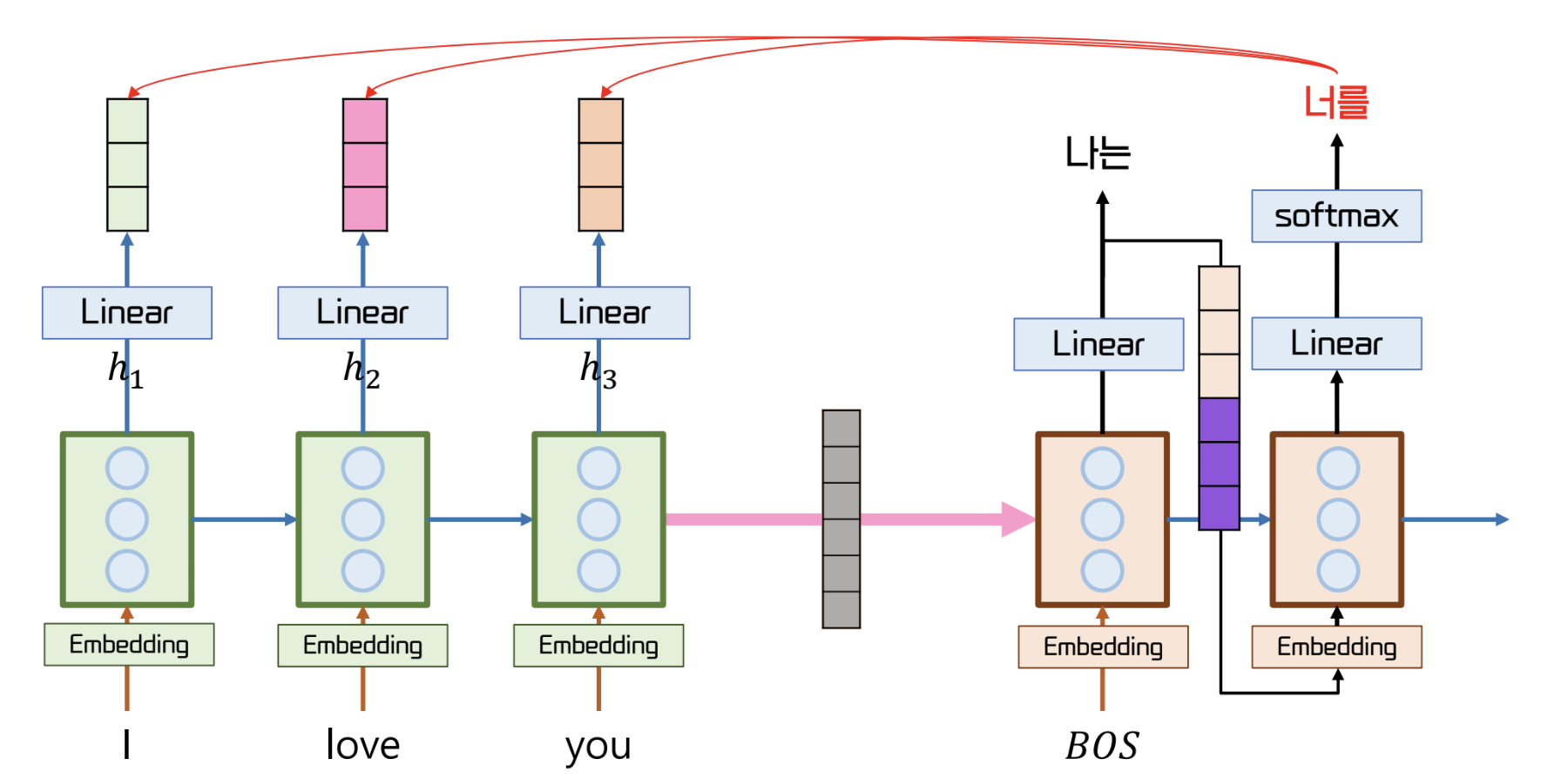
- 결과로 얻어낸 보라색 벡터는 [I, love, you] 중 you 의 특징을 가장 많이 담은 벡터
- 이 결과 벡터를 decoder 의 hidden state 에 concat 한다
Linear Transform
- Attention 은 query 와 가장 유사한 단어를 찾기 위해 linear transform 을 학습
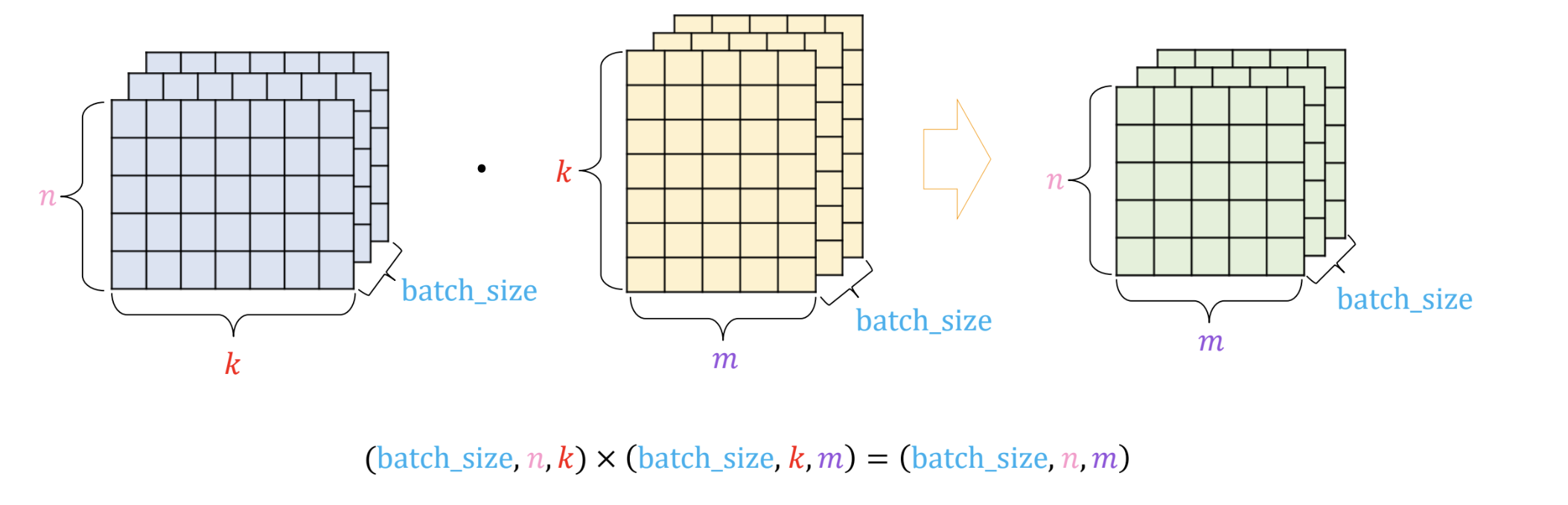
BMM (Batch Matrix Multiplication)
- 3차원 tensor 에 대한 내적을 수행하는 함수
Attention 의 수식
- energy 를 구하기 위한 수식은 다음과 같다
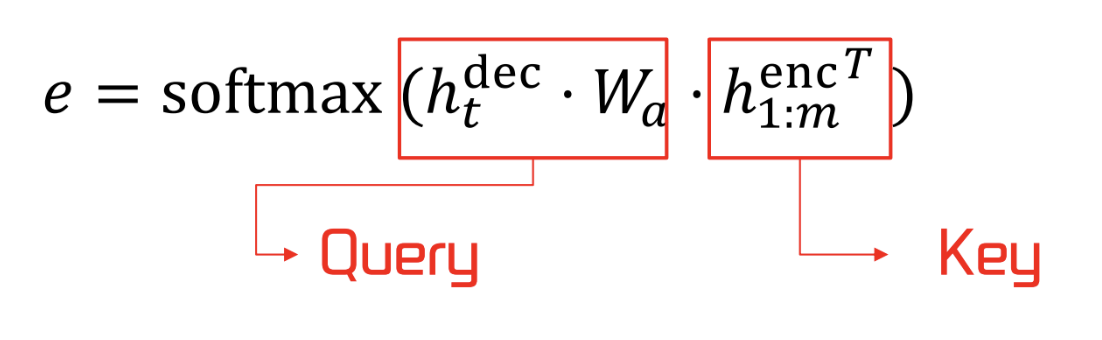
- 는 Linear Transform
- 각 요소의 tensor 구조를 살펴보자
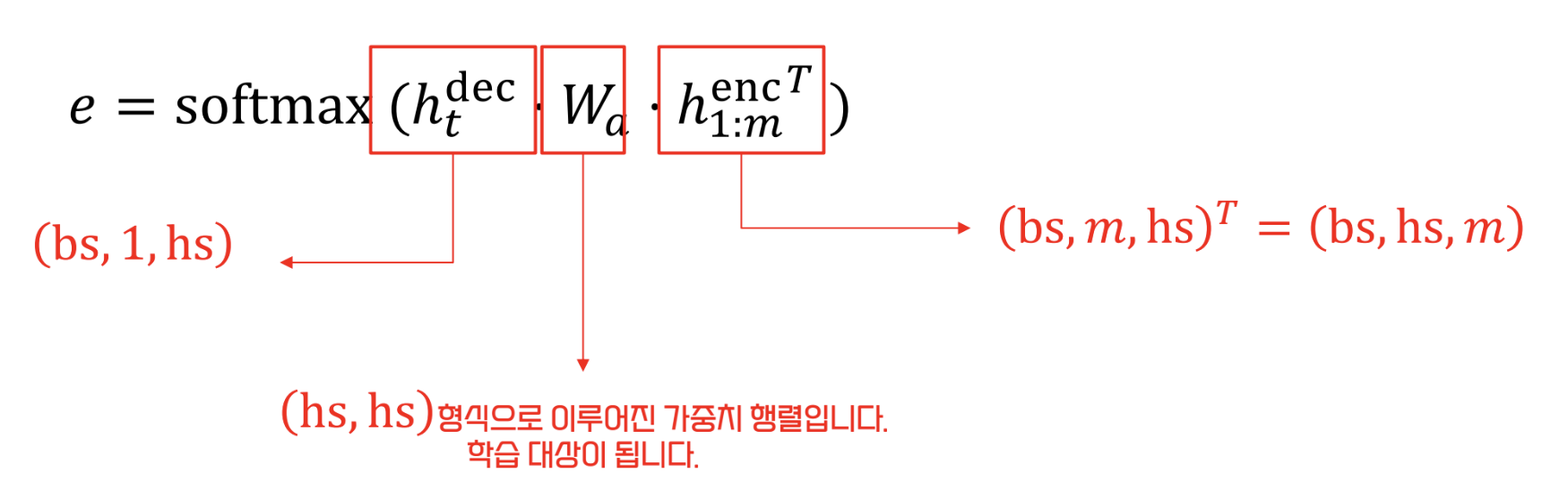
- 내적의 편의성을 위해 key 의 transpose 이용
Seq2Seq 기반 Attention 의 전체 구조
- 파란 선이 query
Masking
Padding
- 문장의 길이가 각각 다르기 때문에 이를 맞춰주기 위해 padding 을 이용
- 이는 문장들을 batch 로 처리하기 위해 필요하다
- encoder 는 pre-padding, decoder 는 post padding 이 유리하다
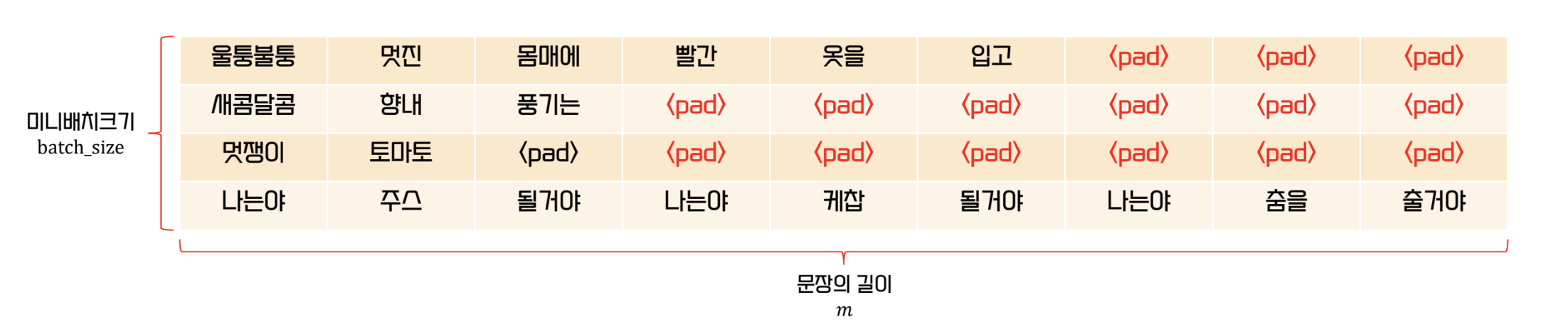
- 이때 padding 은 사용하지 않는 데이터여야 한다.
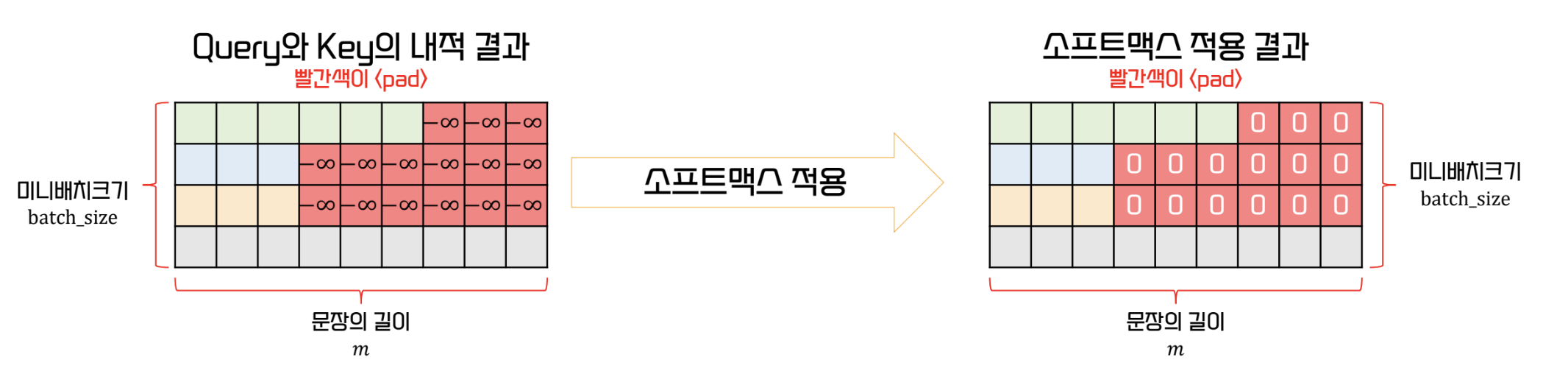
- 하지만, 이를 그냥 놔두면 padding 과의 attention score 를 구하게 되는 경우가 있다.
- 이를 방지하기 위해 masking 을 이용한다
Masking
- 원래 padding 이 있었던 위치를 기억해 attention 연산 후 해당 위치의 값을 0으로 바꾸는 것
- softmax 적용 전에 query 와 key 의 내적 결과 값을 로 설정하면 softmax 후 0이 된다
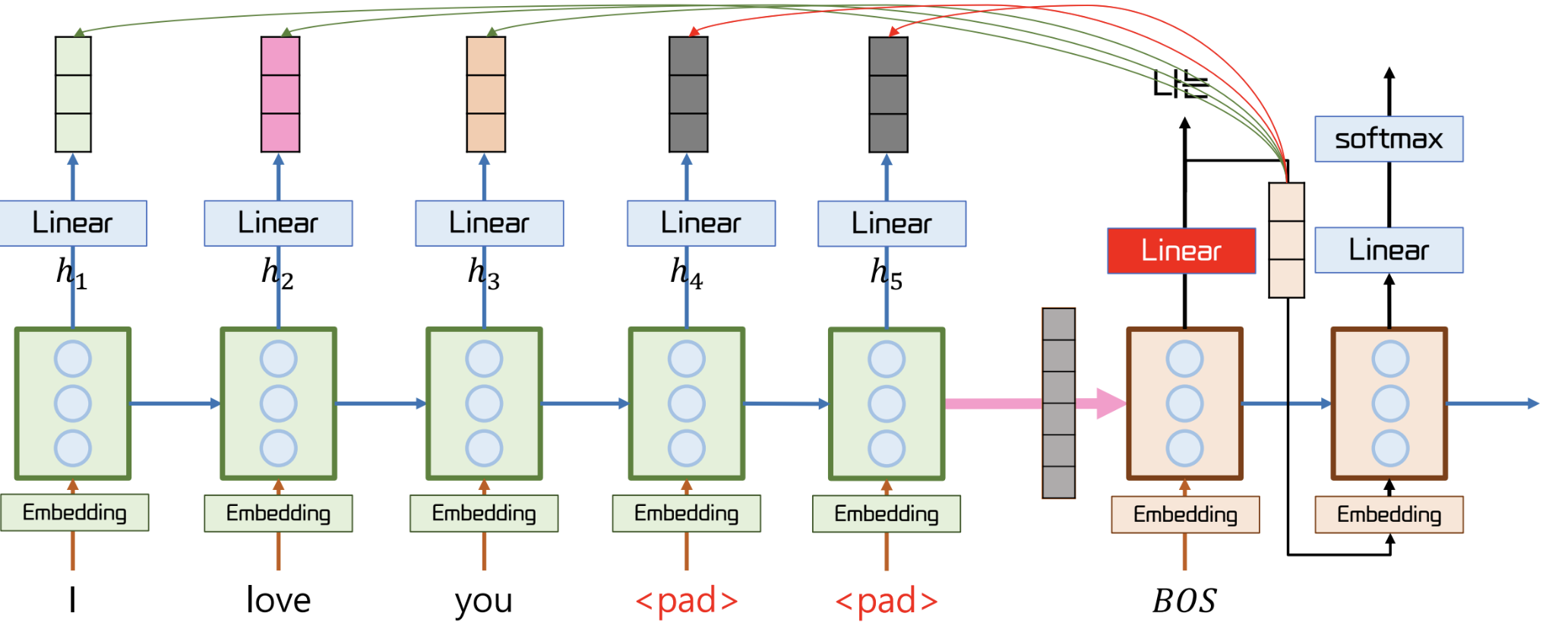
Input Feeding
- Generator 의 output 은 softmax 를 거친 확률 값이다.
- 이 확률 값을 기반으로 다음 cell 에 들어갈 Input 즉, 다음 단어가 결정된다.
- 이때, 다음 Input 은 확률 값이 아닌 one hot vector 이다.
- 그렇기 때문에, 위 그림의 오른쪽처럼 더 확실한 확률 값이 존재하는 경우를 반영하지 못한다.
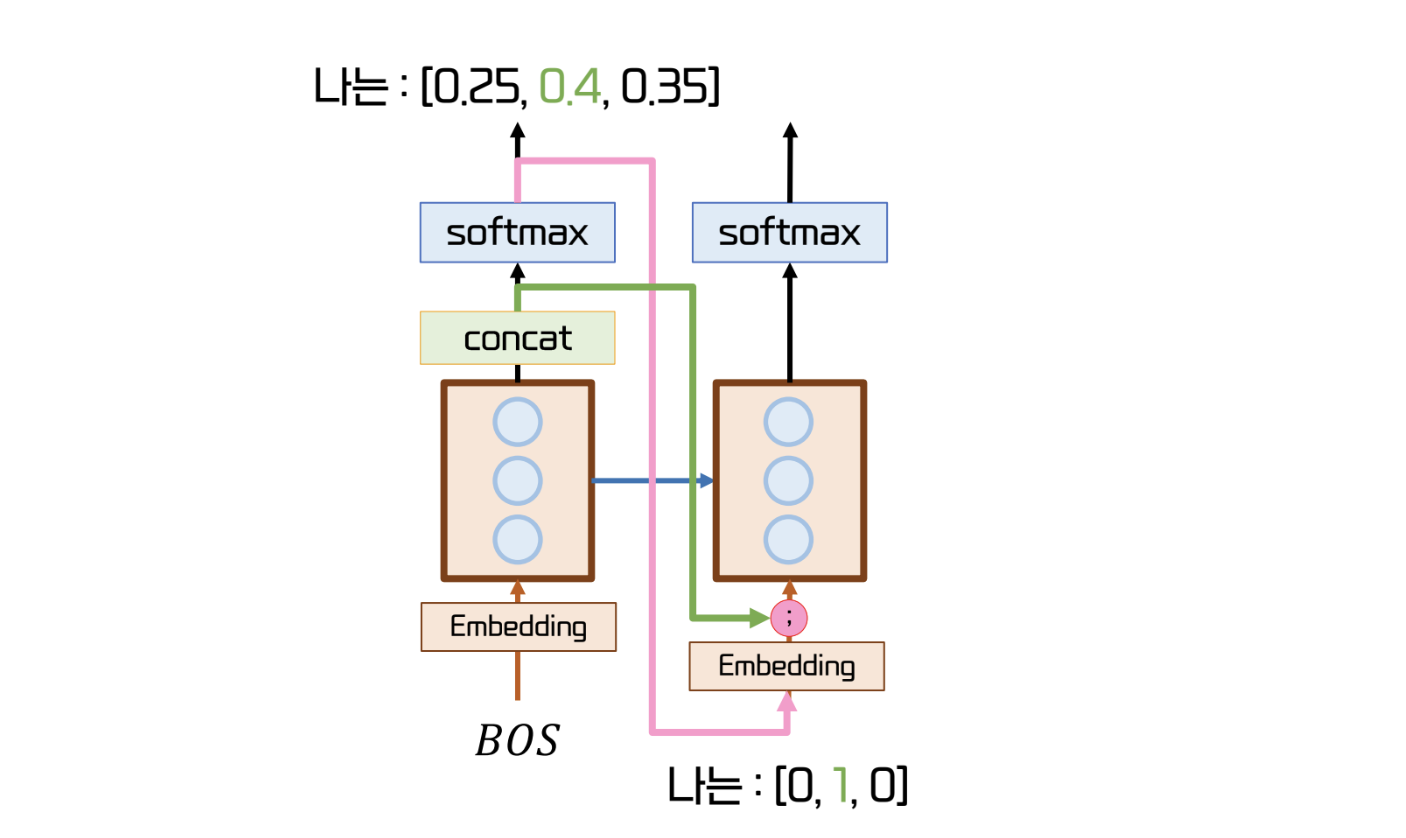
- 위와 같은 상황을 반영하기 위해, softmax 의 결과물을 concat 해 넘겨주는 Input feeding 이 등장
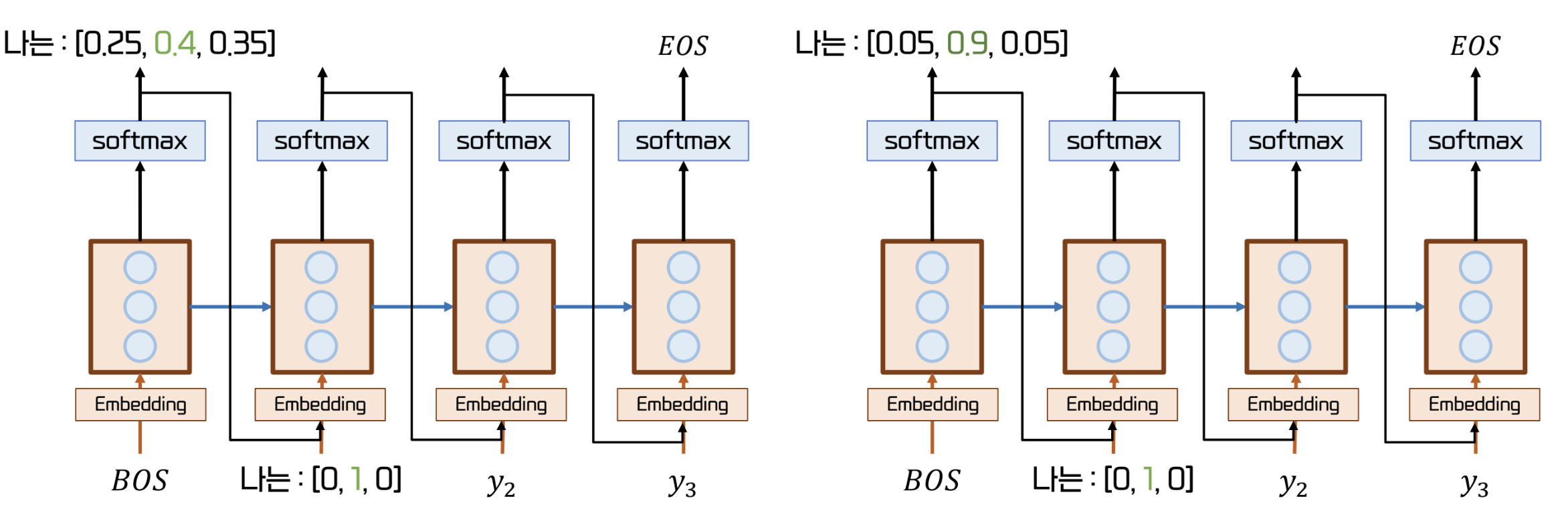
Teacher Forcing
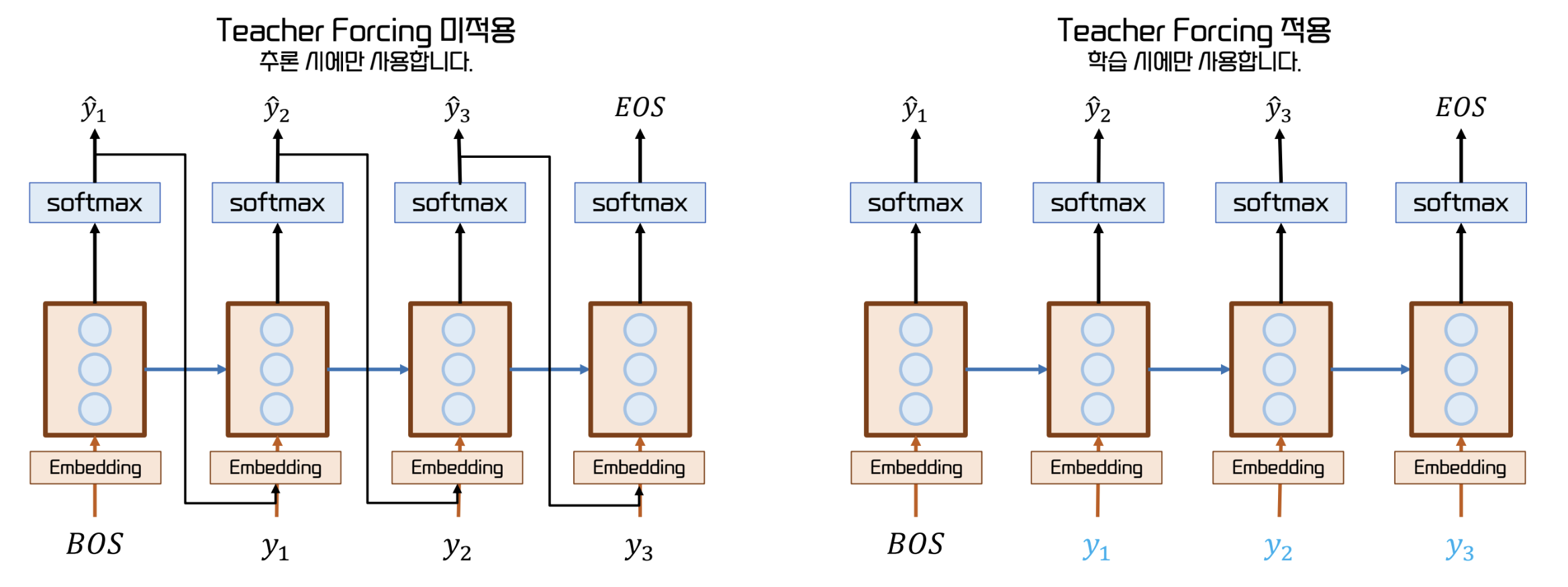
- 모델의 pred 에 상관없이 다음으로 무조건 와야 하는 단어를 제시하는 방법
- 잘못된 예측의 영향을 받지 않고 빠르고 안정적인 학습이 가능하다.
- 단, 이는 train step 에서만 적용되어야 한다.

인하대학교 컴퓨터공학과